 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStemGen: A music generation model that listens
Dec 14, 2023

End-to-end generation of musical audio using deep learning techniques has seen an explosion of activity recently. However, most models concentrate on generating fully mixed music in response to abstract conditioning information. In this work, we present an alternative paradigm for producing music generation models that can listen and respond to musical context. We describe how such a model can be constructed using a non-autoregressive, transformer-based model architecture and present a number of novel architectural and sampling improvements. We train the described architecture on both an open-source and a proprietary dataset. We evaluate the produced models using standard quality metrics and a new approach based on music information retrieval descriptors. The resulting model reaches the audio quality of state-of-the-art text-conditioned models, as well as exhibiting strong musical coherence with its context.
Differentiable Wavetable Synthesis
Nov 23, 2021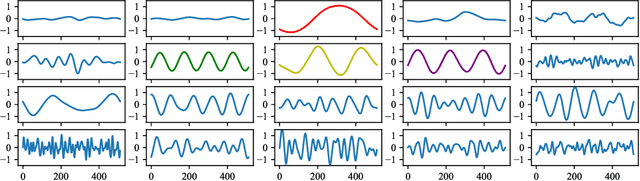

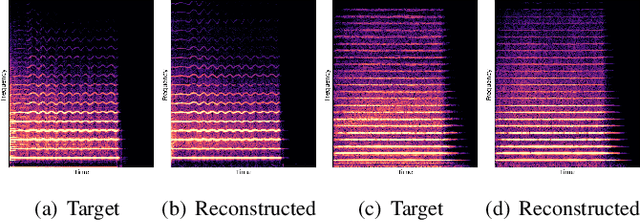
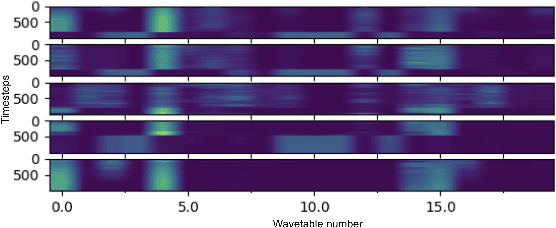
Differentiable Wavetable Synthesis (DWTS) is a technique for neural audio synthesis which learns a dictionary of one-period waveforms i.e. wavetables, through end-to-end training. We achieve high-fidelity audio synthesis with as little as 10 to 20 wavetables and demonstrate how a data-driven dictionary of waveforms opens up unprecedented one-shot learning paradigms on short audio clips. Notably, we show audio manipulations, such as high quality pitch-shifting, using only a few seconds of input audio. Lastly, we investigate performance gains from using learned wavetables for realtime and interactive audio synthesis.