 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymPAC: Scalable Symbolic Music Generation With Prompts And Constraints
Paper and Code
Sep 04, 2024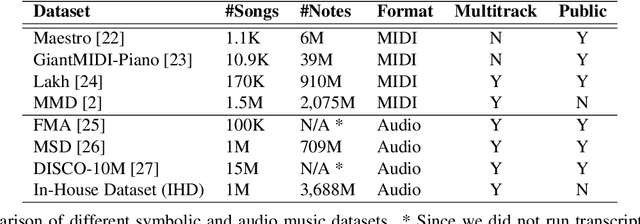


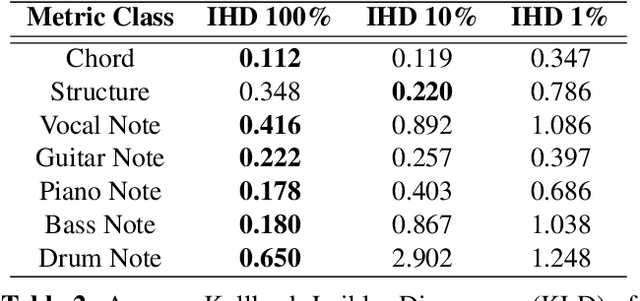
Progress in the task of symbolic music generation may be lagging behind other tasks like audio and text generation, in part because of the scarcity of symbolic training data. In this paper, we leverage the greater scale of audio music data by applying pre-trained MIR models (for transcription, beat tracking, structure analysis, etc.) to extract symbolic events and encode them into token sequences. To the best of our knowledge, this work is the first to demonstrate the feasibility of training symbolic generation models solely from auto-transcribed audio data. Furthermore, to enhance the controllability of the trained model, we introduce SymPAC (Symbolic Music Language Model with Prompting And Constrained Generation), which is distinguished by using (a) prompt bars in encoding and (b) a technique called Constrained Generation via Finite State Machines (FSMs) during inference time. We show the flexibility and controllability of this approach, which may be critical in making music AI useful to creators and users.