 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf Automotive
Oct 31, 2025We present MLPerf Automotive, the first standardized public benchmark for evaluating Machine Learning systems that are deployed for AI acceleration in automotive systems. Developed through a collaborative partnership between MLCommons and the Autonomous Vehicle Computing Consortium, this benchmark addresses the need for standardized performance evaluation methodologies in automotive machine learning systems. Existing benchmark suites cannot be utilized for these systems since automotive workloads have unique constraints including safety and real-time processing that distinguish them from the domains that previously introduced benchmarks target. Our benchmarking framework provides latency and accuracy metrics along with evaluation protocols that enable consistent and reproducible performance comparisons across different hardware platforms and software implementations. The first iteration of the benchmark consists of automotive perception tasks in 2D object detection, 2D semantic segmentation, and 3D object detection. We describe the methodology behind the benchmark design including the task selection, reference models, and submission rules. We also discuss the first round of benchmark submissions and the challenges involved in acquiring the datasets and the engineering efforts to develop the reference implementations. Our benchmark code is available at https://github.com/mlcommons/mlperf_automotive.
Regularizing Differentiable Architecture Search with Smooth Activation
Apr 22, 2025Differentiable Architecture Search (DARTS) is an efficient Neural Architecture Search (NAS) method but suffers from robustness, generalization, and discrepancy issues. Many efforts have been made towards the performance collapse issue caused by skip dominance with various regularization techniques towards operation weights, path weights, noise injection, and super-network redesign. It had become questionable at a certain point if there could exist a better and more elegant way to retract the search to its intended goal -- NAS is a selection problem. In this paper, we undertake a simple but effective approach, named Smooth Activation DARTS (SA-DARTS), to overcome skip dominance and discretization discrepancy challenges. By leveraging a smooth activation function on architecture weights as an auxiliary loss, our SA-DARTS mitigates the unfair advantage of weight-free operations, converging to fanned-out architecture weight values, and can recover the search process from skip-dominance initialization. Through theoretical and empirical analysis, we demonstrate that the SA-DARTS can yield new state-of-the-art (SOTA) results on NAS-Bench-201, classification, and super-resolution. Further, we show that SA-DARTS can help improve the performance of SOTA models with fewer parameters, such as Information Multi-distillation Network on the super-resolution task.
Hardware-Friendly Static Quantization Method for Video Diffusion Transformers
Feb 20, 2025



Diffusion Transformers for video generation have gained significant research interest since the impressive performance of SORA. Efficient deployment of such generative-AI models on GPUs has been demonstrated with dynamic quantization. However, resource-constrained devices cannot support dynamic quantization, and need static quantization of the models for their efficient deployment on AI processors. In this paper, we propose a novel method for the post-training quantization of OpenSora\cite{opensora}, a Video Diffusion Transformer, without relying on dynamic quantization techniques. Our approach employs static quantization, achieving video quality comparable to FP16 and dynamically quantized ViDiT-Q methods, as measured by CLIP, and VQA metrics. In particular, we utilize per-step calibration data to adequately provide a post-training statically quantized model for each time step, incorporating channel-wise quantization for weights and tensor-wise quantization for activations. By further applying the smooth-quantization technique, we can obtain high-quality video outputs with the statically quantized models. Extensive experimental results demonstrate that static quantization can be a viable alternative to dynamic quantization for video diffusion transformers, offering a more efficient approach without sacrificing performance.
1st Place Winner of the 2024 Pixel-level Video Understanding in the Wild Challenge in Video Panoptic Segmentation and Best Long Video Consistency of Video Semantic Segmentation
Jun 08, 2024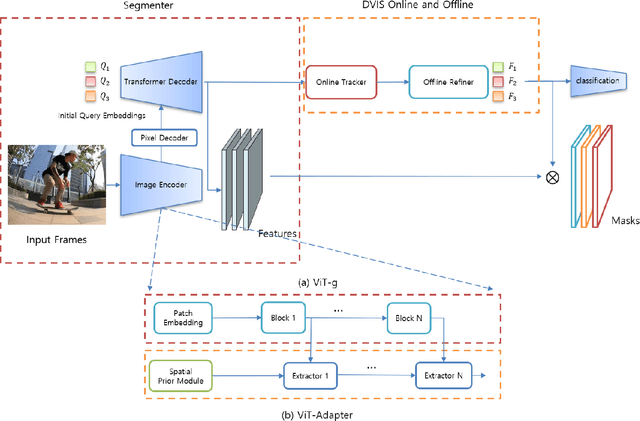
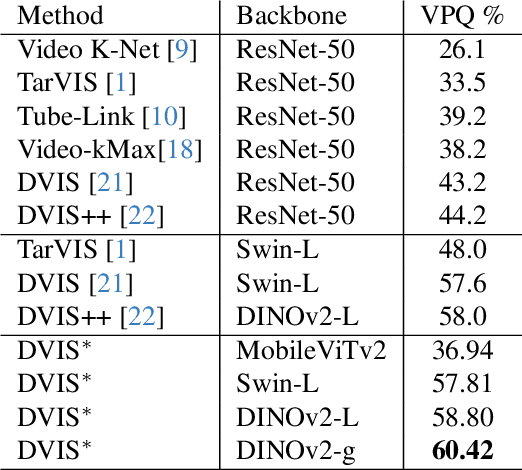
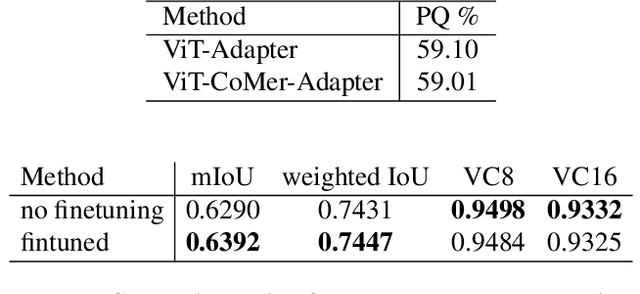

The third Pixel-level Video Understanding in the Wild (PVUW CVPR 2024) challenge aims to advance the state of art in video understanding through benchmarking Video Panoptic Segmentation (VPS) and Video Semantic Segmentation (VSS) on challenging videos and scenes introduced in the large-scale Video Panoptic Segmentation in the Wild (VIPSeg) test set and the large-scale Video Scene Parsing in the Wild (VSPW) test set, respectively. This paper details our research work that achieved the 1st place winner in the PVUW'24 VPS challenge, establishing state of art results in all metrics, including the Video Panoptic Quality (VPQ) and Segmentation and Tracking Quality (STQ). With minor fine-tuning our approach also achieved the 3rd place in the PVUW'24 VSS challenge ranked by the mIoU (mean intersection over union) metric and the first place ranked by the VC16 (16-frame video consistency) metric. Our winning solution stands on the shoulders of giant foundational vision transformer model (DINOv2 ViT-g) and proven multi-stage Decoupled Video Instance Segmentation (DVIS) frameworks for video understanding.
PPG to ECG Signal Translation for Continuous Atrial Fibrillation Detection via Attention-based Deep State-Space Modeling
Sep 27, 2023An electrocardiogram (ECG or EKG) is a medical test that measures the heart's electrical activity. ECGs are often used to diagnose and monitor a wide range of heart conditions, including arrhythmias, heart attacks, and heart failure. On the one hand, the conventional ECG requires clinical measurement, which restricts its deployment to medical facilities. On the other hand, single-lead ECG has become popular on wearable devices using administered procedures. An alternative to ECG is Photoplethysmography (PPG), which uses non-invasive, low-cost optical methods to measure cardiac physiology, making it a suitable option for capturing vital heart signs in daily life. As a result, it has become increasingly popular in health monitoring and is used in various clinical and commercial wearable devices. While ECG and PPG correlate strongly, the latter does not offer significant clinical diagnostic value. Here, we propose a subject-independent attention-based deep state-space model to translate PPG signals to corresponding ECG waveforms. The model is highly data-efficient by incorporating prior knowledge in terms of probabilistic graphical models. Notably, the model enables the detection of atrial fibrillation (AFib), the most common heart rhythm disorder in adults, by complementing ECG's accuracy with continuous PPG monitoring. We evaluated the model on 55 subjects from the MIMIC III database. Quantitative and qualitative experimental results demonstrate the effectiveness and efficiency of our approach.
SLoRA: Federated Parameter Efficient Fine-Tuning of Language Models
Aug 12, 2023



Transfer learning via fine-tuning pre-trained transformer models has gained significant success in delivering state-of-the-art results across various NLP tasks. In the absence of centralized data, Federated Learning (FL) can benefit from distributed and private data of the FL edge clients for fine-tuning. However, due to the limited communication, computation, and storage capabilities of edge devices and the huge sizes of popular transformer models, efficient fine-tuning is crucial to make federated training feasible. This work explores the opportunities and challenges associated with applying parameter efficient fine-tuning (PEFT) methods in different FL settings for language tasks. Specifically, our investigation reveals that as the data across users becomes more diverse, the gap between fully fine-tuning the model and employing PEFT methods widens. To bridge this performance gap, we propose a method called SLoRA, which overcomes the key limitations of LoRA in high heterogeneous data scenarios through a novel data-driven initialization technique. Our experimental results demonstrate that SLoRA achieves performance comparable to full fine-tuning, with significant sparse updates with approximately $\sim 1\%$ density while reducing training time by up to $90\%$.
Zero-Shot Learning of a Conditional Generative Adversarial Network for Data-Free Network Quantization
Oct 26, 2022


We propose a novel method for training a conditional generative adversarial network (CGAN) without the use of training data, called zero-shot learning of a CGAN (ZS-CGAN). Zero-shot learning of a conditional generator only needs a pre-trained discriminative (classification) model and does not need any training data. In particular, the conditional generator is trained to produce labeled synthetic samples whose characteristics mimic the original training data by using the statistics stored in the batch normalization layers of the pre-trained model. We show the usefulness of ZS-CGAN in data-free quantization of deep neural networks. We achieved the state-of-the-art data-free network quantization of the ResNet and MobileNet classification models trained on the ImageNet dataset. Data-free quantization using ZS-CGAN showed a minimal loss in accuracy compared to that obtained by conventional data-dependent quantization.
Toward Sustainable Continual Learning: Detection and Knowledge Repurposing of Similar Tasks
Oct 11, 2022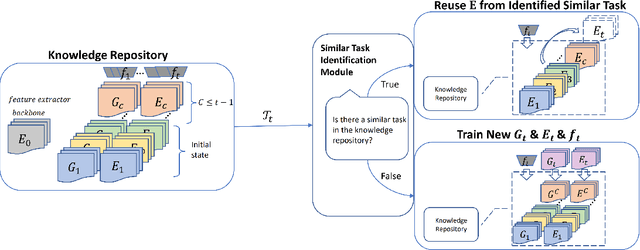

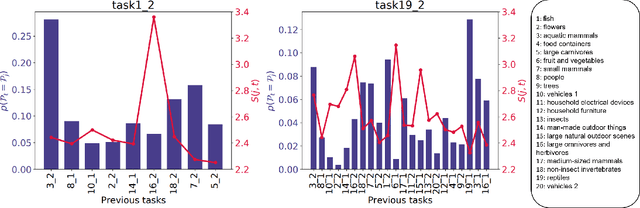
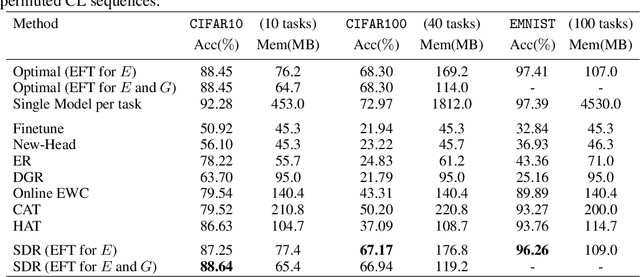
Most existing works on continual learning (CL) focus on overcoming the catastrophic forgetting (CF) problem, with dynamic models and replay methods performing exceptionally well. However, since current works tend to assume exclusivity or dissimilarity among learning tasks, these methods require constantly accumulating task-specific knowledge in memory for each task. This results in the eventual prohibitive expansion of the knowledge repository if we consider learning from a long sequence of tasks. In this work, we introduce a paradigm where the continual learner gets a sequence of mixed similar and dissimilar tasks. We propose a new continual learning framework that uses a task similarity detection function that does not require additional learning, with which we analyze whether there is a specific task in the past that is similar to the current task. We can then reuse previous task knowledge to slow down parameter expansion, ensuring that the CL system expands the knowledge repository sublinearly to the number of learned tasks. Our experiments show that the proposed framework performs competitively on widely used computer vision benchmarks such as CIFAR10, CIFAR100, and EMNIST.
Dual-Teacher Class-Incremental Learning With Data-Free Generative Replay
Jun 17, 2021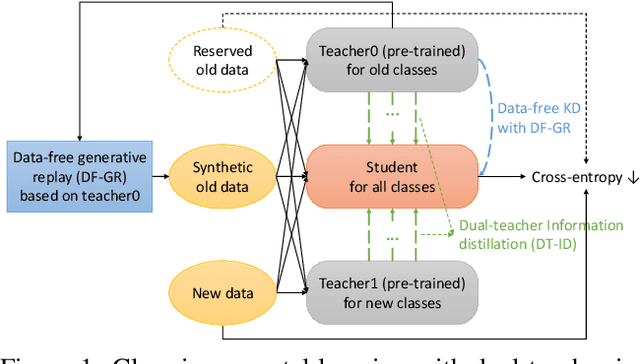

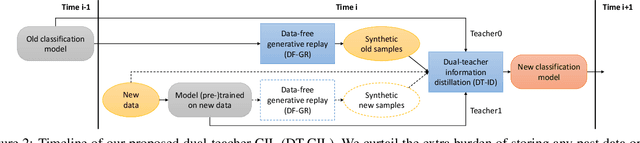

This paper proposes two novel knowledge transfer techniques for class-incremental learning (CIL). First, we propose data-free generative replay (DF-GR) to mitigate catastrophic forgetting in CIL by using synthetic samples from a generative model. In the conventional generative replay, the generative model is pre-trained for old data and shared in extra memory for later incremental learning. In our proposed DF-GR, we train a generative model from scratch without using any training data, based on the pre-trained classification model from the past, so we curtail the cost of sharing pre-trained generative models. Second, we introduce dual-teacher information distillation (DT-ID) for knowledge distillation from two teachers to one student. In CIL, we use DT-ID to learn new classes incrementally based on the pre-trained model for old classes and another model (pre-)trained on the new data for new classes. We implemented the proposed schemes on top of one of the state-of-the-art CIL methods and showed the performance improvement on CIFAR-100 and ImageNet datasets.
Towards Fair Federated Learning with Zero-Shot Data Augmentation
Apr 27, 2021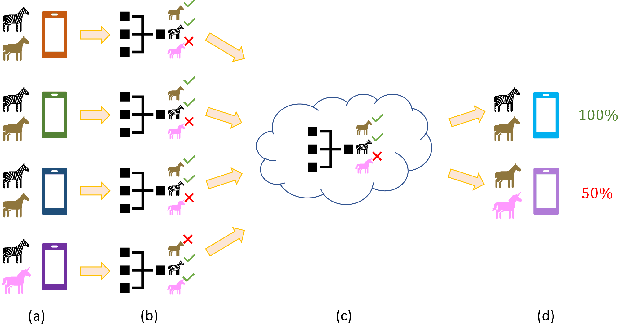
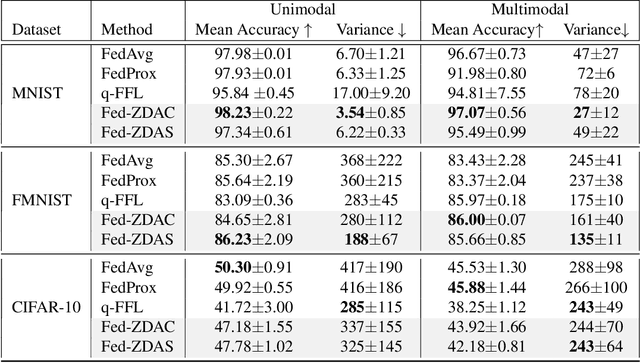
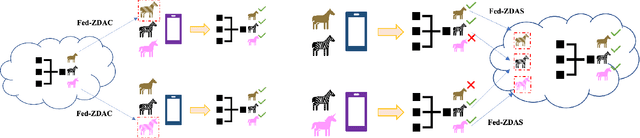
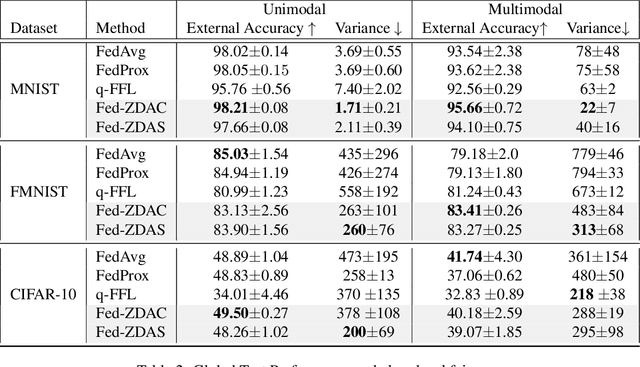
Federated learning has emerged as an important distributed learning paradigm, where a server aggregates a global model from many client-trained models while having no access to the client data. Although it is recognized that statistical heterogeneity of the client local data yields slower global model convergence, it is less commonly recognized that it also yields a biased federated global model with a high variance of accuracy across clients. In this work, we aim to provide federated learning schemes with improved fairness. To tackle this challenge, we propose a novel federated learning system that employs zero-shot data augmentation on under-represented data to mitigate statistical heterogeneity and encourage more uniform accuracy performance across clients in federated networks. We study two variants of this scheme, Fed-ZDAC (federated learning with zero-shot data augmentation at the clients) and Fed-ZDAS (federated learning with zero-shot data augmentation at the server). Empirical results on a suite of datasets demonstrate the effectiveness of our methods on simultaneously improving the test accuracy and fairness.