 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Sustainable Continual Learning: Detection and Knowledge Repurposing of Similar Tasks
Paper and Code
Oct 11, 2022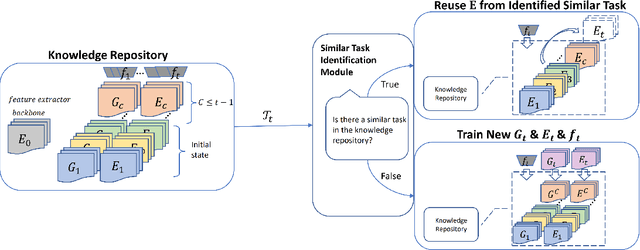

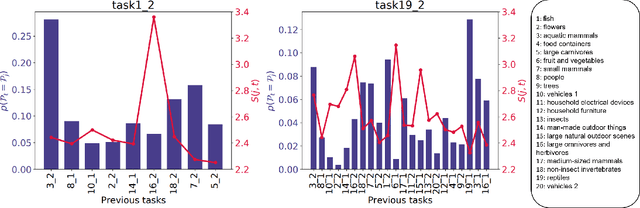
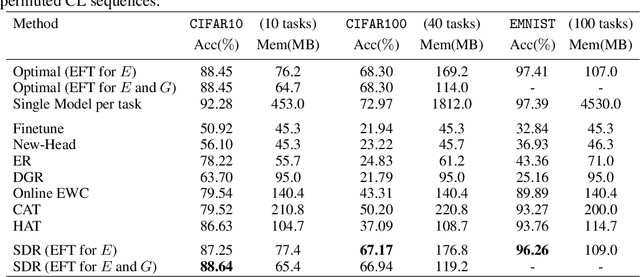
Most existing works on continual learning (CL) focus on overcoming the catastrophic forgetting (CF) problem, with dynamic models and replay methods performing exceptionally well. However, since current works tend to assume exclusivity or dissimilarity among learning tasks, these methods require constantly accumulating task-specific knowledge in memory for each task. This results in the eventual prohibitive expansion of the knowledge repository if we consider learning from a long sequence of tasks. In this work, we introduce a paradigm where the continual learner gets a sequence of mixed similar and dissimilar tasks. We propose a new continual learning framework that uses a task similarity detection function that does not require additional learning, with which we analyze whether there is a specific task in the past that is similar to the current task. We can then reuse previous task knowledge to slow down parameter expansion, ensuring that the CL system expands the knowledge repository sublinearly to the number of learned tasks. Our experiments show that the proposed framework performs competitively on widely used computer vision benchmarks such as CIFAR10, CIFAR100, and EMNIST.