 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Differentiable Architecture Search with Smooth Activation
Apr 22, 2025Differentiable Architecture Search (DARTS) is an efficient Neural Architecture Search (NAS) method but suffers from robustness, generalization, and discrepancy issues. Many efforts have been made towards the performance collapse issue caused by skip dominance with various regularization techniques towards operation weights, path weights, noise injection, and super-network redesign. It had become questionable at a certain point if there could exist a better and more elegant way to retract the search to its intended goal -- NAS is a selection problem. In this paper, we undertake a simple but effective approach, named Smooth Activation DARTS (SA-DARTS), to overcome skip dominance and discretization discrepancy challenges. By leveraging a smooth activation function on architecture weights as an auxiliary loss, our SA-DARTS mitigates the unfair advantage of weight-free operations, converging to fanned-out architecture weight values, and can recover the search process from skip-dominance initialization. Through theoretical and empirical analysis, we demonstrate that the SA-DARTS can yield new state-of-the-art (SOTA) results on NAS-Bench-201, classification, and super-resolution. Further, we show that SA-DARTS can help improve the performance of SOTA models with fewer parameters, such as Information Multi-distillation Network on the super-resolution task.
UniHands: Unifying Various Wild-Collected Keypoints for Personalized Hand Reconstruction
Nov 18, 2024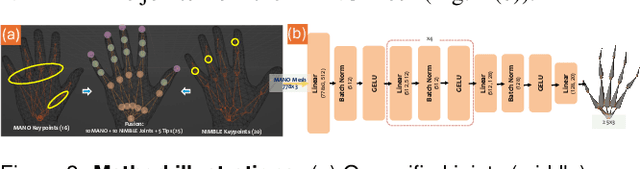
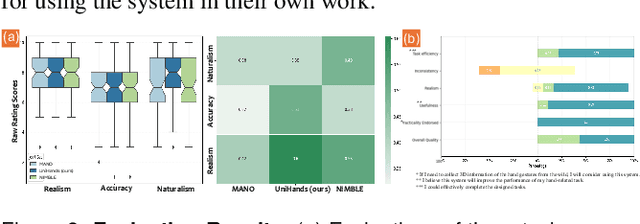
Accurate hand motion capture and standardized 3D representation are essential for various hand-related tasks. Collecting keypoints-only data, while efficient and cost-effective, results in low-fidelity representations and lacks surface information. Furthermore, data inconsistencies across sources challenge their integration and use. We present UniHands, a novel method for creating standardized yet personalized hand models from wild-collected keypoints from diverse sources. Unlike existing neural implicit representation methods, UniHands uses the widely-adopted parametric models MANO and NIMBLE, providing a more scalable and versatile solution. It also derives unified hand joints from the meshes, which facilitates seamless integration into various hand-related tasks. Experiments on the FreiHAND and InterHand2.6M datasets demonstrate its ability to precisely reconstruct hand mesh vertices and keypoints, effectively capturing high-degree articulation motions. Empirical studies involving nine participants show a clear preference for our unified joints over existing configurations for accuracy and naturalism (p-value 0.016).
1st Place Winner of the 2024 Pixel-level Video Understanding in the Wild Challenge in Video Panoptic Segmentation and Best Long Video Consistency of Video Semantic Segmentation
Jun 08, 2024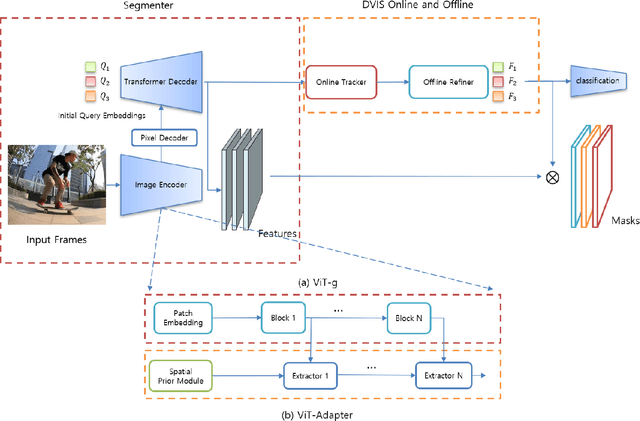
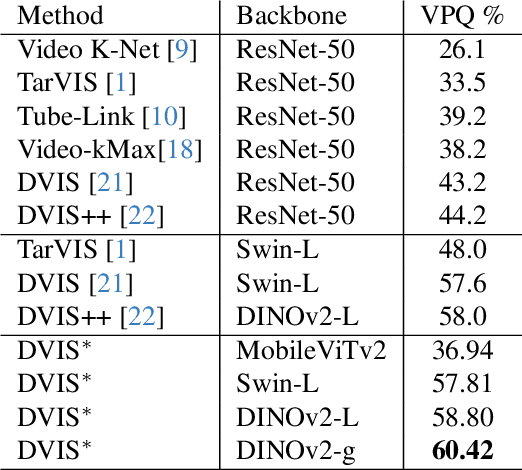
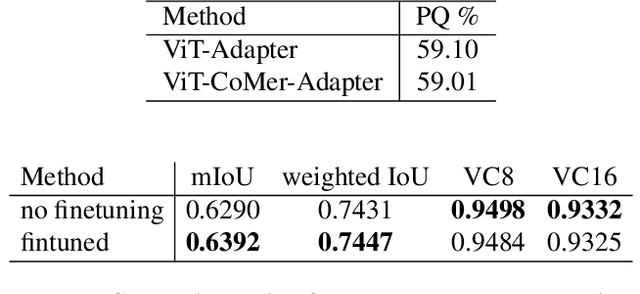

The third Pixel-level Video Understanding in the Wild (PVUW CVPR 2024) challenge aims to advance the state of art in video understanding through benchmarking Video Panoptic Segmentation (VPS) and Video Semantic Segmentation (VSS) on challenging videos and scenes introduced in the large-scale Video Panoptic Segmentation in the Wild (VIPSeg) test set and the large-scale Video Scene Parsing in the Wild (VSPW) test set, respectively. This paper details our research work that achieved the 1st place winner in the PVUW'24 VPS challenge, establishing state of art results in all metrics, including the Video Panoptic Quality (VPQ) and Segmentation and Tracking Quality (STQ). With minor fine-tuning our approach also achieved the 3rd place in the PVUW'24 VSS challenge ranked by the mIoU (mean intersection over union) metric and the first place ranked by the VC16 (16-frame video consistency) metric. Our winning solution stands on the shoulders of giant foundational vision transformer model (DINOv2 ViT-g) and proven multi-stage Decoupled Video Instance Segmentation (DVIS) frameworks for video understanding.
SLoRA: Federated Parameter Efficient Fine-Tuning of Language Models
Aug 12, 2023



Transfer learning via fine-tuning pre-trained transformer models has gained significant success in delivering state-of-the-art results across various NLP tasks. In the absence of centralized data, Federated Learning (FL) can benefit from distributed and private data of the FL edge clients for fine-tuning. However, due to the limited communication, computation, and storage capabilities of edge devices and the huge sizes of popular transformer models, efficient fine-tuning is crucial to make federated training feasible. This work explores the opportunities and challenges associated with applying parameter efficient fine-tuning (PEFT) methods in different FL settings for language tasks. Specifically, our investigation reveals that as the data across users becomes more diverse, the gap between fully fine-tuning the model and employing PEFT methods widens. To bridge this performance gap, we propose a method called SLoRA, which overcomes the key limitations of LoRA in high heterogeneous data scenarios through a novel data-driven initialization technique. Our experimental results demonstrate that SLoRA achieves performance comparable to full fine-tuning, with significant sparse updates with approximately $\sim 1\%$ density while reducing training time by up to $90\%$.
Explicit Calibration of mmWave Phased Arrays with Phase Dependent Errors
Jul 16, 2021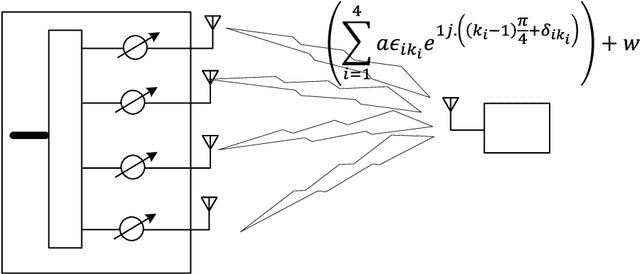
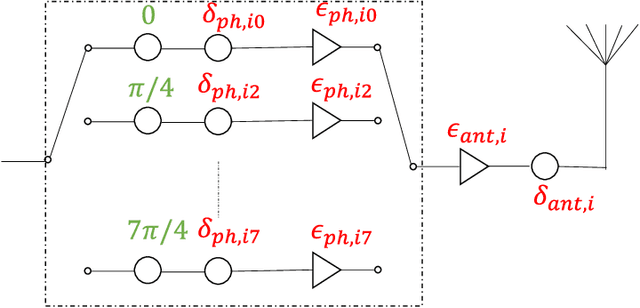
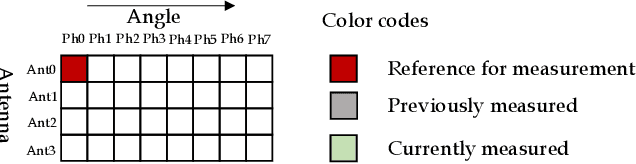
We consider an error model for phased array with gain errors and phase errors, with errors dependent on the phase applied and the antenna index. Under this model, we propose an algorithm for measuring the errors by selectively turning on the antennas at specific phases and measuring the transmitted power. In our algorithm, the antennas are turned on individually and then pairwise for the measurements, and rotation of the phased array is not required. We give numerical results to measure the accuracy of the algorithm as a function of the signal-to-noise ratio in the measurement setup. We also compare the performance of our algorithm with the traditional rotating electric vector (REV) method and observe the superiority of our algorithm. Simulations also demonstrate an improvement in the coverage on comparing the cumulative distribution function (CDF) of equivalent isotropically radiated power (EIRP) before and after calibration.
Reliable and Low-Complexity MIMO Detector Selection using Neural Network
Oct 11, 2019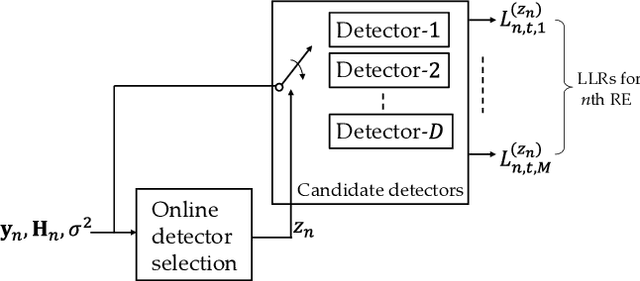
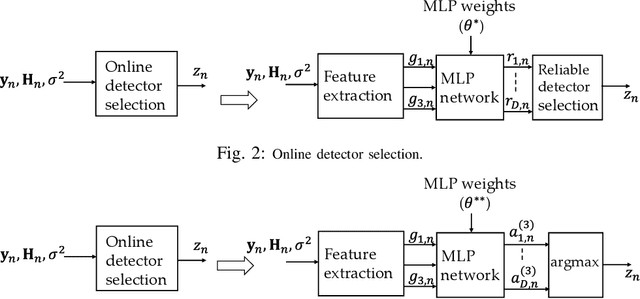
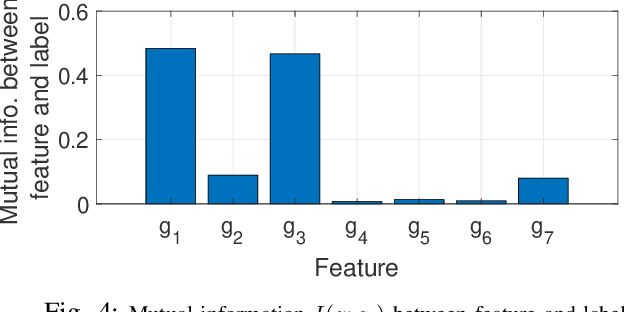
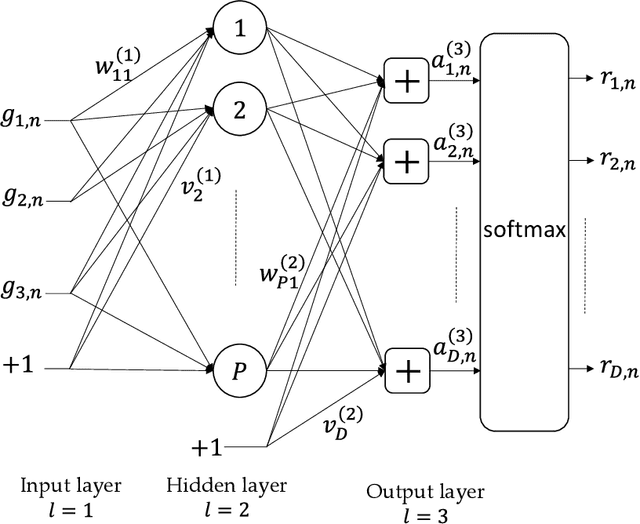
In this paper, we propose to dynamically select a MIMO detector using neural network for each resource element (RE) in the transport block of 5G NR/LTE communication system. The objective is to minimize the computational complexity of MIMO detection while keeping the transport block error rate (BLER) close to the BLER when dimension-reduced maximum-likelihood (DR-ML) detection is used. A detector selection problem is formulated to achieve this objective. However, since the problem is high dimensional and NP-hard, we first decompose the problem into smaller problems and train a multi-layer perceptron (MLP) network to obtain the solution. The MLP network is trained to select a low-complexity, yet reliable, detector using instantaneous channel condition in the RE. We first propose a method to generate a labeled dataset to select a low-complexity detector. Then, the MLP is trained twice using quasi-Newton method to select a reliable detector for each RE. The performance of online detector selection is evaluated in 5G NR link level simulator in terms of BLER and the complexity is quantified in terms of the number of Euclidean distance (ED) computations and the number of real additions and multiplication. Results show that the computational complexity in the MIMO detector can be reduced by ~10X using the proposed method.