 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering and Median Aggregation Improve Differentially Private Inference
Jun 05, 2025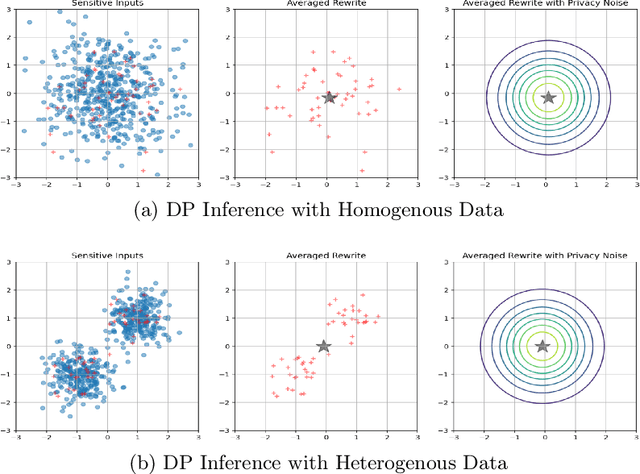

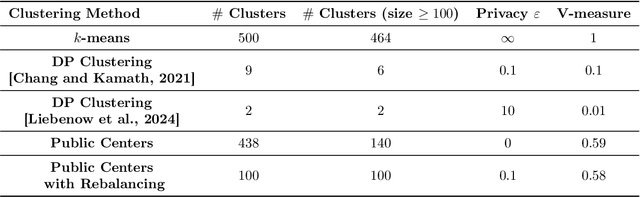
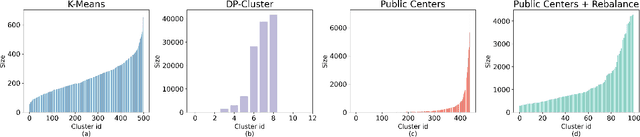
Differentially private (DP) language model inference is an approach for generating private synthetic text. A sensitive input example is used to prompt an off-the-shelf large language model (LLM) to produce a similar example. Multiple examples can be aggregated together to formally satisfy the DP guarantee. Prior work creates inference batches by sampling sensitive inputs uniformly at random. We show that uniform sampling degrades the quality of privately generated text, especially when the sensitive examples concern heterogeneous topics. We remedy this problem by clustering the input data before selecting inference batches. Next, we observe that clustering also leads to more similar next-token predictions across inferences. We use this insight to introduce a new algorithm that aggregates next token statistics by privately computing medians instead of averages. This approach leverages the fact that the median has decreased local sensitivity when next token predictions are similar, allowing us to state a data-dependent and ex-post DP guarantee about the privacy properties of this algorithm. Finally, we demonstrate improvements in terms of representativeness metrics (e.g., MAUVE) as well as downstream task performance. We show that our method produces high-quality synthetic data at significantly lower privacy cost than a previous state-of-the-art method.
Escaping Collapse: The Strength of Weak Data for Large Language Model Training
Feb 13, 2025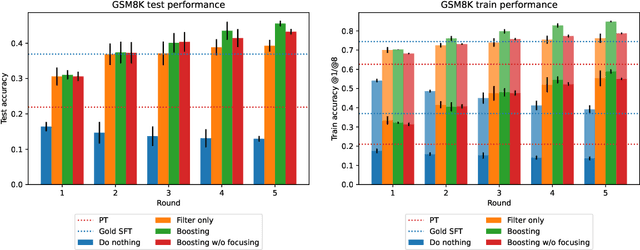
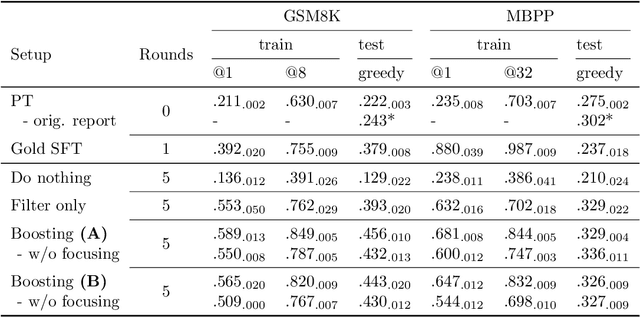
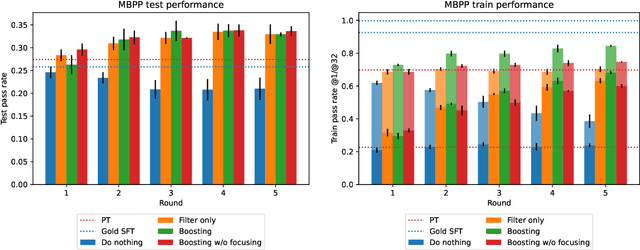
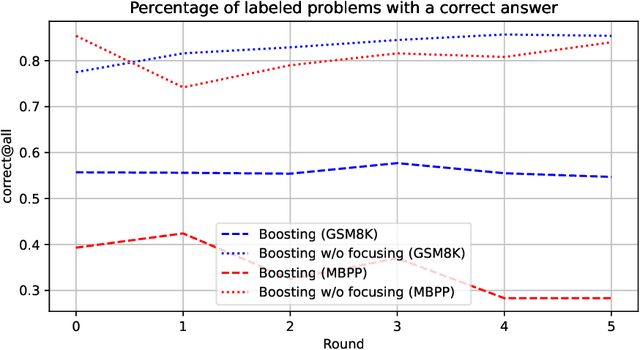
Synthetically-generated data plays an increasingly larger role in training large language models. However, while synthetic data has been found to be useful, studies have also shown that without proper curation it can cause LLM performance to plateau, or even "collapse", after many training iterations. In this paper, we formalize this question and develop a theoretical framework to investigate how much curation is needed in order to ensure that LLM performance continually improves. We find that the requirements are nearly minimal. We describe a training procedure that converges to an optimal LLM even if almost all of the non-synthetic training data is of poor quality. Our analysis is inspired by boosting, a classic machine learning technique that leverages a very weak learning algorithm to produce an arbitrarily good classifier. Our training procedure subsumes many recently proposed methods for training LLMs on synthetic data, and thus our analysis sheds light on why they are successful, and also suggests opportunities for future improvement. We present experiments that validate our theory, and show that dynamically focusing labeling resources on the most challenging examples -- in much the same way that boosting focuses the efforts of the weak learner -- leads to improved performance.
Supervised Learning for Analog and RF Circuit Design: Benchmarks and Comparative Insights
Jan 21, 2025Automating analog and radio-frequency (RF) circuit design using machine learning (ML) significantly reduces the time and effort required for parameter optimization. This study explores supervised ML-based approaches for designing circuit parameters from performance specifications across various circuit types, including homogeneous and heterogeneous designs. By evaluating diverse ML models, from neural networks like transformers to traditional methods like random forests, we identify the best-performing models for each circuit. Our results show that simpler circuits, such as low-noise amplifiers, achieve exceptional accuracy with mean relative errors as low as 0.3% due to their linear parameter-performance relationships. In contrast, complex circuits, like power amplifiers and voltage-controlled oscillators, present challenges due to their non-linear interactions and larger design spaces. For heterogeneous circuits, our approach achieves an 88% reduction in errors with increased training data, with the receiver achieving a mean relative error as low as 0.23%, showcasing the scalability and accuracy of the proposed methodology. Additionally, we provide insights into model strengths, with transformers excelling in capturing non-linear mappings and k-nearest neighbors performing robustly in moderately linear parameter spaces, especially in heterogeneous circuits with larger datasets. This work establishes a foundation for extending ML-driven design automation, enabling more efficient and scalable circuit design workflows.
AICircuit: A Multi-Level Dataset and Benchmark for AI-Driven Analog Integrated Circuit Design
Jul 22, 2024Analog and radio-frequency circuit design requires extensive exploration of both circuit topology and parameters to meet specific design criteria like power consumption and bandwidth. Designers must review state-of-the-art topology configurations in the literature and sweep various circuit parameters within each configuration. This design process is highly specialized and time-intensive, particularly as the number of circuit parameters increases and the circuit becomes more complex. Prior research has explored the potential of machine learning to enhance circuit design procedures. However, these studies primarily focus on simple circuits, overlooking the more practical and complex analog and radio-frequency systems. A major obstacle for bearing the power of machine learning in circuit design is the availability of a generic and diverse dataset, along with robust metrics, which are essential for thoroughly evaluating and improving machine learning algorithms in the analog and radio-frequency circuit domain. We present AICircuit, a comprehensive multi-level dataset and benchmark for developing and evaluating ML algorithms in analog and radio-frequency circuit design. AICircuit comprises seven commonly used basic circuits and two complex wireless transceiver systems composed of multiple circuit blocks, encompassing a wide array of design scenarios encountered in real-world applications. We extensively evaluate various ML algorithms on the dataset, revealing the potential of ML algorithms in learning the mapping from the design specifications to the desired circuit parameters.
A Data-Free Approach to Mitigate Catastrophic Forgetting in Federated Class Incremental Learning for Vision Tasks
Nov 21, 2023



Deep learning models often suffer from forgetting previously learned information when trained on new data. This problem is exacerbated in federated learning (FL), where the data is distributed and can change independently for each user. Many solutions are proposed to resolve this catastrophic forgetting in a centralized setting. However, they do not apply directly to FL because of its unique complexities, such as privacy concerns and resource limitations. To overcome these challenges, this paper presents a framework for $\textbf{federated class incremental learning}$ that utilizes a generative model to synthesize samples from past distributions. This data can be later exploited alongside the training data to mitigate catastrophic forgetting. To preserve privacy, the generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Moreover, our solution does not demand the users to store old data or models, which gives them the freedom to join/leave the training at any time. Additionally, we introduce SuperImageNet, a new regrouping of the ImageNet dataset specifically tailored for federated continual learning. We demonstrate significant improvements compared to existing baselines through extensive experiments on multiple datasets.
SLoRA: Federated Parameter Efficient Fine-Tuning of Language Models
Aug 12, 2023



Transfer learning via fine-tuning pre-trained transformer models has gained significant success in delivering state-of-the-art results across various NLP tasks. In the absence of centralized data, Federated Learning (FL) can benefit from distributed and private data of the FL edge clients for fine-tuning. However, due to the limited communication, computation, and storage capabilities of edge devices and the huge sizes of popular transformer models, efficient fine-tuning is crucial to make federated training feasible. This work explores the opportunities and challenges associated with applying parameter efficient fine-tuning (PEFT) methods in different FL settings for language tasks. Specifically, our investigation reveals that as the data across users becomes more diverse, the gap between fully fine-tuning the model and employing PEFT methods widens. To bridge this performance gap, we propose a method called SLoRA, which overcomes the key limitations of LoRA in high heterogeneous data scenarios through a novel data-driven initialization technique. Our experimental results demonstrate that SLoRA achieves performance comparable to full fine-tuning, with significant sparse updates with approximately $\sim 1\%$ density while reducing training time by up to $90\%$.
Don't Memorize; Mimic The Past: Federated Class Incremental Learning Without Episodic Memory
Jul 17, 2023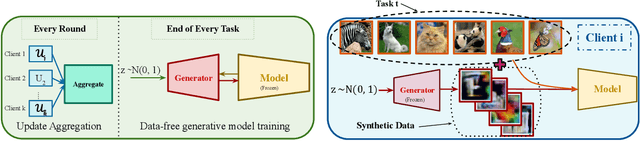



Deep learning models are prone to forgetting information learned in the past when trained on new data. This problem becomes even more pronounced in the context of federated learning (FL), where data is decentralized and subject to independent changes for each user. Continual Learning (CL) studies this so-called \textit{catastrophic forgetting} phenomenon primarily in centralized settings, where the learner has direct access to the complete training dataset. However, applying CL techniques to FL is not straightforward due to privacy concerns and resource limitations. This paper presents a framework for federated class incremental learning that utilizes a generative model to synthesize samples from past distributions instead of storing part of past data. Then, clients can leverage the generative model to mitigate catastrophic forgetting locally. The generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Therefore, it reduces the risk of data leakage as opposed to training it on the client's private data. We demonstrate significant improvements for the CIFAR-100 dataset compared to existing baselines.
Federated Sparse Training: Lottery Aware Model Compression for Resource Constrained Edge
Aug 27, 2022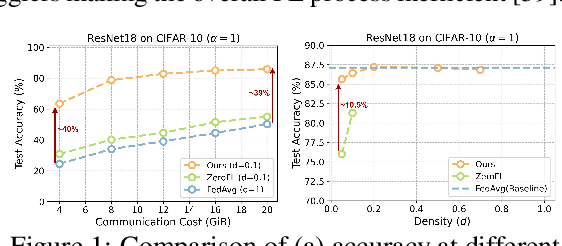


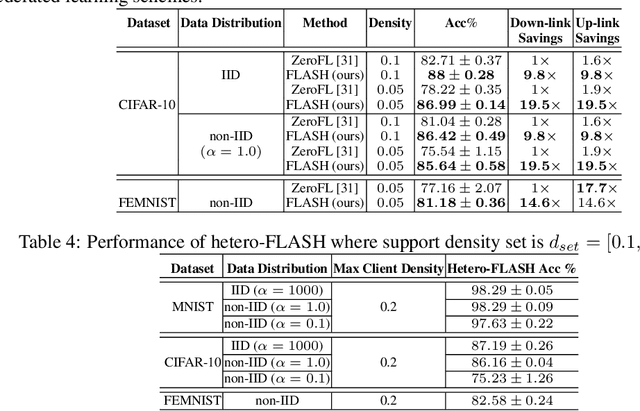
Limited computation and communication capabilities of clients pose significant challenges in federated learning (FL) over resource-limited edge nodes. A potential solution to this problem is to deploy off-the-shelf sparse learning algorithms that train a binary sparse mask on each client with the expectation of training a consistent sparse server mask. However, as we investigate in this paper, such naive deployments result in a significant accuracy drop compared to FL with dense models, especially under low client's resource budget. In particular, our investigations reveal a serious lack of consensus among the trained masks on clients, which prevents convergence on the server mask and potentially leads to a substantial drop in model performance. Based on such key observations, we propose federated lottery aware sparsity hunting (FLASH), a unified sparse learning framework to make the server win a lottery in terms of a sparse sub-model, which can greatly improve performance under highly resource-limited client settings. Moreover, to address the issue of device heterogeneity, we leverage our findings to propose hetero-FLASH, where clients can have different target sparsity budgets based on their device resource limits. Extensive experimental evaluations with multiple models on various datasets (both IID and non-IID) show superiority of our models in yielding up to $\mathord{\sim}10.1\%$ improved accuracy with $\mathord{\sim}10.26\times$ fewer communication costs, compared to existing alternatives, at similar hyperparameter settings.