 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of Binary Neural Networks: Enabling Low-Cost Inference
Mar 16, 2026Federated Learning (FL) preserves privacy by distributing training across devices. However, using DNNs is computationally intensive at the low-powered edge during inference. Edge deployment demands models that simultaneously optimize memory footprint and computational efficiency, a dilemma where conventional DNNs fail by exceeding resource limits. Traditional post-training binarization reduces model size but suffers from severe accuracy loss due to quantization errors. To address these challenges, we propose FedBNN, a rotation-aware binary neural network framework that learns binary representations directly during local training. By encoding each weight as a single bit $\{+1, -1\}$ instead of a $32$-bit float, FedBNN shrinks the model footprint, significantly reducing runtime (during inference) FLOPs and memory requirements in comparison to federated methods using real models. Evaluations across multiple benchmark datasets demonstrate that FedBNN significantly reduces resource consumption while performing similarly to existing federated methods using real-valued models.
Distributed Perceptron under Bounded Staleness, Partial Participation, and Noisy Communication
Jan 15, 2026We study a semi-asynchronous client-server perceptron trained via iterative parameter mixing (IPM-style averaging): clients run local perceptron updates and a server forms a global model by aggregating the updates that arrive in each communication round. The setting captures three system effects in federated and distributed deployments: (i) stale updates due to delayed model delivery and delayed application of client computations (two-sided version lag), (ii) partial participation (intermittent client availability), and (iii) imperfect communication on both downlink and uplink, modeled as effective zero-mean additive noise with bounded second moment. We introduce a server-side aggregation rule called staleness-bucket aggregation with padding that deterministically enforces a prescribed staleness profile over update ages without assuming any stochastic model for delays or participation. Under margin separability and bounded data radius, we prove a finite-horizon expected bound on the cumulative weighted number of perceptron mistakes over a given number of server rounds: the impact of delay appears only through the mean enforced staleness, whereas communication noise contributes an additional term that grows on the order of the square root of the horizon with the total noise energy. In the noiseless case, we show how a finite expected mistake budget yields an explicit finite-round stabilization bound under a mild fresh-participation condition.
Nonlinear Federated System Identification
Aug 20, 2025



We consider federated learning of linearly-parameterized nonlinear systems. We establish theoretical guarantees on the effectiveness of federated nonlinear system identification compared to centralized approaches, demonstrating that the convergence rate improves as the number of clients increases. Although the convergence rates in the linear and nonlinear cases differ only by a constant, this constant depends on the feature map $\phi$, which can be carefully chosen in the nonlinear setting to increase excitation and improve performance. We experimentally validate our theory in physical settings where client devices are driven by i.i.d. control inputs and control policies exhibiting i.i.d. random perturbations, ensuring non-active exploration. Experiments use trajectories from nonlinear dynamical systems characterized by real-analytic feature functions, including polynomial and trigonometric components, representative of physical systems including pendulum and quadrotor dynamics. We analyze the convergence behavior of the proposed method under varying noise levels and data distributions. Results show that federated learning consistently improves convergence of any individual client as the number of participating clients increases.
Embracing Federated Learning: Enabling Weak Client Participation via Partial Model Training
Jun 21, 2024



In Federated Learning (FL), clients may have weak devices that cannot train the full model or even hold it in their memory space. To implement large-scale FL applications, thus, it is crucial to develop a distributed learning method that enables the participation of such weak clients. We propose EmbracingFL, a general FL framework that allows all available clients to join the distributed training regardless of their system resource capacity. The framework is built upon a novel form of partial model training method in which each client trains as many consecutive output-side layers as its system resources allow. Our study demonstrates that EmbracingFL encourages each layer to have similar data representations across clients, improving FL efficiency. The proposed partial model training method guarantees convergence to a neighbor of stationary points for non-convex and smooth problems. We evaluate the efficacy of EmbracingFL under a variety of settings with a mixed number of strong, moderate (~40% memory), and weak (~15% memory) clients, datasets (CIFAR-10, FEMNIST, and IMDB), and models (ResNet20, CNN, and LSTM). Our empirical study shows that EmbracingFL consistently achieves high accuracy as like all clients are strong, outperforming the state-of-the-art width reduction methods (i.e. HeteroFL and FjORD).
ATP: Enabling Fast LLM Serving via Attention on Top Principal Keys
Mar 01, 2024



We propose a new attention mechanism with linear complexity, ATP, that fixates \textbf{A}ttention on \textbf{T}op \textbf{P}rincipal keys, rather than on each individual token. Particularly, ATP is driven by an important observation that input sequences are typically low-rank, i.e., input sequences can be represented by a few principal bases. Therefore, instead of directly iterating over all the input tokens, ATP transforms inputs into an orthogonal space and computes attention only on the top principal bases (keys). Owing to the observed low-rank structure in input sequences, ATP is able to capture semantic relationships in input sequences with a few principal keys. Furthermore, the attention complexity is reduced from \emph{quadratic} to \emph{linear} without incurring a noticeable performance drop. ATP further reduces complexity for other linear layers with low-rank inputs, leading to more speedup compared to prior works that solely target the attention module. Our evaluations on various models (e.g., BERT and Llama) demonstrate that ATP achieves comparable accuracy with much lower computation and memory complexity than the standard attention mechanism. In particular, ATP barely loses accuracy with only $1/2$ principal keys, and only incurs around $2\%$ accuracy drops with $1/4$ principal keys.
All Rivers Run to the Sea: Private Learning with Asymmetric Flows
Dec 05, 2023



Data privacy is of great concern in cloud machine-learning service platforms, when sensitive data are exposed to service providers. While private computing environments (e.g., secure enclaves), and cryptographic approaches (e.g., homomorphic encryption) provide strong privacy protection, their computing performance still falls short compared to cloud GPUs. To achieve privacy protection with high computing performance, we propose Delta, a new private training and inference framework, with comparable model performance as non-private centralized training. Delta features two asymmetric data flows: the main information-sensitive flow and the residual flow. The main part flows into a small model while the residuals are offloaded to a large model. Specifically, Delta embeds the information-sensitive representations into a low-dimensional space while pushing the information-insensitive part into high-dimension residuals. To ensure privacy protection, the low-dimensional information-sensitive part is secured and fed to a small model in a private environment. On the other hand, the residual part is sent to fast cloud GPUs, and processed by a large model. To further enhance privacy and reduce the communication cost, Delta applies a random binary quantization technique along with a DP-based technique to the residuals before sharing them with the public platform. We theoretically show that Delta guarantees differential privacy in the public environment and greatly reduces the complexity in the private environment. We conduct empirical analyses on CIFAR-10, CIFAR-100 and ImageNet datasets and ResNet-18 and ResNet-34, showing that Delta achieves strong privacy protection, fast training, and inference without significantly compromising the model utility.
Federated Classification in Hyperbolic Spaces via Secure Aggregation of Convex Hulls
Aug 14, 2023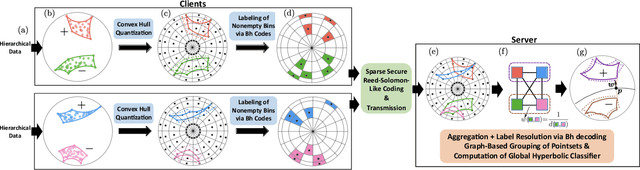
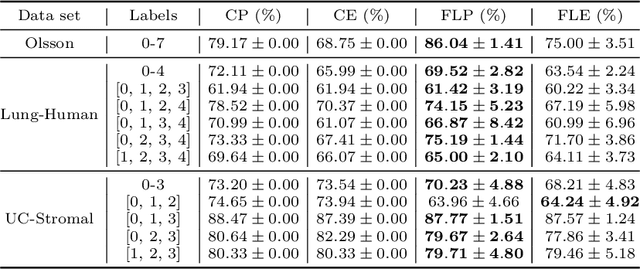
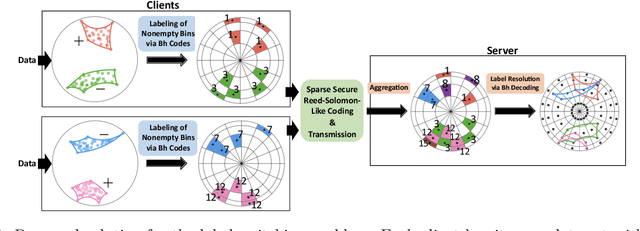

Hierarchical and tree-like data sets arise in many applications, including language processing, graph data mining, phylogeny and genomics. It is known that tree-like data cannot be embedded into Euclidean spaces of finite dimension with small distortion. This problem can be mitigated through the use of hyperbolic spaces. When such data also has to be processed in a distributed and privatized setting, it becomes necessary to work with new federated learning methods tailored to hyperbolic spaces. As an initial step towards the development of the field of federated learning in hyperbolic spaces, we propose the first known approach to federated classification in hyperbolic spaces. Our contributions are as follows. First, we develop distributed versions of convex SVM classifiers for Poincar\'e discs. In this setting, the information conveyed from clients to the global classifier are convex hulls of clusters present in individual client data. Second, to avoid label switching issues, we introduce a number-theoretic approach for label recovery based on the so-called integer $B_h$ sequences. Third, we compute the complexity of the convex hulls in hyperbolic spaces to assess the extent of data leakage; at the same time, in order to limit the communication cost for the hulls, we propose a new quantization method for the Poincar\'e disc coupled with Reed-Solomon-like encoding. Fourth, at server level, we introduce a new approach for aggregating convex hulls of the clients based on balanced graph partitioning. We test our method on a collection of diverse data sets, including hierarchical single-cell RNA-seq data from different patients distributed across different repositories that have stringent privacy constraints. The classification accuracy of our method is up to $\sim 11\%$ better than its Euclidean counterpart, demonstrating the importance of privacy-preserving learning in hyperbolic spaces.
Machine Unlearning of Federated Clusters
Oct 28, 2022
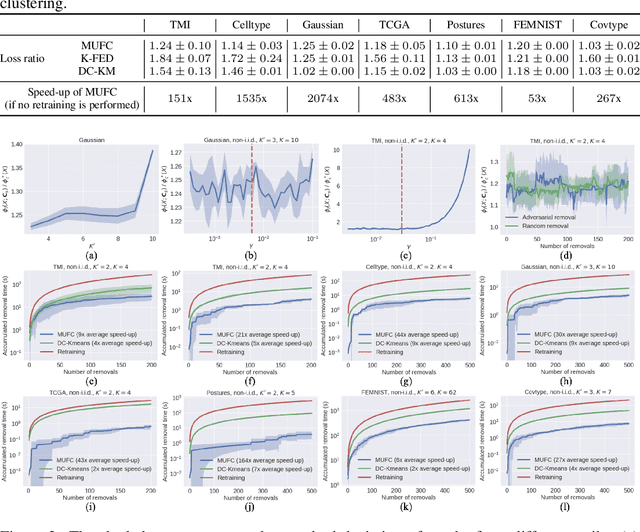
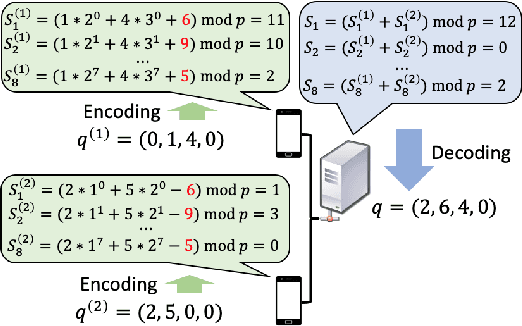

Federated clustering is an unsupervised learning problem that arises in a number of practical applications, including personalized recommender and healthcare systems. With the adoption of recent laws ensuring the "right to be forgotten", the problem of machine unlearning for federated clustering methods has become of significant importance. This work proposes the first known unlearning mechanism for federated clustering with privacy criteria that support simple, provable, and efficient data removal at the client and server level. The gist of our approach is to combine special initialization procedures with quantization methods that allow for secure aggregation of estimated local cluster counts at the server unit. As part of our platform, we introduce secure compressed multiset aggregation (SCMA), which is of independent interest for secure sparse model aggregation. In order to simultaneously facilitate low communication complexity and secret sharing protocols, we integrate Reed-Solomon encoding with special evaluation points into the new SCMA pipeline and derive bounds on the time and communication complexity of different components of the scheme. Compared to completely retraining K-means++ locally and globally for each removal request, we obtain an average speed-up of roughly 84x across seven datasets, two of which contain biological and medical information that is subject to frequent unlearning requests.
Federated Learning of Large Models at the Edge via Principal Sub-Model Training
Aug 28, 2022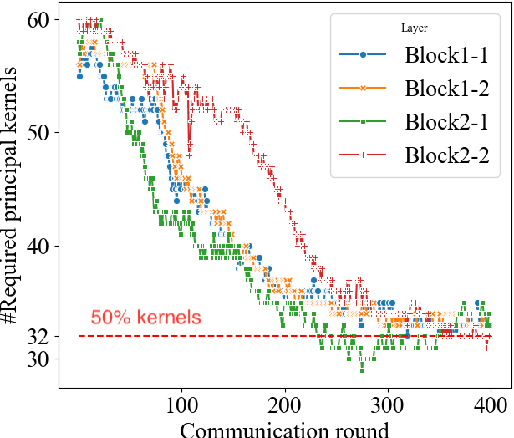

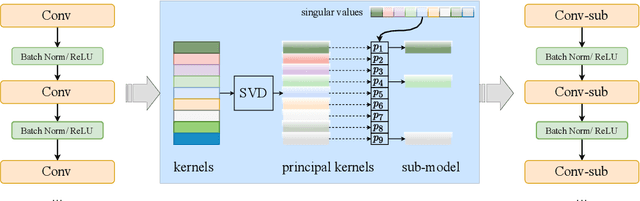
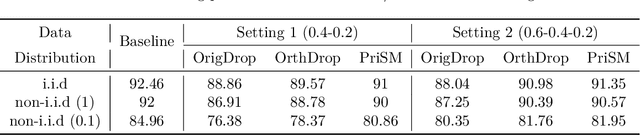
Limited compute and communication capabilities of edge users create a significant bottleneck for federated learning (FL) of large models. We consider a realistic, but much less explored, cross-device FL setting in which no client has the capacity to train a full large model nor is willing to share any intermediate activations with the server. To this end, we present Principal Sub-Model (PriSM) training methodology, which leverages models low-rank structure and kernel orthogonality to train sub-models in the orthogonal kernel space. More specifically, by applying singular value decomposition (SVD) to original kernels in the server model, PriSM first obtains a set of principal orthogonal kernels in which each one is weighed by its singular value. Thereafter, PriSM utilizes our novel sampling strategy that selects different subsets of the principal kernels independently to create sub-models for clients. Importantly, a kernel with a large singular value is assigned with a high sampling probability. Thus, each sub-model is a low-rank approximation of the full large model, and all clients together achieve the near full-model training. Our extensive evaluations on multiple datasets in various resource-constrained settings show that PriSM can yield an improved performance of up to 10% compared to existing alternatives, with only around 20% sub-model training.
Federated Sparse Training: Lottery Aware Model Compression for Resource Constrained Edge
Aug 27, 2022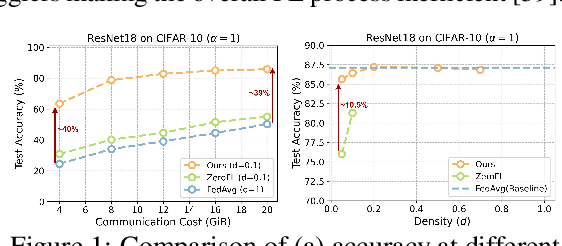


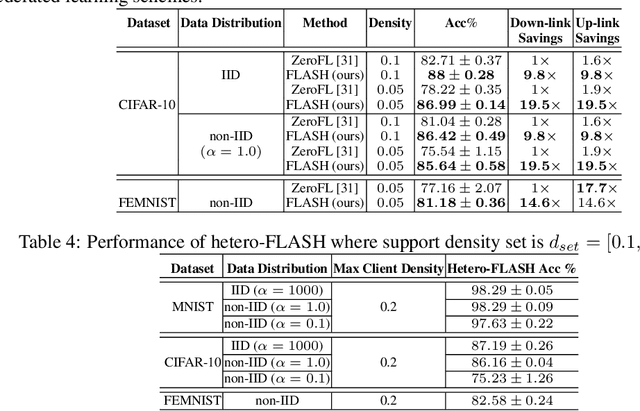
Limited computation and communication capabilities of clients pose significant challenges in federated learning (FL) over resource-limited edge nodes. A potential solution to this problem is to deploy off-the-shelf sparse learning algorithms that train a binary sparse mask on each client with the expectation of training a consistent sparse server mask. However, as we investigate in this paper, such naive deployments result in a significant accuracy drop compared to FL with dense models, especially under low client's resource budget. In particular, our investigations reveal a serious lack of consensus among the trained masks on clients, which prevents convergence on the server mask and potentially leads to a substantial drop in model performance. Based on such key observations, we propose federated lottery aware sparsity hunting (FLASH), a unified sparse learning framework to make the server win a lottery in terms of a sparse sub-model, which can greatly improve performance under highly resource-limited client settings. Moreover, to address the issue of device heterogeneity, we leverage our findings to propose hetero-FLASH, where clients can have different target sparsity budgets based on their device resource limits. Extensive experimental evaluations with multiple models on various datasets (both IID and non-IID) show superiority of our models in yielding up to $\mathord{\sim}10.1\%$ improved accuracy with $\mathord{\sim}10.26\times$ fewer communication costs, compared to existing alternatives, at similar hyperparameter settings.