 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoded Computing for Low-Latency Federated Learning over Wireless Edge Networks
Nov 12, 2020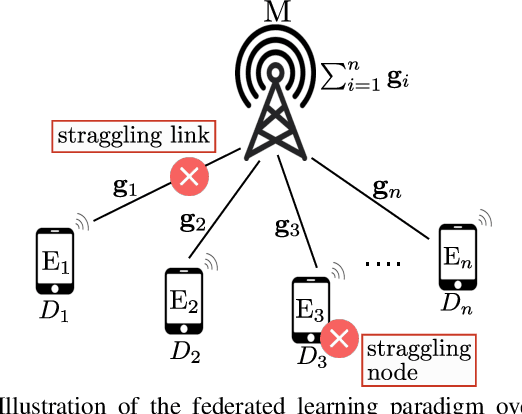
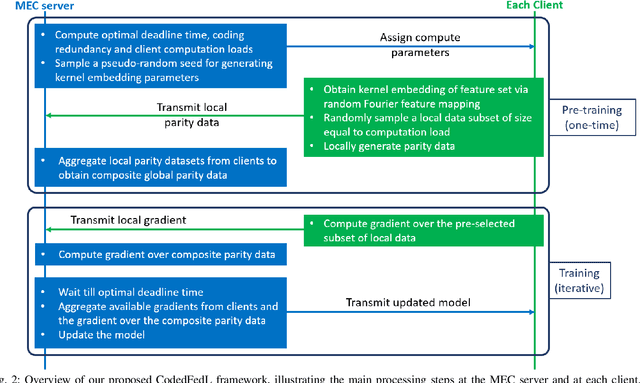
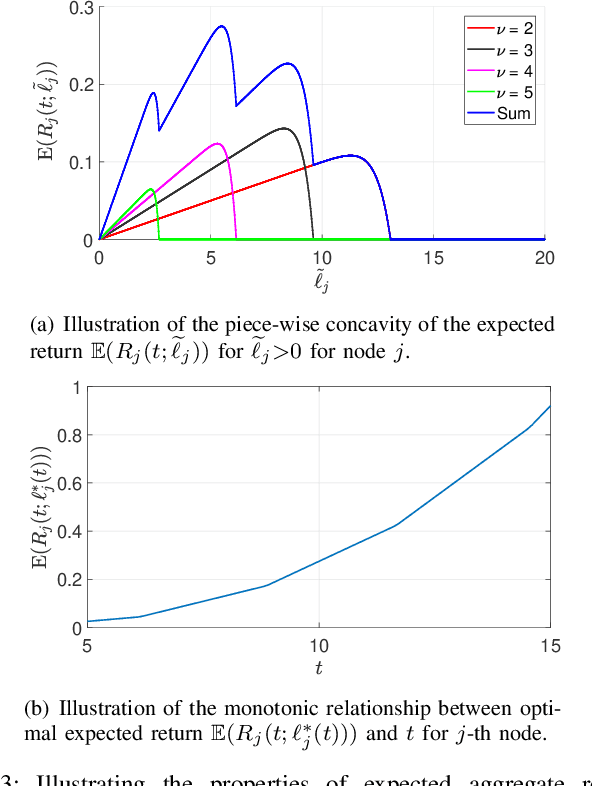
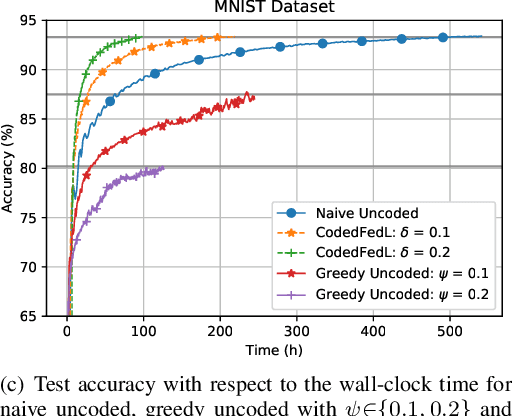
Federated learning enables training a global model from data located at the client nodes, without data sharing and moving client data to a centralized server. Performance of federated learning in a multi-access edge computing (MEC) network suffers from slow convergence due to heterogeneity and stochastic fluctuations in compute power and communication link qualities across clients. We propose a novel coded computing framework, CodedFedL, that injects structured coding redundancy into federated learning for mitigating stragglers and speeding up the training procedure. CodedFedL enables coded computing for non-linear federated learning by efficiently exploiting distributed kernel embedding via random Fourier features that transforms the training task into computationally favourable distributed linear regression. Furthermore, clients generate local parity datasets by coding over their local datasets, while the server combines them to obtain the global parity dataset. Gradient from the global parity dataset compensates for straggling gradients during training, and thereby speeds up convergence. For minimizing the epoch deadline time at the MEC server, we provide a tractable approach for finding the amount of coding redundancy and the number of local data points that a client processes during training, by exploiting the statistical properties of compute as well as communication delays. We also characterize the leakage in data privacy when clients share their local parity datasets with the server. We analyze the convergence rate and iteration complexity of CodedFedL under simplifying assumptions, by treating CodedFedL as a stochastic gradient descent algorithm. Furthermore, we conduct numerical experiments using practical network parameters and benchmark datasets, where CodedFedL speeds up the overall training time by up to $15\times$ in comparison to the benchmark schemes.
Coded Federated Learning
Feb 21, 2020

Federated learning is a method of training a global model from decentralized data distributed across client devices. Here, model parameters are computed locally by each client device and exchanged with a central server, which aggregates the local models for a global view, without requiring sharing of training data. The convergence performance of federated learning is severely impacted in heterogeneous computing platforms such as those at the wireless edge, where straggling computations and communication links can significantly limit timely model parameter updates. This paper develops a novel coded computing technique for federated learning to mitigate the impact of stragglers. In the proposed Coded Federated Learning (CFL) scheme, each client device privately generates parity training data and shares it with the central server only once at the start of the training phase. The central server can then preemptively perform redundant gradient computations on the composite parity data to compensate for the erased or delayed parameter updates. Our results show that CFL allows the global model to converge nearly four times faster when compared to an uncoded approach