 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Private Image Generation via Coarse-to-Fine Wavelet Modeling
Feb 26, 2026Generative models trained on sensitive image datasets risk memorizing and reproducing individual training examples, making strong privacy guarantees essential. While differential privacy (DP) provides a principled framework for such guarantees, standard DP finetuning (e.g., with DP-SGD) often results in severe degradation of image quality, particularly in high-frequency textures, due to the indiscriminate addition of noise across all model parameters. In this work, we propose a spectral DP framework based on the hypothesis that the most privacy-sensitive portions of an image are often low-frequency components in the wavelet space (e.g., facial features and object shapes) while high-frequency components are largely generic and public. Based on this hypothesis, we propose the following two-stage framework for DP image generation with coarse image intermediaries: (1) DP finetune an autoregressive spectral image tokenizer model on the low-resolution wavelet coefficients of the sensitive images, and (2) perform high-resolution upsampling using a publicly pretrained super-resolution model. By restricting the privacy budget to the global structures of the image in the first stage, and leveraging the post-processing property of DP for detail refinement, we achieve promising trade-offs between privacy and utility. Experiments on the MS-COCO and MM-CelebA-HQ datasets show that our method generates images with improved quality and style capture relative to other leading DP image frameworks.
Privately Fine-Tuned LLMs Preserve Temporal Dynamics in Tabular Data
Feb 02, 2026Research on differentially private synthetic tabular data has largely focused on independent and identically distributed rows where each record corresponds to a unique individual. This perspective neglects the temporal complexity in longitudinal datasets, such as electronic health records, where a user contributes an entire (sub) table of sequential events. While practitioners might attempt to model such data by flattening user histories into high-dimensional vectors for use with standard marginal-based mechanisms, we demonstrate that this strategy is insufficient. Flattening fails to preserve temporal coherence even when it maintains valid marginal distributions. We introduce PATH, a novel generative framework that treats the full table as the unit of synthesis and leverages the autoregressive capabilities of privately fine-tuned large language models. Extensive evaluations show that PATH effectively captures long-range dependencies that traditional methods miss. Empirically, our method reduces the distributional distance to real trajectories by over 60% and reduces state transition errors by nearly 50% compared to leading marginal mechanisms while achieving similar marginal fidelity.
Clustering and Median Aggregation Improve Differentially Private Inference
Jun 05, 2025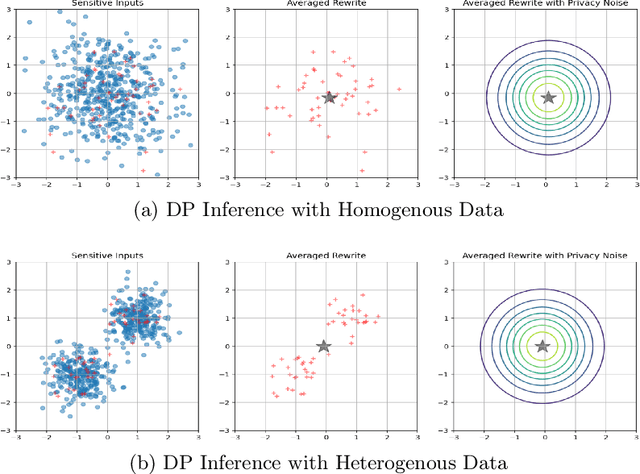

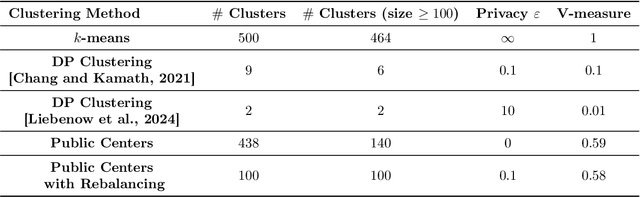
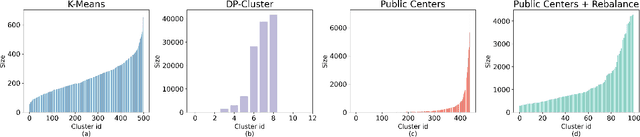
Differentially private (DP) language model inference is an approach for generating private synthetic text. A sensitive input example is used to prompt an off-the-shelf large language model (LLM) to produce a similar example. Multiple examples can be aggregated together to formally satisfy the DP guarantee. Prior work creates inference batches by sampling sensitive inputs uniformly at random. We show that uniform sampling degrades the quality of privately generated text, especially when the sensitive examples concern heterogeneous topics. We remedy this problem by clustering the input data before selecting inference batches. Next, we observe that clustering also leads to more similar next-token predictions across inferences. We use this insight to introduce a new algorithm that aggregates next token statistics by privately computing medians instead of averages. This approach leverages the fact that the median has decreased local sensitivity when next token predictions are similar, allowing us to state a data-dependent and ex-post DP guarantee about the privacy properties of this algorithm. Finally, we demonstrate improvements in terms of representativeness metrics (e.g., MAUVE) as well as downstream task performance. We show that our method produces high-quality synthetic data at significantly lower privacy cost than a previous state-of-the-art method.
An Optimization Framework for Differentially Private Sparse Fine-Tuning
Mar 17, 2025



Differentially private stochastic gradient descent (DP-SGD) is broadly considered to be the gold standard for training and fine-tuning neural networks under differential privacy (DP). With the increasing availability of high-quality pre-trained model checkpoints (e.g., vision and language models), fine-tuning has become a popular strategy. However, despite recent progress in understanding and applying DP-SGD for private transfer learning tasks, significant challenges remain -- most notably, the performance gap between models fine-tuned with DP-SGD and their non-private counterparts. Sparse fine-tuning on private data has emerged as an alternative to full-model fine-tuning; recent work has shown that privately fine-tuning only a small subset of model weights and keeping the rest of the weights fixed can lead to better performance. In this work, we propose a new approach for sparse fine-tuning of neural networks under DP. Existing work on private sparse finetuning often used fixed choice of trainable weights (e.g., updating only the last layer), or relied on public model's weights to choose the subset of weights to modify. Such choice of weights remains suboptimal. In contrast, we explore an optimization-based approach, where our selection method makes use of the private gradient information, while using off the shelf privacy accounting techniques. Our numerical experiments on several computer vision models and datasets show that our selection method leads to better prediction accuracy, compared to full-model private fine-tuning or existing private sparse fine-tuning approaches.
HASSLE-free: A unified Framework for Sparse plus Low-Rank Matrix Decomposition for LLMs
Feb 02, 2025The impressive capabilities of large foundation models come at a cost of substantial computing resources to serve them. Compressing these pre-trained models is of practical interest as it can democratize deploying them to the machine learning community at large by lowering the costs associated with inference. A promising compression scheme is to decompose foundation models' dense weights into a sum of sparse plus low-rank matrices. In this paper, we design a unified framework coined HASSLE-free for (semi-structured) sparse plus low-rank matrix decomposition of foundation models. Our framework introduces the local layer-wise reconstruction error objective for this decomposition, we demonstrate that prior work solves a relaxation of this optimization problem; and we provide efficient and scalable methods to minimize the exact introduced optimization problem. HASSLE-free substantially outperforms state-of-the-art methods in terms of the introduced objective and a wide range of LLM evaluation benchmarks. For the Llama3-8B model with a 2:4 sparsity component plus a 64-rank component decomposition, a compression scheme for which recent work shows important inference acceleration on GPUs, HASSLE-free reduces the test perplexity by 12% for the WikiText-2 dataset and reduces the gap (compared to the dense model) of the average of eight popular zero-shot tasks by 15% compared to existing methods.
Private prediction for large-scale synthetic text generation
Jul 16, 2024We present an approach for generating differentially private synthetic text using large language models (LLMs), via private prediction. In the private prediction framework, we only require the output synthetic data to satisfy differential privacy guarantees. This is in contrast to approaches that train a generative model on potentially sensitive user-supplied source data and seek to ensure the model itself is safe to release. We prompt a pretrained LLM with source data, but ensure that next-token predictions are made with differential privacy guarantees. Previous work in this paradigm reported generating a small number of examples (<10) at reasonable privacy levels, an amount of data that is useful only for downstream in-context learning or prompting. In contrast, we make changes that allow us to generate thousands of high-quality synthetic data points, greatly expanding the set of potential applications. Our improvements come from an improved privacy analysis and a better private selection mechanism, which makes use of the equivalence between the softmax layer for sampling tokens in LLMs and the exponential mechanism. Furthermore, we introduce a novel use of public predictions via the sparse vector technique, in which we do not pay privacy costs for tokens that are predictable without sensitive data; we find this to be particularly effective for structured data.
DART: A Principled Approach to Adversarially Robust Unsupervised Domain Adaptation
Feb 16, 2024Distribution shifts and adversarial examples are two major challenges for deploying machine learning models. While these challenges have been studied individually, their combination is an important topic that remains relatively under-explored. In this work, we study the problem of adversarial robustness under a common setting of distribution shift - unsupervised domain adaptation (UDA). Specifically, given a labeled source domain $D_S$ and an unlabeled target domain $D_T$ with related but different distributions, the goal is to obtain an adversarially robust model for $D_T$. The absence of target domain labels poses a unique challenge, as conventional adversarial robustness defenses cannot be directly applied to $D_T$. To address this challenge, we first establish a generalization bound for the adversarial target loss, which consists of (i) terms related to the loss on the data, and (ii) a measure of worst-case domain divergence. Motivated by this bound, we develop a novel unified defense framework called Divergence Aware adveRsarial Training (DART), which can be used in conjunction with a variety of standard UDA methods; e.g., DANN [Ganin and Lempitsky, 2015]. DART is applicable to general threat models, including the popular $\ell_p$-norm model, and does not require heuristic regularizers or architectural changes. We also release DomainRobust: a testbed for evaluating robustness of UDA models to adversarial attacks. DomainRobust consists of 4 multi-domain benchmark datasets (with 46 source-target pairs) and 7 meta-algorithms with a total of 11 variants. Our large-scale experiments demonstrate that on average, DART significantly enhances model robustness on all benchmarks compared to the state of the art, while maintaining competitive standard accuracy. The relative improvement in robustness from DART reaches up to 29.2% on the source-target domain pairs considered.
JetTrain: IDE-Native Machine Learning Experiments
Feb 16, 2024Integrated development environments (IDEs) are prevalent code-writing and debugging tools. However, they have yet to be widely adopted for launching machine learning (ML) experiments. This work aims to fill this gap by introducing JetTrain, an IDE-integrated tool that delegates specific tasks from an IDE to remote computational resources. A user can write and debug code locally and then seamlessly run it remotely using on-demand hardware. We argue that this approach can lower the entry barrier for ML training problems and increase experiment throughput.
Scaling Laws for Downstream Task Performance of Large Language Models
Feb 06, 2024



Scaling laws provide important insights that can guide the design of large language models (LLMs). Existing work has primarily focused on studying scaling laws for pretraining (upstream) loss. However, in transfer learning settings, in which LLMs are pretrained on an unsupervised dataset and then finetuned on a downstream task, we often also care about the downstream performance. In this work, we study the scaling behavior in a transfer learning setting, where LLMs are finetuned for machine translation tasks. Specifically, we investigate how the choice of the pretraining data and its size affect downstream performance (translation quality) as judged by two metrics: downstream cross-entropy and BLEU score. Our experiments indicate that the size of the finetuning dataset and the distribution alignment between the pretraining and downstream data significantly influence the scaling behavior. With sufficient alignment, both downstream cross-entropy and BLEU score improve monotonically with more pretraining data. In such cases, we show that it is possible to predict the downstream BLEU score with good accuracy using a log-law. However, there are also cases where moderate misalignment causes the BLEU score to fluctuate or get worse with more pretraining, whereas downstream cross-entropy monotonically improves. By analyzing these observations, we provide new practical insights for choosing appropriate pretraining data.
COMET: Learning Cardinality Constrained Mixture of Experts with Trees and Local Search
Jun 05, 2023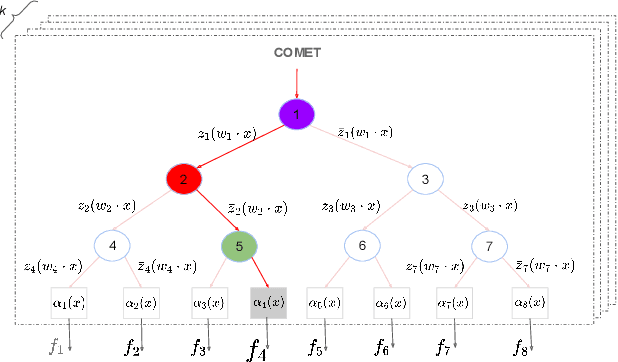
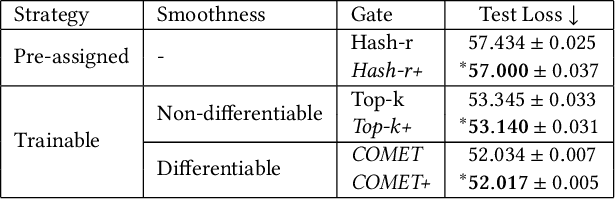
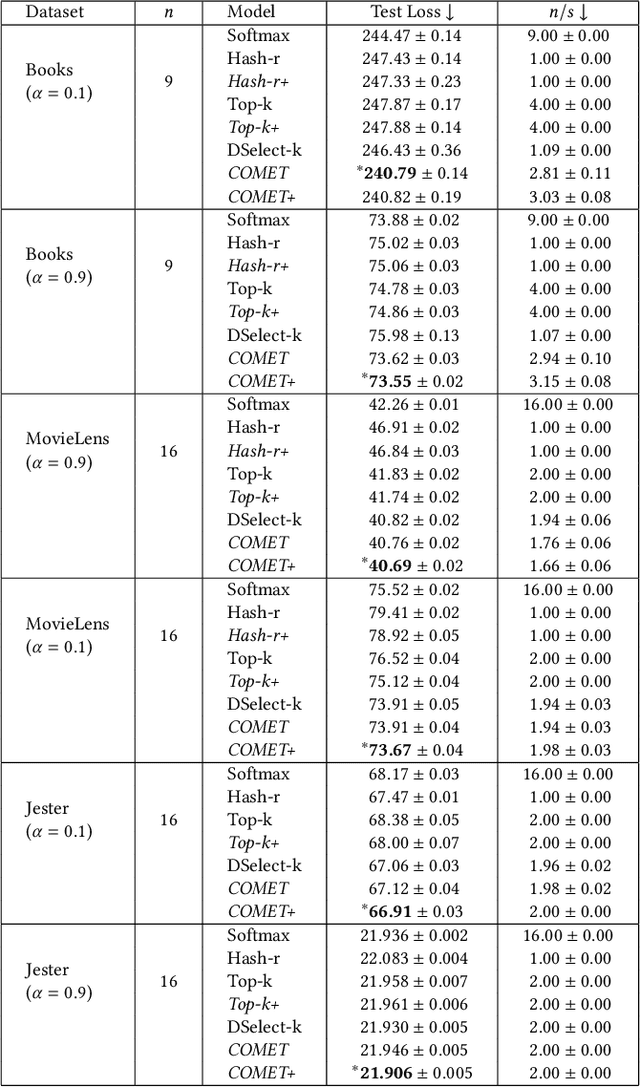
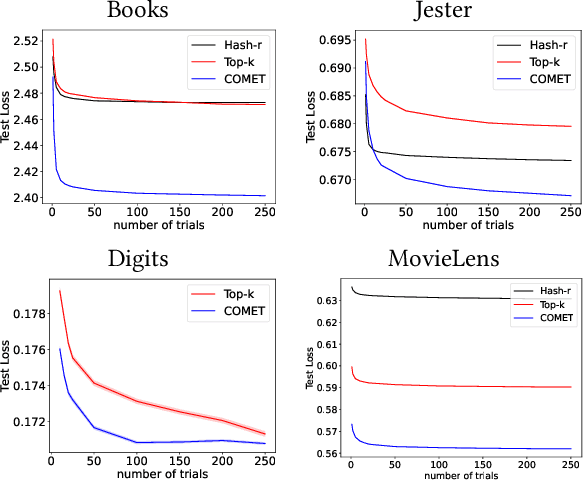
The sparse Mixture-of-Experts (Sparse-MoE) framework efficiently scales up model capacity in various domains, such as natural language processing and vision. Sparse-MoEs select a subset of the "experts" (thus, only a portion of the overall network) for each input sample using a sparse, trainable gate. Existing sparse gates are prone to convergence and performance issues when training with first-order optimization methods. In this paper, we introduce two improvements to current MoE approaches. First, we propose a new sparse gate: COMET, which relies on a novel tree-based mechanism. COMET is differentiable, can exploit sparsity to speed up computation, and outperforms state-of-the-art gates. Second, due to the challenging combinatorial nature of sparse expert selection, first-order methods are typically prone to low-quality solutions. To deal with this challenge, we propose a novel, permutation-based local search method that can complement first-order methods in training any sparse gate, e.g., Hash routing, Top-k, DSelect-k, and COMET. We show that local search can help networks escape bad initializations or solutions. We performed large-scale experiments on various domains, including recommender systems, vision, and natural language processing. On standard vision and recommender systems benchmarks, COMET+ (COMET with local search) achieves up to 13% improvement in ROC AUC over popular gates, e.g., Hash routing and Top-k, and up to 9% over prior differentiable gates e.g., DSelect-k. When Top-k and Hash gates are combined with local search, we see up to $100\times$ reduction in the budget needed for hyperparameter tuning. Moreover, for language modeling, our approach improves over the state-of-the-art MoEBERT model for distilling BERT on 5/7 GLUE benchmarks as well as SQuAD dataset.