 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Feature Selection Approach for Learning Skinny Trees
Oct 28, 2023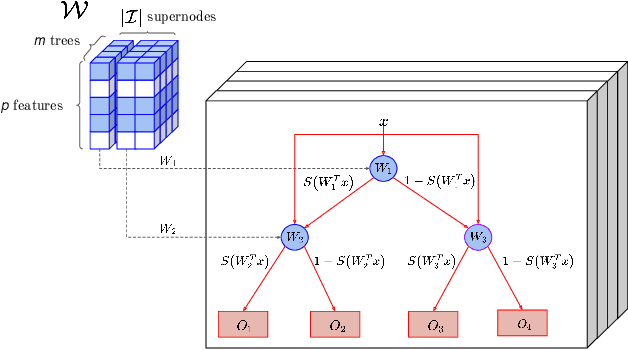
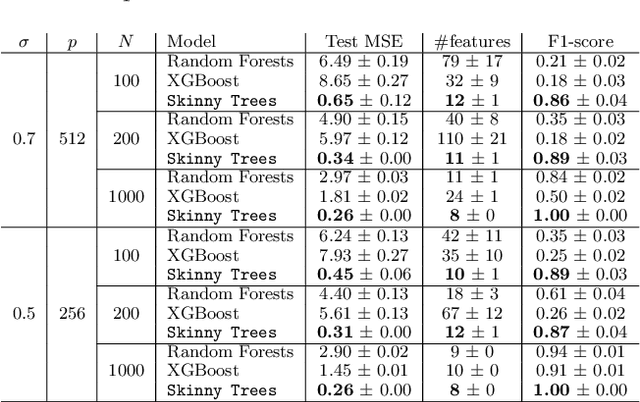
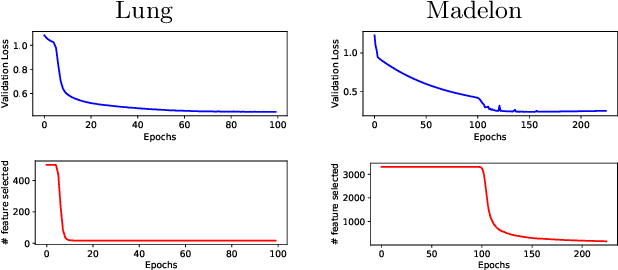
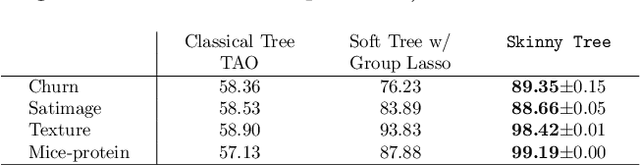
Joint feature selection and tree ensemble learning is a challenging task. Popular tree ensemble toolkits e.g., Gradient Boosted Trees and Random Forests support feature selection post-training based on feature importances, which are known to be misleading, and can significantly hurt performance. We propose Skinny Trees: a toolkit for feature selection in tree ensembles, such that feature selection and tree ensemble learning occurs simultaneously. It is based on an end-to-end optimization approach that considers feature selection in differentiable trees with Group $\ell_0 - \ell_2$ regularization. We optimize with a first-order proximal method and present convergence guarantees for a non-convex and non-smooth objective. Interestingly, dense-to-sparse regularization scheduling can lead to more expressive and sparser tree ensembles than vanilla proximal method. On 15 synthetic and real-world datasets, Skinny Trees can achieve $1.5\times$ - $620\times$ feature compression rates, leading up to $10\times$ faster inference over dense trees, without any loss in performance. Skinny Trees lead to superior feature selection than many existing toolkits e.g., in terms of AUC performance for $25\%$ feature budget, Skinny Trees outperforms LightGBM by $10.2\%$ (up to $37.7\%$), and Random Forests by $3\%$ (up to $12.5\%$).
COMET: Learning Cardinality Constrained Mixture of Experts with Trees and Local Search
Jun 05, 2023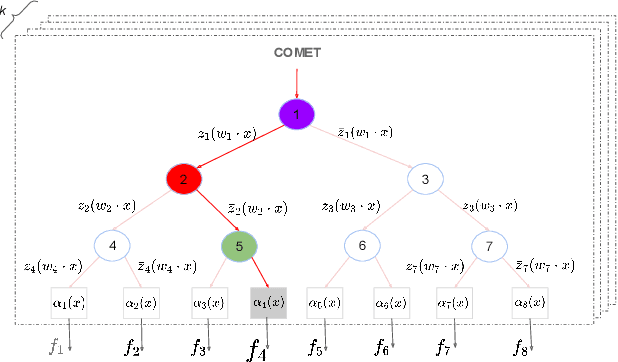
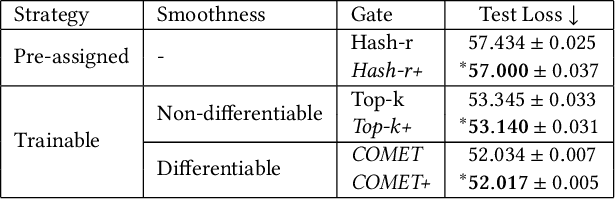
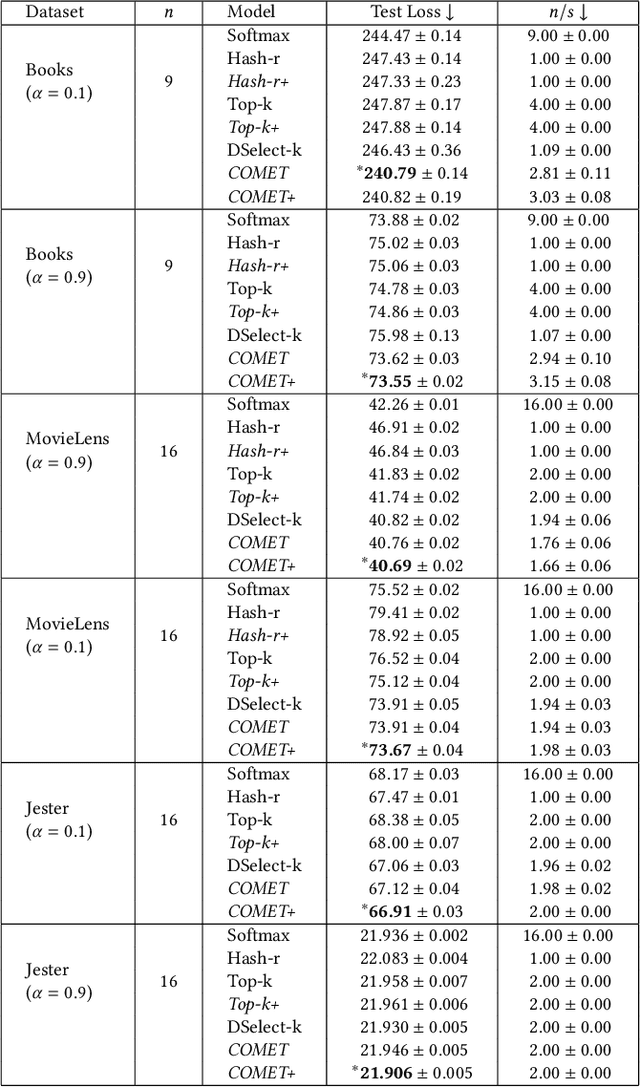
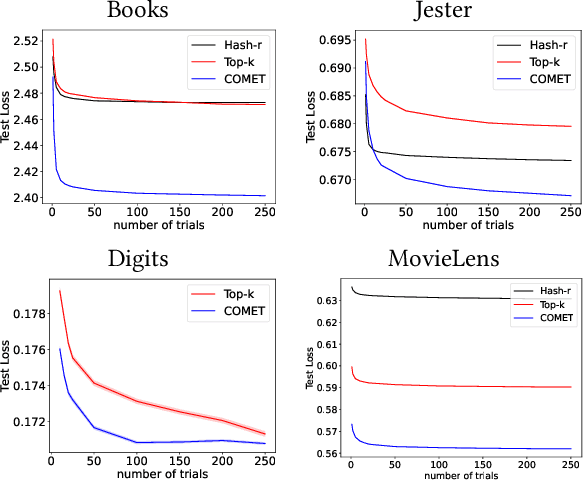
The sparse Mixture-of-Experts (Sparse-MoE) framework efficiently scales up model capacity in various domains, such as natural language processing and vision. Sparse-MoEs select a subset of the "experts" (thus, only a portion of the overall network) for each input sample using a sparse, trainable gate. Existing sparse gates are prone to convergence and performance issues when training with first-order optimization methods. In this paper, we introduce two improvements to current MoE approaches. First, we propose a new sparse gate: COMET, which relies on a novel tree-based mechanism. COMET is differentiable, can exploit sparsity to speed up computation, and outperforms state-of-the-art gates. Second, due to the challenging combinatorial nature of sparse expert selection, first-order methods are typically prone to low-quality solutions. To deal with this challenge, we propose a novel, permutation-based local search method that can complement first-order methods in training any sparse gate, e.g., Hash routing, Top-k, DSelect-k, and COMET. We show that local search can help networks escape bad initializations or solutions. We performed large-scale experiments on various domains, including recommender systems, vision, and natural language processing. On standard vision and recommender systems benchmarks, COMET+ (COMET with local search) achieves up to 13% improvement in ROC AUC over popular gates, e.g., Hash routing and Top-k, and up to 9% over prior differentiable gates e.g., DSelect-k. When Top-k and Hash gates are combined with local search, we see up to $100\times$ reduction in the budget needed for hyperparameter tuning. Moreover, for language modeling, our approach improves over the state-of-the-art MoEBERT model for distilling BERT on 5/7 GLUE benchmarks as well as SQuAD dataset.
Flexible Modeling and Multitask Learning using Differentiable Tree Ensembles
May 19, 2022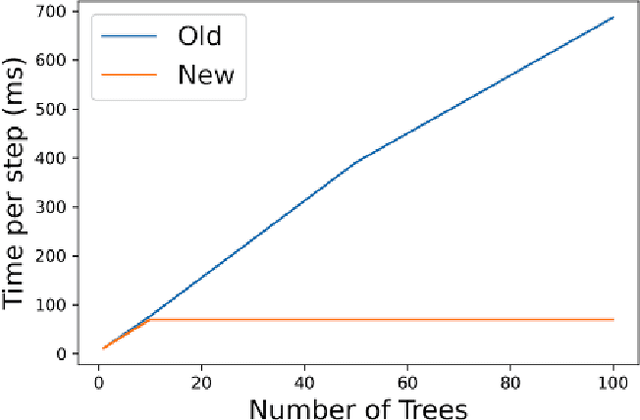
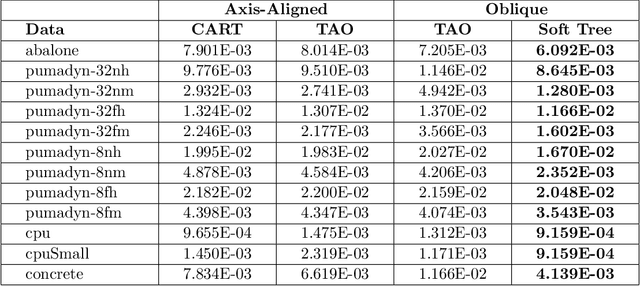
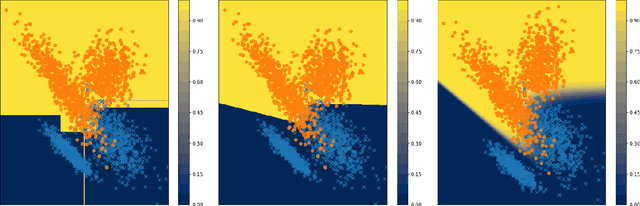
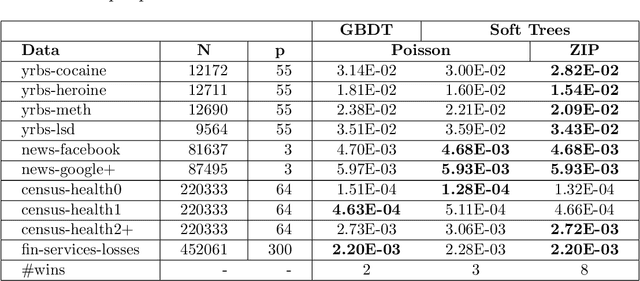
Decision tree ensembles are widely used and competitive learning models. Despite their success, popular toolkits for learning tree ensembles have limited modeling capabilities. For instance, these toolkits support a limited number of loss functions and are restricted to single task learning. We propose a flexible framework for learning tree ensembles, which goes beyond existing toolkits to support arbitrary loss functions, missing responses, and multi-task learning. Our framework builds on differentiable (a.k.a. soft) tree ensembles, which can be trained using first-order methods. However, unlike classical trees, differentiable trees are difficult to scale. We therefore propose a novel tensor-based formulation of differentiable trees that allows for efficient vectorization on GPUs. We perform experiments on a collection of 28 real open-source and proprietary datasets, which demonstrate that our framework can lead to 100x more compact and 23% more expressive tree ensembles than those by popular toolkits.
Newer is not always better: Rethinking transferability metrics, their peculiarities, stability and performance
Oct 25, 2021

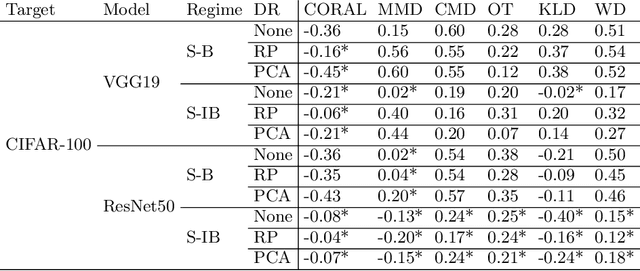

Fine-tuning of large pre-trained image and language models on small customized datasets has become increasingly popular for improved prediction and efficient use of limited resources. Fine-tuning requires identification of best models to transfer-learn from and quantifying transferability prevents expensive re-training on all of the candidate models/tasks pairs. We show that the statistical problems with covariance estimation drive the poor performance of H-score [Bao et al., 2019] -- a common baseline for newer metrics -- and propose shrinkage-based estimator. This results in up to 80% absolute gain in H-score correlation performance, making it competitive with the state-of-the-art LogME measure by You et al. [2021]. Our shrinkage-based H-score is 3-55 times faster to compute compared to LogME. Additionally, we look into a less common setting of target (as opposed to source) task selection. We identify previously overlooked problems in such settings with different number of labels, class-imbalance ratios etc. for some recent metrics e.g., LEEP [Nguyen et al., 2020] that resulted in them being misrepresented as leading measures. We propose a correction and recommend measuring correlation performance against relative accuracy in such settings. We also outline the difficulties of comparing feature-dependent metrics, both supervised (e.g. H-score) and unsupervised measures (e.g., Maximum Mean Discrepancy [Long et al., 2015]), across source models/layers with different feature embedding dimension. We show that dimensionality reduction methods allow for meaningful comparison across models and improved performance of some of these measures. We investigate performance of 14 different supervised and unsupervised metrics and demonstrate that even unsupervised metrics can identify the leading models for domain adaptation. We support our findings with ~65,000 (fine-tuning trials) experiments.
Predicting Census Survey Response Rates via Interpretable Nonparametric Additive Models with Structured Interactions
Aug 24, 2021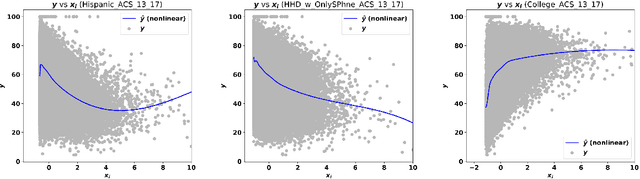
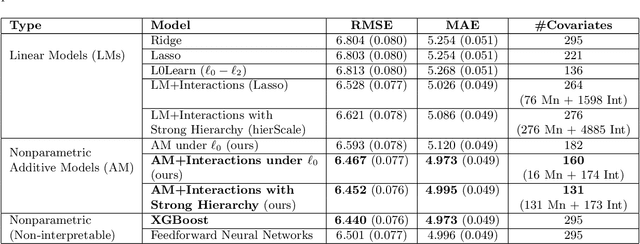

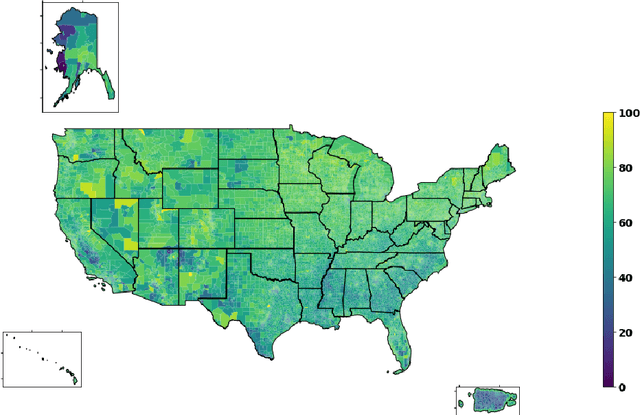
Accurate and interpretable prediction of survey response rates is important from an operational standpoint. The US Census Bureau's well-known ROAM application uses principled statistical models trained on the US Census Planning Database data to identify hard-to-survey areas. An earlier crowdsourcing competition revealed that an ensemble of regression trees led to the best performance in predicting survey response rates; however, the corresponding models could not be adopted for the intended application due to limited interpretability. In this paper, we present new interpretable statistical methods to predict, with high accuracy, response rates in surveys. We study sparse nonparametric additive models with pairwise interactions via $\ell_0$-regularization, as well as hierarchically structured variants that provide enhanced interpretability. Despite strong methodological underpinnings, such models can be computationally challenging -- we present new scalable algorithms for learning these models. We also establish novel non-asymptotic error bounds for the proposed estimators. Experiments based on the US Census Planning Database demonstrate that our methods lead to high-quality predictive models that permit actionable interpretability for different segments of the population. Interestingly, our methods provide significant gains in interpretability without losing in predictive performance to state-of-the-art black-box machine learning methods based on gradient boosting and feedforward neural networks. Our code implementation in python is available at https://github.com/ShibalIbrahim/Additive-Models-with-Structured-Interactions.