 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOONSHOT : A Framework for Multi-Objective Pruning of Vision and Large Language Models
Apr 14, 2026Weight pruning is a common technique for compressing large neural networks. We focus on the challenging post-training one-shot setting, where a pre-trained model is compressed without any retraining. Existing one-shot pruning methods typically optimize a single objective, such as a layer-wise reconstruction loss or a second-order Taylor approximation of the training loss. We highlight that neither objective alone is consistently the most effective across architectures and sparsity levels. Motivated by this insight, we propose MOONSHOT, a general and flexible framework that extends any single-objective pruning method into a multi-objective formulation by jointly optimizing both the layer-wise reconstruction error and second-order Taylor approximation of the training loss. MOONSHOT acts as a wrapper around existing pruning algorithms. To enable this integration while maintaining scalability to billion-parameter models, we propose modeling decisions and introduce an efficient procedure for computing the inverse Hessian, preserving the efficiency of state-of-the-art one-shot pruners. When combined with state-of-the-art pruning methods on Llama-3.2 and Llama-2 models, MOONSHOT reduces C4 perplexity by up to 32.6% at 2:4 sparsity and improves zero-shot mean accuracy across seven classification benchmarks by up to 4.9 points. On Vision Transformers, it improves accuracy on ImageNet-1k by over 5 points at 70% sparsity, and on ResNet-50, it yields a 4-point gain at 90% sparsity.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
An Optimization Framework for Differentially Private Sparse Fine-Tuning
Mar 17, 2025



Differentially private stochastic gradient descent (DP-SGD) is broadly considered to be the gold standard for training and fine-tuning neural networks under differential privacy (DP). With the increasing availability of high-quality pre-trained model checkpoints (e.g., vision and language models), fine-tuning has become a popular strategy. However, despite recent progress in understanding and applying DP-SGD for private transfer learning tasks, significant challenges remain -- most notably, the performance gap between models fine-tuned with DP-SGD and their non-private counterparts. Sparse fine-tuning on private data has emerged as an alternative to full-model fine-tuning; recent work has shown that privately fine-tuning only a small subset of model weights and keeping the rest of the weights fixed can lead to better performance. In this work, we propose a new approach for sparse fine-tuning of neural networks under DP. Existing work on private sparse finetuning often used fixed choice of trainable weights (e.g., updating only the last layer), or relied on public model's weights to choose the subset of weights to modify. Such choice of weights remains suboptimal. In contrast, we explore an optimization-based approach, where our selection method makes use of the private gradient information, while using off the shelf privacy accounting techniques. Our numerical experiments on several computer vision models and datasets show that our selection method leads to better prediction accuracy, compared to full-model private fine-tuning or existing private sparse fine-tuning approaches.
DART: A Principled Approach to Adversarially Robust Unsupervised Domain Adaptation
Feb 16, 2024Distribution shifts and adversarial examples are two major challenges for deploying machine learning models. While these challenges have been studied individually, their combination is an important topic that remains relatively under-explored. In this work, we study the problem of adversarial robustness under a common setting of distribution shift - unsupervised domain adaptation (UDA). Specifically, given a labeled source domain $D_S$ and an unlabeled target domain $D_T$ with related but different distributions, the goal is to obtain an adversarially robust model for $D_T$. The absence of target domain labels poses a unique challenge, as conventional adversarial robustness defenses cannot be directly applied to $D_T$. To address this challenge, we first establish a generalization bound for the adversarial target loss, which consists of (i) terms related to the loss on the data, and (ii) a measure of worst-case domain divergence. Motivated by this bound, we develop a novel unified defense framework called Divergence Aware adveRsarial Training (DART), which can be used in conjunction with a variety of standard UDA methods; e.g., DANN [Ganin and Lempitsky, 2015]. DART is applicable to general threat models, including the popular $\ell_p$-norm model, and does not require heuristic regularizers or architectural changes. We also release DomainRobust: a testbed for evaluating robustness of UDA models to adversarial attacks. DomainRobust consists of 4 multi-domain benchmark datasets (with 46 source-target pairs) and 7 meta-algorithms with a total of 11 variants. Our large-scale experiments demonstrate that on average, DART significantly enhances model robustness on all benchmarks compared to the state of the art, while maintaining competitive standard accuracy. The relative improvement in robustness from DART reaches up to 29.2% on the source-target domain pairs considered.
Scaling Laws for Downstream Task Performance of Large Language Models
Feb 06, 2024



Scaling laws provide important insights that can guide the design of large language models (LLMs). Existing work has primarily focused on studying scaling laws for pretraining (upstream) loss. However, in transfer learning settings, in which LLMs are pretrained on an unsupervised dataset and then finetuned on a downstream task, we often also care about the downstream performance. In this work, we study the scaling behavior in a transfer learning setting, where LLMs are finetuned for machine translation tasks. Specifically, we investigate how the choice of the pretraining data and its size affect downstream performance (translation quality) as judged by two metrics: downstream cross-entropy and BLEU score. Our experiments indicate that the size of the finetuning dataset and the distribution alignment between the pretraining and downstream data significantly influence the scaling behavior. With sufficient alignment, both downstream cross-entropy and BLEU score improve monotonically with more pretraining data. In such cases, we show that it is possible to predict the downstream BLEU score with good accuracy using a log-law. However, there are also cases where moderate misalignment causes the BLEU score to fluctuate or get worse with more pretraining, whereas downstream cross-entropy monotonically improves. By analyzing these observations, we provide new practical insights for choosing appropriate pretraining data.
COMET: Learning Cardinality Constrained Mixture of Experts with Trees and Local Search
Jun 05, 2023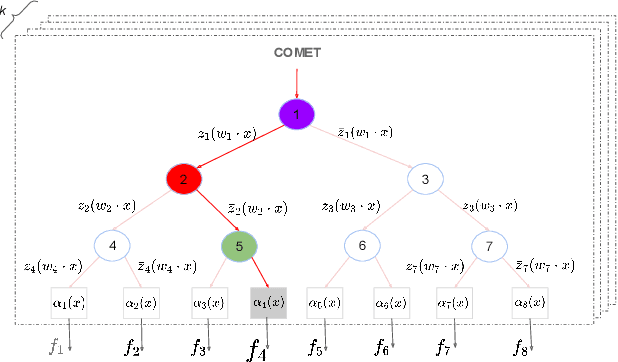
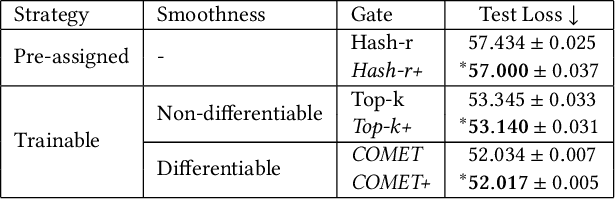
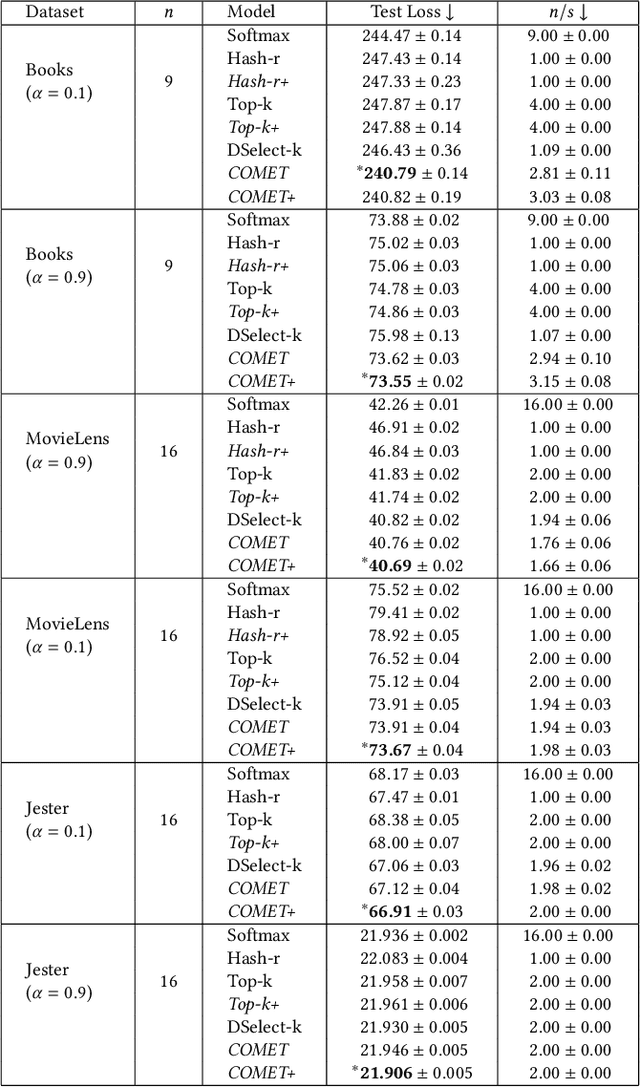
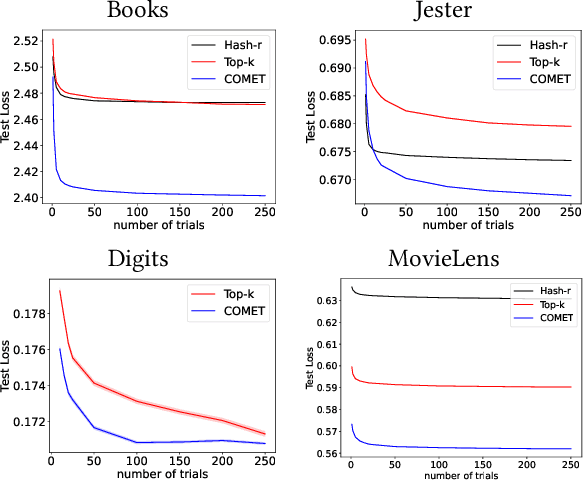
The sparse Mixture-of-Experts (Sparse-MoE) framework efficiently scales up model capacity in various domains, such as natural language processing and vision. Sparse-MoEs select a subset of the "experts" (thus, only a portion of the overall network) for each input sample using a sparse, trainable gate. Existing sparse gates are prone to convergence and performance issues when training with first-order optimization methods. In this paper, we introduce two improvements to current MoE approaches. First, we propose a new sparse gate: COMET, which relies on a novel tree-based mechanism. COMET is differentiable, can exploit sparsity to speed up computation, and outperforms state-of-the-art gates. Second, due to the challenging combinatorial nature of sparse expert selection, first-order methods are typically prone to low-quality solutions. To deal with this challenge, we propose a novel, permutation-based local search method that can complement first-order methods in training any sparse gate, e.g., Hash routing, Top-k, DSelect-k, and COMET. We show that local search can help networks escape bad initializations or solutions. We performed large-scale experiments on various domains, including recommender systems, vision, and natural language processing. On standard vision and recommender systems benchmarks, COMET+ (COMET with local search) achieves up to 13% improvement in ROC AUC over popular gates, e.g., Hash routing and Top-k, and up to 9% over prior differentiable gates e.g., DSelect-k. When Top-k and Hash gates are combined with local search, we see up to $100\times$ reduction in the budget needed for hyperparameter tuning. Moreover, for language modeling, our approach improves over the state-of-the-art MoEBERT model for distilling BERT on 5/7 GLUE benchmarks as well as SQuAD dataset.
How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy
Mar 02, 2023



ML models are ubiquitous in real world applications and are a constant focus of research. At the same time, the community has started to realize the importance of protecting the privacy of ML training data. Differential Privacy (DP) has become a gold standard for making formal statements about data anonymization. However, while some adoption of DP has happened in industry, attempts to apply DP to real world complex ML models are still few and far between. The adoption of DP is hindered by limited practical guidance of what DP protection entails, what privacy guarantees to aim for, and the difficulty of achieving good privacy-utility-computation trade-offs for ML models. Tricks for tuning and maximizing performance are scattered among papers or stored in the heads of practitioners. Furthermore, the literature seems to present conflicting evidence on how and whether to apply architectural adjustments and which components are "safe" to use with DP. This work is a self-contained guide that gives an in-depth overview of the field of DP ML and presents information about achieving the best possible DP ML model with rigorous privacy guarantees. Our target audience is both researchers and practitioners. Researchers interested in DP for ML will benefit from a clear overview of current advances and areas for improvement. We include theory-focused sections that highlight important topics such as privacy accounting and its assumptions, and convergence. For a practitioner, we provide a background in DP theory and a clear step-by-step guide for choosing an appropriate privacy definition and approach, implementing DP training, potentially updating the model architecture, and tuning hyperparameters. For both researchers and practitioners, consistently and fully reporting privacy guarantees is critical, and so we propose a set of specific best practices for stating guarantees.
Fast as CHITA: Neural Network Pruning with Combinatorial Optimization
Feb 28, 2023



The sheer size of modern neural networks makes model serving a serious computational challenge. A popular class of compression techniques overcomes this challenge by pruning or sparsifying the weights of pretrained networks. While useful, these techniques often face serious tradeoffs between computational requirements and compression quality. In this work, we propose a novel optimization-based pruning framework that considers the combined effect of pruning (and updating) multiple weights subject to a sparsity constraint. Our approach, CHITA, extends the classical Optimal Brain Surgeon framework and results in significant improvements in speed, memory, and performance over existing optimization-based approaches for network pruning. CHITA's main workhorse performs combinatorial optimization updates on a memory-friendly representation of local quadratic approximation(s) of the loss function. On a standard benchmark of pretrained models and datasets, CHITA leads to significantly better sparsity-accuracy tradeoffs than competing methods. For example, for MLPNet with only 2% of the weights retained, our approach improves the accuracy by 63% relative to the state of the art. Furthermore, when used in conjunction with fine-tuning SGD steps, our method achieves significant accuracy gains over the state-of-the-art approaches.
Mind the Gap: A Gap-Aware Learning Rate Scheduler for Adversarial Nets
Jan 31, 2023
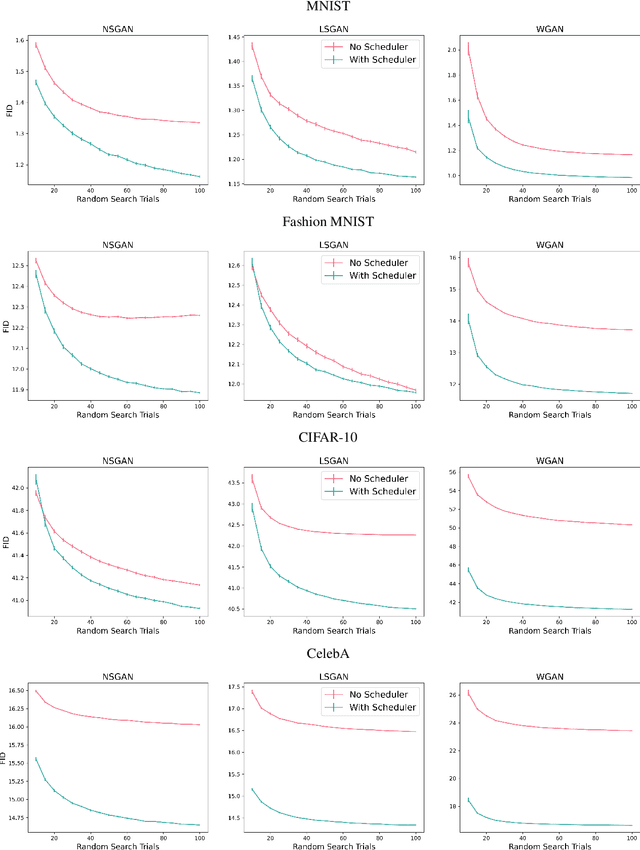


Adversarial nets have proved to be powerful in various domains including generative modeling (GANs), transfer learning, and fairness. However, successfully training adversarial nets using first-order methods remains a major challenge. Typically, careful choices of the learning rates are needed to maintain the delicate balance between the competing networks. In this paper, we design a novel learning rate scheduler that dynamically adapts the learning rate of the adversary to maintain the right balance. The scheduler is driven by the fact that the loss of an ideal adversarial net is a constant known a priori. The scheduler is thus designed to keep the loss of the optimized adversarial net close to that of an ideal network. We run large-scale experiments to study the effectiveness of the scheduler on two popular applications: GANs for image generation and adversarial nets for domain adaptation. Our experiments indicate that adversarial nets trained with the scheduler are less likely to diverge and require significantly less tuning. For example, on CelebA, a GAN with the scheduler requires only one-tenth of the tuning budget needed without a scheduler. Moreover, the scheduler leads to statistically significant improvements in model quality, reaching up to $27\%$ in Frechet Inception Distance for image generation and $3\%$ in test accuracy for domain adaptation.
Benchmarking Robustness to Adversarial Image Obfuscations
Jan 30, 2023



Automated content filtering and moderation is an important tool that allows online platforms to build striving user communities that facilitate cooperation and prevent abuse. Unfortunately, resourceful actors try to bypass automated filters in a bid to post content that violate platform policies and codes of conduct. To reach this goal, these malicious actors may obfuscate policy violating images (e.g. overlay harmful images by carefully selected benign images or visual patterns) to prevent machine learning models from reaching the correct decision. In this paper, we invite researchers to tackle this specific issue and present a new image benchmark. This benchmark, based on ImageNet, simulates the type of obfuscations created by malicious actors. It goes beyond ImageNet-$\textrm{C}$ and ImageNet-$\bar{\textrm{C}}$ by proposing general, drastic, adversarial modifications that preserve the original content intent. It aims to tackle a more common adversarial threat than the one considered by $\ell_p$-norm bounded adversaries. We evaluate 33 pretrained models on the benchmark and train models with different augmentations, architectures and training methods on subsets of the obfuscations to measure generalization. We hope this benchmark will encourage researchers to test their models and methods and try to find new approaches that are more robust to these obfuscations.