 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Recommender Systems with Synthetic Query Generation using Differentially Private Large Language Models
May 10, 2023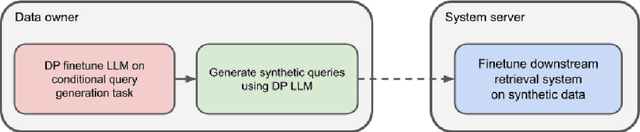
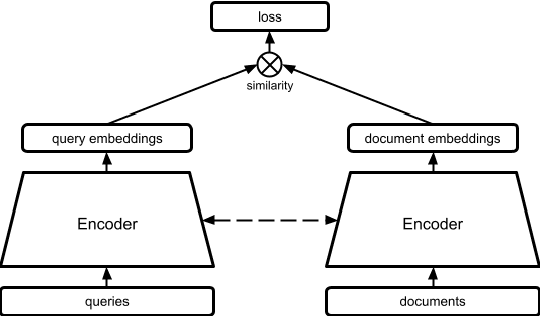

We propose a novel approach for developing privacy-preserving large-scale recommender systems using differentially private (DP) large language models (LLMs) which overcomes certain challenges and limitations in DP training these complex systems. Our method is particularly well suited for the emerging area of LLM-based recommender systems, but can be readily employed for any recommender systems that process representations of natural language inputs. Our approach involves using DP training methods to fine-tune a publicly pre-trained LLM on a query generation task. The resulting model can generate private synthetic queries representative of the original queries which can be freely shared for any downstream non-private recommendation training procedures without incurring any additional privacy cost. We evaluate our method on its ability to securely train effective deep retrieval models, and we observe significant improvements in their retrieval quality without compromising query-level privacy guarantees compared to methods where the retrieval models are directly DP trained.
How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy
Mar 02, 2023



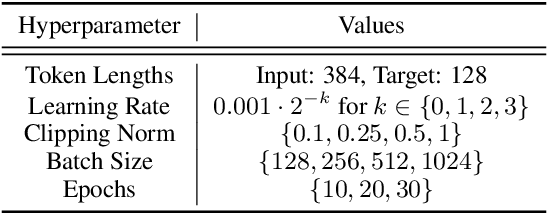
ML models are ubiquitous in real world applications and are a constant focus of research. At the same time, the community has started to realize the importance of protecting the privacy of ML training data. Differential Privacy (DP) has become a gold standard for making formal statements about data anonymization. However, while some adoption of DP has happened in industry, attempts to apply DP to real world complex ML models are still few and far between. The adoption of DP is hindered by limited practical guidance of what DP protection entails, what privacy guarantees to aim for, and the difficulty of achieving good privacy-utility-computation trade-offs for ML models. Tricks for tuning and maximizing performance are scattered among papers or stored in the heads of practitioners. Furthermore, the literature seems to present conflicting evidence on how and whether to apply architectural adjustments and which components are "safe" to use with DP. This work is a self-contained guide that gives an in-depth overview of the field of DP ML and presents information about achieving the best possible DP ML model with rigorous privacy guarantees. Our target audience is both researchers and practitioners. Researchers interested in DP for ML will benefit from a clear overview of current advances and areas for improvement. We include theory-focused sections that highlight important topics such as privacy accounting and its assumptions, and convergence. For a practitioner, we provide a background in DP theory and a clear step-by-step guide for choosing an appropriate privacy definition and approach, implementing DP training, potentially updating the model architecture, and tuning hyperparameters. For both researchers and practitioners, consistently and fully reporting privacy guarantees is critical, and so we propose a set of specific best practices for stating guarantees.
AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation
Jun 08, 2021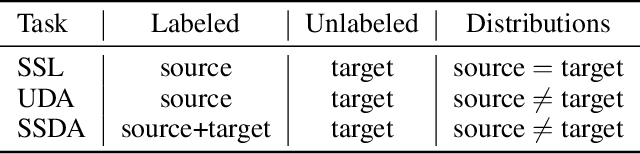
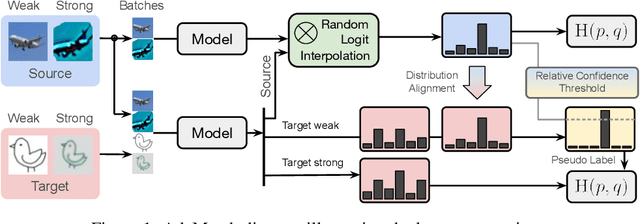

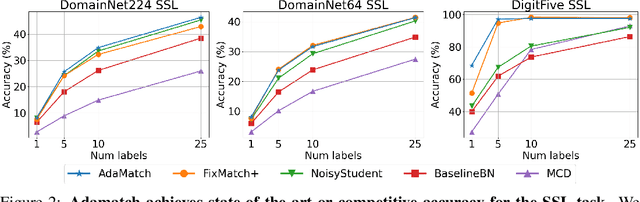
We extend semi-supervised learning to the problem of domain adaptation to learn significantly higher-accuracy models that train on one data distribution and test on a different one. With the goal of generality, we introduce AdaMatch, a method that unifies the tasks of unsupervised domain adaptation (UDA), semi-supervised learning (SSL), and semi-supervised domain adaptation (SSDA). In an extensive experimental study, we compare its behavior with respective state-of-the-art techniques from SSL, SSDA, and UDA on vision classification tasks. We find AdaMatch either matches or significantly exceeds the state-of-the-art in each case using the same hyper-parameters regardless of the dataset or task. For example, AdaMatch nearly doubles the accuracy compared to that of the prior state-of-the-art on the UDA task for DomainNet and even exceeds the accuracy of the prior state-of-the-art obtained with pre-training by 6.4% when AdaMatch is trained completely from scratch. Furthermore, by providing AdaMatch with just one labeled example per class from the target domain (i.e., the SSDA setting), we increase the target accuracy by an additional 6.1%, and with 5 labeled examples, by 13.6%.
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
Jan 21, 2020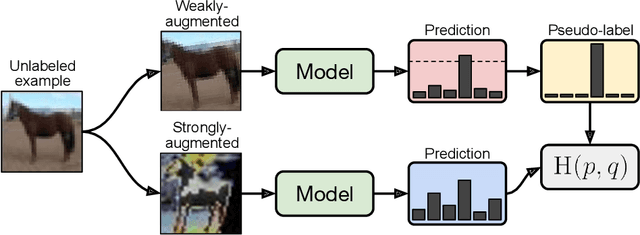
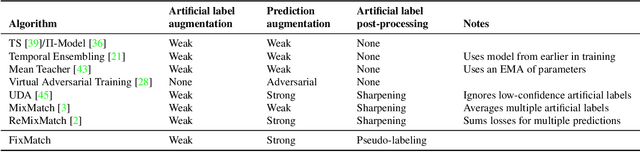
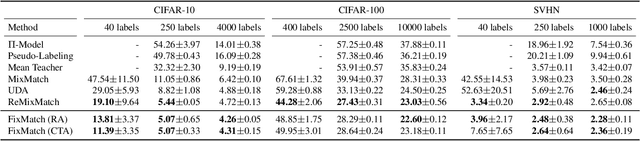

Semi-supervised learning (SSL) provides an effective means of leveraging unlabeled data to improve a model's performance. In this paper, we demonstrate the power of a simple combination of two common SSL methods: consistency regularization and pseudo-labeling. Our algorithm, FixMatch, first generates pseudo-labels using the model's predictions on weakly-augmented unlabeled images. For a given image, the pseudo-label is only retained if the model produces a high-confidence prediction. The model is then trained to predict the pseudo-label when fed a strongly-augmented version of the same image. Despite its simplicity, we show that FixMatch achieves state-of-the-art performance across a variety of standard semi-supervised learning benchmarks, including 94.93% accuracy on CIFAR-10 with 250 labels and 88.61% accuracy with 40 -- just 4 labels per class. Since FixMatch bears many similarities to existing SSL methods that achieve worse performance, we carry out an extensive ablation study to tease apart the experimental factors that are most important to FixMatch's success. We make our code available at https://github.com/google-research/fixmatch.
ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring
Nov 21, 2019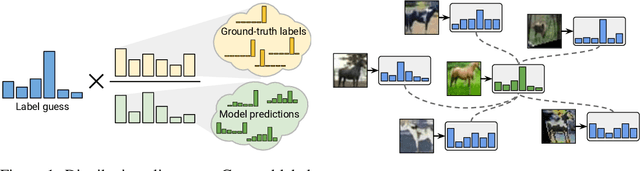
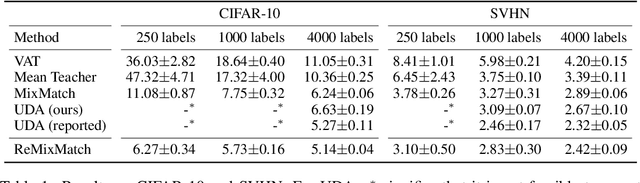
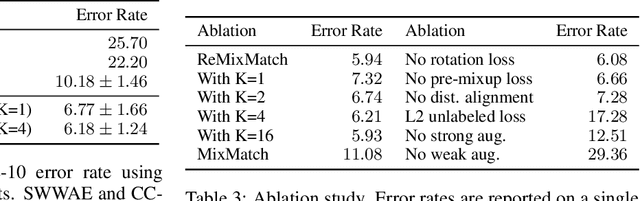
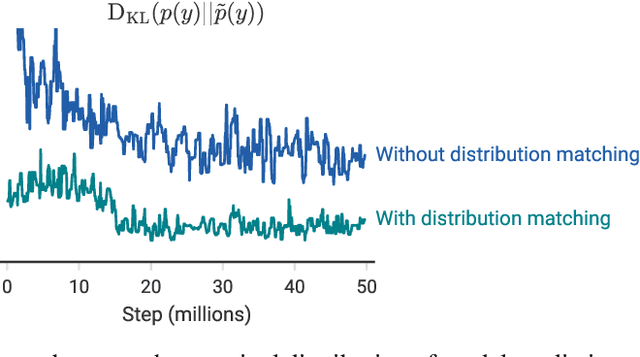
We improve the recently-proposed "MixMatch" semi-supervised learning algorithm by introducing two new techniques: distribution alignment and augmentation anchoring. Distribution alignment encourages the marginal distribution of predictions on unlabeled data to be close to the marginal distribution of ground-truth labels. Augmentation anchoring feeds multiple strongly augmented versions of an input into the model and encourages each output to be close to the prediction for a weakly-augmented version of the same input. To produce strong augmentations, we propose a variant of AutoAugment which learns the augmentation policy while the model is being trained. Our new algorithm, dubbed ReMixMatch, is significantly more data-efficient than prior work, requiring between $5\times$ and $16\times$ less data to reach the same accuracy. For example, on CIFAR-10 with 250 labeled examples we reach $93.73\%$ accuracy (compared to MixMatch's accuracy of $93.58\%$ with $4{,}000$ examples) and a median accuracy of $84.92\%$ with just four labels per class. We make our code and data open-source at https://github.com/google-research/remixmatch.
High-Fidelity Extraction of Neural Network Models
Sep 03, 2019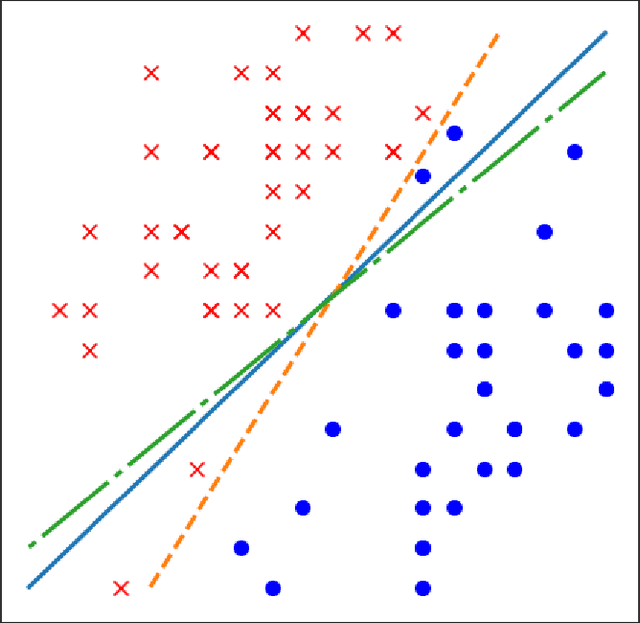
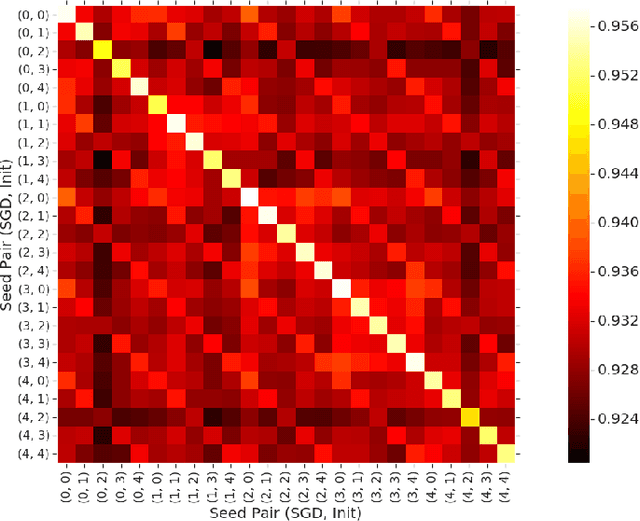
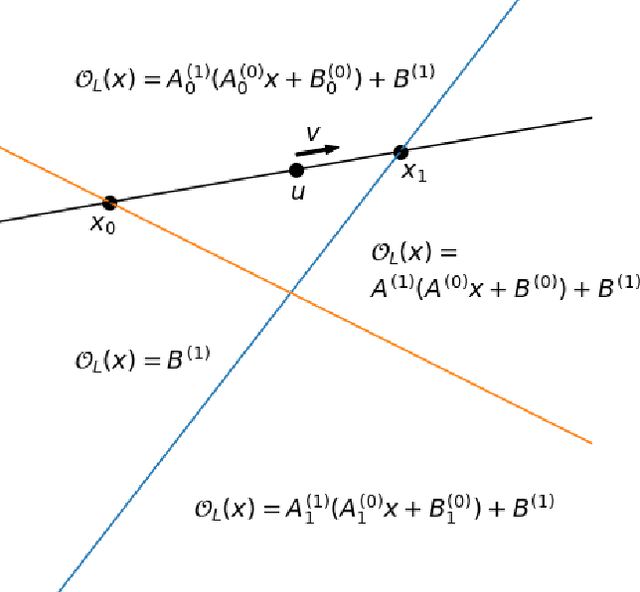
Model extraction allows an adversary to steal a copy of a remotely deployed machine learning model given access to its predictions. Adversaries are motivated to mount such attacks for a variety of reasons, ranging from reducing their computational costs, to eliminating the need to collect expensive training data, to obtaining a copy of a model in order to find adversarial examples, perform membership inference, or model inversion attacks. In this paper, we taxonomize the space of model extraction attacks around two objectives: \emph{accuracy}, i.e., performing well on the underlying learning task, and \emph{fidelity}, i.e., matching the predictions of the remote victim classifier on any input. To extract a high-accuracy model, we develop a learning-based attack which exploits the victim to supervise the training of an extracted model. Through analytical and empirical arguments, we then explain the inherent limitations that prevent any learning-based strategy from extracting a truly high-fidelity model---i.e., extracting a functionally-equivalent model whose predictions are identical to those of the victim model on all possible inputs. Addressing these limitations, we expand on prior work to develop the first practical functionally-equivalent extraction attack for direct extraction (i.e., without training) of a model's weights. We perform experiments both on academic datasets and a state-of-the-art image classifier trained with 1 billion proprietary images. In addition to broadening the scope of model extraction research, our work demonstrates the practicality of model extraction attacks against production-grade systems.
Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
May 22, 2018
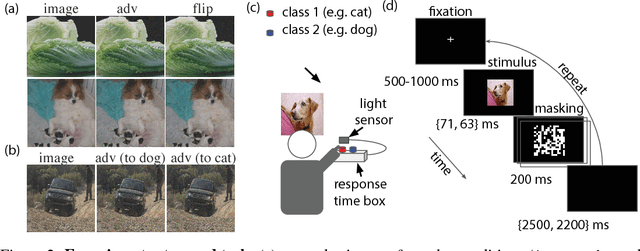
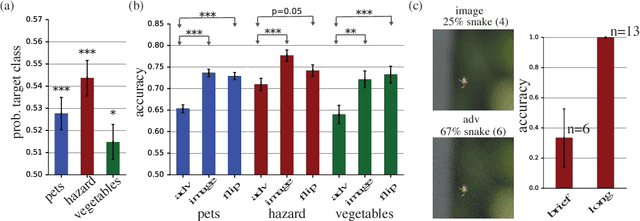
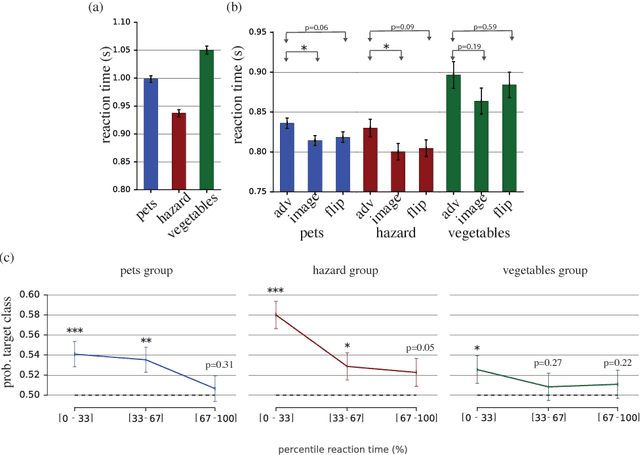
Machine learning models are vulnerable to adversarial examples: small changes to images can cause computer vision models to make mistakes such as identifying a school bus as an ostrich. However, it is still an open question whether humans are prone to similar mistakes. Here, we address this question by leveraging recent techniques that transfer adversarial examples from computer vision models with known parameters and architecture to other models with unknown parameters and architecture, and by matching the initial processing of the human visual system. We find that adversarial examples that strongly transfer across computer vision models influence the classifications made by time-limited human observers.
Large-Scale Evolution of Image Classifiers
Jun 11, 2017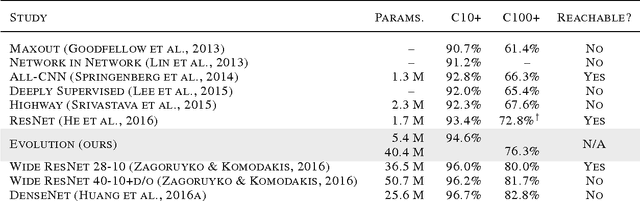
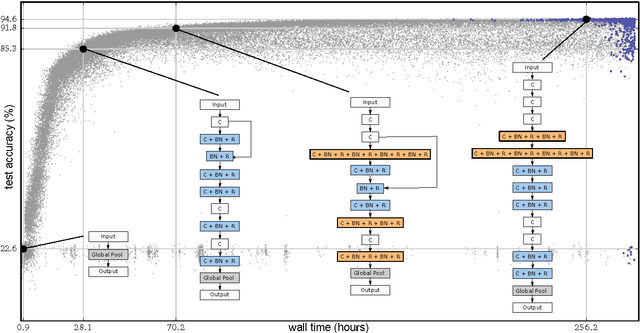
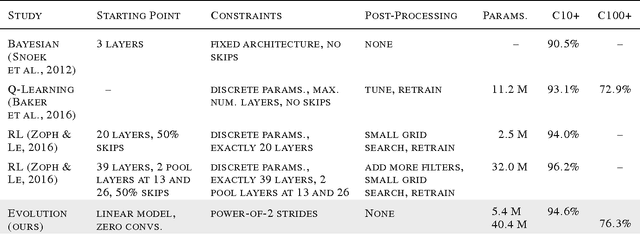
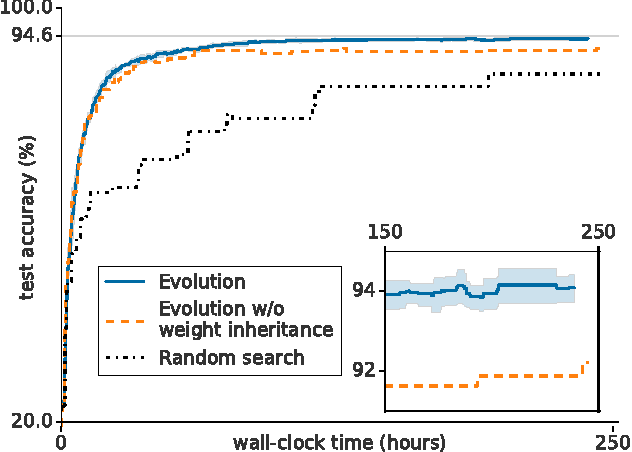
Neural networks have proven effective at solving difficult problems but designing their architectures can be challenging, even for image classification problems alone. Our goal is to minimize human participation, so we employ evolutionary algorithms to discover such networks automatically. Despite significant computational requirements, we show that it is now possible to evolve models with accuracies within the range of those published in the last year. Specifically, we employ simple evolutionary techniques at unprecedented scales to discover models for the CIFAR-10 and CIFAR-100 datasets, starting from trivial initial conditions and reaching accuracies of 94.6% (95.6% for ensemble) and 77.0%, respectively. To do this, we use novel and intuitive mutation operators that navigate large search spaces; we stress that no human participation is required once evolution starts and that the output is a fully-trained model. Throughout this work, we place special emphasis on the repeatability of results, the variability in the outcomes and the computational requirements.