 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Finetuner's Fallacy: When to Pretrain with Your Finetuning Data
Mar 17, 2026Real-world model deployments demand strong performance on narrow domains where data is often scarce. Typically, practitioners finetune models to specialize them, but this risks overfitting to the domain and forgetting general knowledge. We study a simple strategy, specialized pretraining (SPT), where a small domain dataset, typically reserved for finetuning, is repeated starting from pretraining as a fraction of the total tokens. Across three specialized domains (ChemPile, MusicPile, and ProofPile), SPT improves domain performance and preserves general capabilities after finetuning compared to standard pretraining. In our experiments, SPT reduces the pretraining tokens needed to reach a given domain performance by up to 1.75x. These gains grow when the target domain is underrepresented in the pretraining corpus: on domains far from web text, a 1B SPT model outperforms a 3B standard pretrained model. Beyond these empirical gains, we derive overfitting scaling laws to guide practitioners in selecting the optimal domain-data repetition for a given pretraining compute budget. Our observations reveal the finetuner's fallacy: while finetuning may appear to be the cheapest path to domain adaptation, introducing specialized domain data during pretraining stretches its utility. SPT yields better specialized domain performance (via reduced overfitting across repeated exposures) and better general domain performance (via reduced forgetting during finetuning), ultimately achieving stronger results with fewer parameters and less total compute when amortized over inference. To get the most out of domain data, incorporate it as early in training as possible.
ÜberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset
Feb 16, 2026Multilinguality is a core capability for modern foundation models, yet training high-quality multilingual models remains challenging due to uneven data availability across languages. A further challenge is the performance interference that can arise from joint multilingual training, commonly referred to as the "curse of multilinguality". We study multilingual data curation across thirteen languages and find that many reported regressions are not inherent to multilingual scaling but instead stem from correctable deficiencies in data quality and composition rather than fundamental capacity limits. In controlled bilingual experiments, improving data quality for any single language benefits others: curating English improves non-English performance in 12 of 13 languages, while curating non-English yields reciprocal improvements in English. Bespoke per-language curation produces substantially larger within-language improvements. Extending these findings to large-scale general-purpose training mixtures, we show that curated multilingual allocations comprising under 8% of total tokens remain remarkably effective. We operationalize this approach within an effort that produced a 20T-token pretraining corpus derived entirely from public sources. Models with 3B and 8B parameters trained on a 1T-token random subset achieve competitive multilingual accuracy with 4-10x fewer training FLOPs than strong public baselines, establishing a new Pareto frontier in multilingual performance versus compute. Moreover, these benefits extend to frontier model scale: the 20T-token corpus served as part of the pretraining dataset for Trinity Large (400B/A13B), which exhibits strong multilingual performance relative to its training FLOPs. These results show that targeted, per-language data curation mitigates multilingual interference and enables compute-efficient multilingual scaling.
Robust Offline Policy Learning with Observational Data from Multiple Sources
Oct 11, 2024

We consider the problem of using observational bandit feedback data from multiple heterogeneous data sources to learn a personalized decision policy that robustly generalizes across diverse target settings. To achieve this, we propose a minimax regret optimization objective to ensure uniformly low regret under general mixtures of the source distributions. We develop a policy learning algorithm tailored to this objective, combining doubly robust offline policy evaluation techniques and no-regret learning algorithms for minimax optimization. Our regret analysis shows that this approach achieves the minimal worst-case mixture regret up to a moderated vanishing rate of the total data across all sources. Our analysis, extensions, and experimental results demonstrate the benefits of this approach for learning robust decision policies from multiple data sources.
Federated Offline Policy Learning with Heterogeneous Observational Data
May 21, 2023
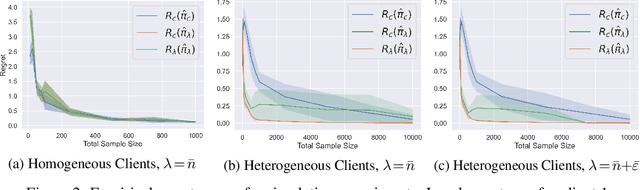
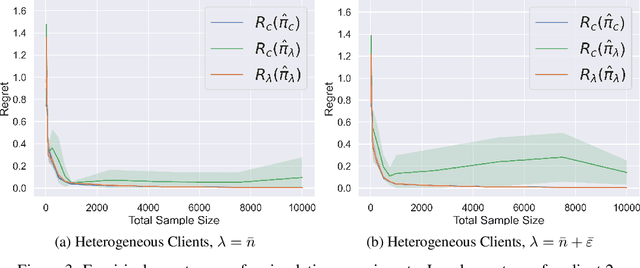
We consider the problem of learning personalized decision policies on observational data from heterogeneous data sources. Moreover, we examine this problem in the federated setting where a central server aims to learn a policy on the data distributed across the heterogeneous sources without exchanging their raw data. We present a federated policy learning algorithm based on aggregation of local policies trained with doubly robust offline policy evaluation and learning strategies. We provide a novel regret analysis for our approach that establishes a finite-sample upper bound on a notion of global regret across a distribution of clients. In addition, for any individual client, we establish a corresponding local regret upper bound characterized by the presence of distribution shift relative to all other clients. We support our theoretical findings with experimental results. Our analysis and experiments provide insights into the value of heterogeneous client participation in federation for policy learning in heterogeneous settings.
Privacy-Preserving Recommender Systems with Synthetic Query Generation using Differentially Private Large Language Models
May 10, 2023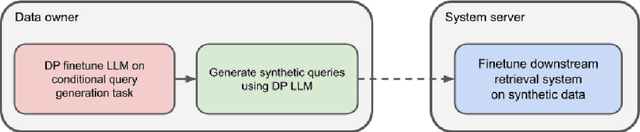
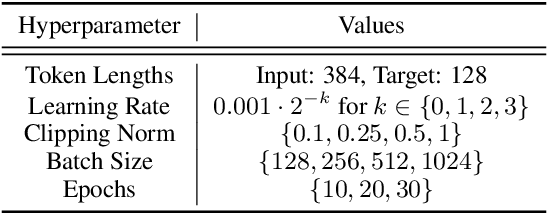
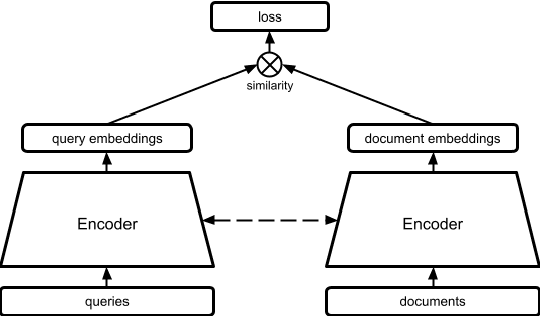

We propose a novel approach for developing privacy-preserving large-scale recommender systems using differentially private (DP) large language models (LLMs) which overcomes certain challenges and limitations in DP training these complex systems. Our method is particularly well suited for the emerging area of LLM-based recommender systems, but can be readily employed for any recommender systems that process representations of natural language inputs. Our approach involves using DP training methods to fine-tune a publicly pre-trained LLM on a query generation task. The resulting model can generate private synthetic queries representative of the original queries which can be freely shared for any downstream non-private recommendation training procedures without incurring any additional privacy cost. We evaluate our method on its ability to securely train effective deep retrieval models, and we observe significant improvements in their retrieval quality without compromising query-level privacy guarantees compared to methods where the retrieval models are directly DP trained.
Flexible and Efficient Contextual Bandits with Heterogeneous Treatment Effect Oracle
Mar 30, 2022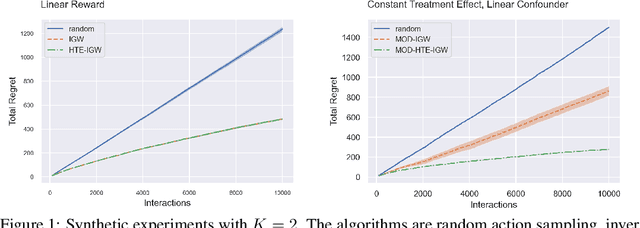
Many popular contextual bandit algorithms estimate reward models to inform decision making. However, true rewards can contain action-independent redundancies that are not relevant for decision making and only increase the statistical complexity of accurate estimation. It is sufficient and more data-efficient to estimate the simplest function that explains the reward differences between actions, that is, the heterogeneous treatment effect, commonly understood to be more structured and simpler than the reward. Motivated by this observation, building on recent work on oracle-based algorithms, we design a statistically optimal and computationally efficient algorithm using heterogeneous treatment effect estimation oracles. Our results provide the first universal reduction of contextual bandits to a general-purpose heterogeneous treatment effect estimation method. We show that our approach is more robust to model misspecification than reward estimation methods based on squared error regression oracles. Experimentally, we show the benefits of heterogeneous treatment effect estimation in contextual bandits over reward estimation.