 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Search as a Baseline for Sparse Neural Network Architecture Search
Mar 14, 2024

Sparse neural networks have shown similar or better generalization performance than their dense counterparts while having higher parameter efficiency. This has motivated a number of works to learn or search for high performing sparse networks. While reports of task performance or efficiency gains are impressive, standard baselines are lacking leading to poor comparability and unreliable reproducibility across methods. In this work, we propose Random Search as a baseline algorithm for finding good sparse configurations and study its performance. We apply Random Search on the node space of an overparameterized network with the goal of finding better initialized sparse sub-networks that are positioned more advantageously in the loss landscape. We record the post-training performances of the found sparse networks and at various levels of sparsity, and compare against both their fully connected parent networks and random sparse configurations at the same sparsity levels. First, we demonstrate performance at different levels of sparsity and highlight that a significant level of performance can still be preserved even when the network is highly sparse. Second, we observe that for this sparse architecture search task, initialized sparse networks found by Random Search neither perform better nor converge more efficiently than their random counterparts. Thus we conclude that Random Search may be viewed as a reasonable neutral baseline for sparsity search methods.
Privacy-Preserving Recommender Systems with Synthetic Query Generation using Differentially Private Large Language Models
May 10, 2023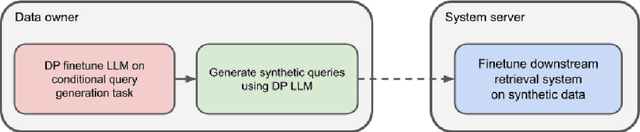
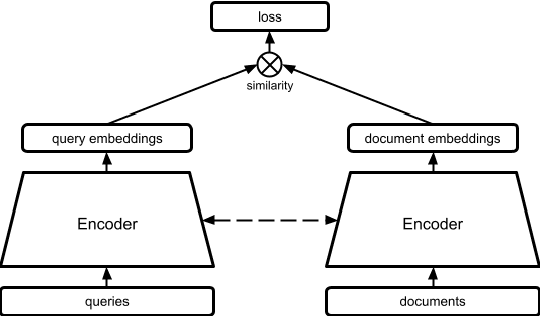

We propose a novel approach for developing privacy-preserving large-scale recommender systems using differentially private (DP) large language models (LLMs) which overcomes certain challenges and limitations in DP training these complex systems. Our method is particularly well suited for the emerging area of LLM-based recommender systems, but can be readily employed for any recommender systems that process representations of natural language inputs. Our approach involves using DP training methods to fine-tune a publicly pre-trained LLM on a query generation task. The resulting model can generate private synthetic queries representative of the original queries which can be freely shared for any downstream non-private recommendation training procedures without incurring any additional privacy cost. We evaluate our method on its ability to securely train effective deep retrieval models, and we observe significant improvements in their retrieval quality without compromising query-level privacy guarantees compared to methods where the retrieval models are directly DP trained.