 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Extraction of Neural Network Models
Paper and Code
Sep 03, 2019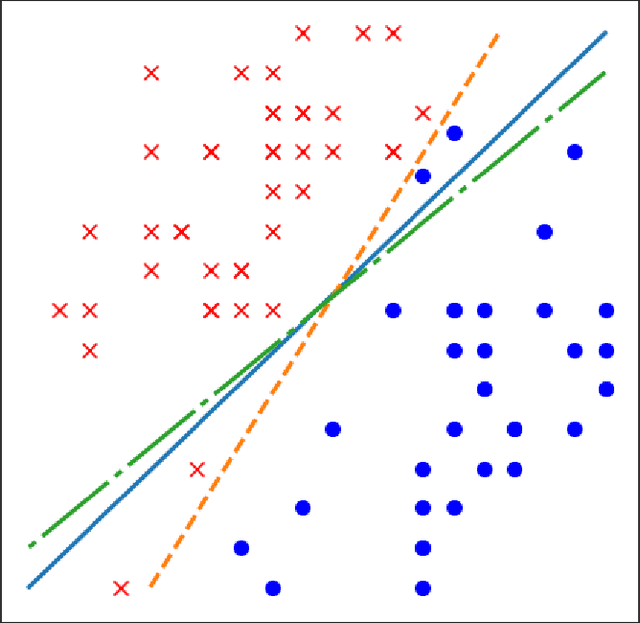
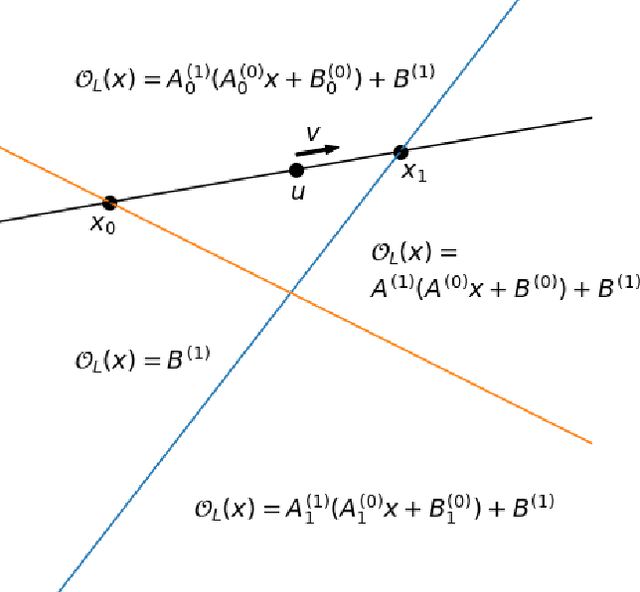
Model extraction allows an adversary to steal a copy of a remotely deployed machine learning model given access to its predictions. Adversaries are motivated to mount such attacks for a variety of reasons, ranging from reducing their computational costs, to eliminating the need to collect expensive training data, to obtaining a copy of a model in order to find adversarial examples, perform membership inference, or model inversion attacks. In this paper, we taxonomize the space of model extraction attacks around two objectives: \emph{accuracy}, i.e., performing well on the underlying learning task, and \emph{fidelity}, i.e., matching the predictions of the remote victim classifier on any input. To extract a high-accuracy model, we develop a learning-based attack which exploits the victim to supervise the training of an extracted model. Through analytical and empirical arguments, we then explain the inherent limitations that prevent any learning-based strategy from extracting a truly high-fidelity model---i.e., extracting a functionally-equivalent model whose predictions are identical to those of the victim model on all possible inputs. Addressing these limitations, we expand on prior work to develop the first practical functionally-equivalent extraction attack for direct extraction (i.e., without training) of a model's weights. We perform experiments both on academic datasets and a state-of-the-art image classifier trained with 1 billion proprietary images. In addition to broadening the scope of model extraction research, our work demonstrates the practicality of model extraction attacks against production-grade systems.