 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360Anything: Geometry-Free Lifting of Images and Videos to 360°
Jan 22, 2026Lifting perspective images and videos to 360° panoramas enables immersive 3D world generation. Existing approaches often rely on explicit geometric alignment between the perspective and the equirectangular projection (ERP) space. Yet, this requires known camera metadata, obscuring the application to in-the-wild data where such calibration is typically absent or noisy. We propose 360Anything, a geometry-free framework built upon pre-trained diffusion transformers. By treating the perspective input and the panorama target simply as token sequences, 360Anything learns the perspective-to-equirectangular mapping in a purely data-driven way, eliminating the need for camera information. Our approach achieves state-of-the-art performance on both image and video perspective-to-360° generation, outperforming prior works that use ground-truth camera information. We also trace the root cause of the seam artifacts at ERP boundaries to zero-padding in the VAE encoder, and introduce Circular Latent Encoding to facilitate seamless generation. Finally, we show competitive results in zero-shot camera FoV and orientation estimation benchmarks, demonstrating 360Anything's deep geometric understanding and broader utility in computer vision tasks. Additional results are available at https://360anything.github.io/.
RoMo: Robust Motion Segmentation Improves Structure from Motion
Nov 27, 2024
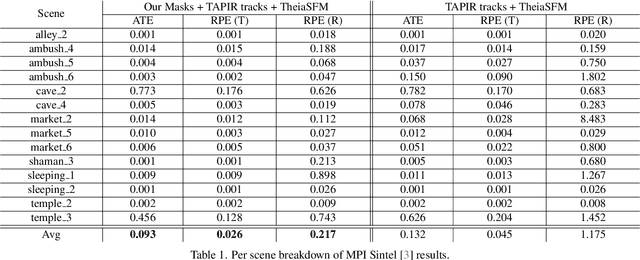


There has been extensive progress in the reconstruction and generation of 4D scenes from monocular casually-captured video. While these tasks rely heavily on known camera poses, the problem of finding such poses using structure-from-motion (SfM) often depends on robustly separating static from dynamic parts of a video. The lack of a robust solution to this problem limits the performance of SfM camera-calibration pipelines. We propose a novel approach to video-based motion segmentation to identify the components of a scene that are moving w.r.t. a fixed world frame. Our simple but effective iterative method, RoMo, combines optical flow and epipolar cues with a pre-trained video segmentation model. It outperforms unsupervised baselines for motion segmentation as well as supervised baselines trained from synthetic data. More importantly, the combination of an off-the-shelf SfM pipeline with our segmentation masks establishes a new state-of-the-art on camera calibration for scenes with dynamic content, outperforming existing methods by a substantial margin.
High-Resolution Frame Interpolation with Patch-based Cascaded Diffusion
Oct 15, 2024Despite the recent progress, existing frame interpolation methods still struggle with processing extremely high resolution input and handling challenging cases such as repetitive textures, thin objects, and large motion. To address these issues, we introduce a patch-based cascaded pixel diffusion model for frame interpolation, HiFI, that excels in these scenarios while achieving competitive performance on standard benchmarks. Cascades, which generate a series of images from low- to high-resolution, can help significantly with large or complex motion that require both global context for a coarse solution and detailed context for high resolution output. However, contrary to prior work on cascaded diffusion models which perform diffusion on increasingly large resolutions, we use a single model that always performs diffusion at the same resolution and upsamples by processing patches of the inputs and the prior solution. We show that this technique drastically reduces memory usage at inference time and also allows us to use a single model at test time, solving both frame interpolation and spatial up-sampling, saving training cost. We show that HiFI helps significantly with high resolution and complex repeated textures that require global context. HiFI demonstrates comparable or beyond state-of-the-art performance on multiple benchmarks (Vimeo, Xiph, X-Test, SEPE-8K). On our newly introduced dataset that focuses on particularly challenging cases, HiFI also significantly outperforms other baselines on these cases. Please visit our project page for video results: https://hifi-diffusion.github.io
Controlling Space and Time with Diffusion Models
Jul 10, 2024We present 4DiM, a cascaded diffusion model for 4D novel view synthesis (NVS), conditioned on one or more images of a general scene, and a set of camera poses and timestamps. To overcome challenges due to limited availability of 4D training data, we advocate joint training on 3D (with camera pose), 4D (pose+time) and video (time but no pose) data and propose a new architecture that enables the same. We further advocate the calibration of SfM posed data using monocular metric depth estimators for metric scale camera control. For model evaluation, we introduce new metrics to enrich and overcome shortcomings of current evaluation schemes, demonstrating state-of-the-art results in both fidelity and pose control compared to existing diffusion models for 3D NVS, while at the same time adding the ability to handle temporal dynamics. 4DiM is also used for improved panorama stitching, pose-conditioned video to video translation, and several other tasks. For an overview see https://4d-diffusion.github.io
Zero-Shot Metric Depth with a Field-of-View Conditioned Diffusion Model
Dec 20, 2023While methods for monocular depth estimation have made significant strides on standard benchmarks, zero-shot metric depth estimation remains unsolved. Challenges include the joint modeling of indoor and outdoor scenes, which often exhibit significantly different distributions of RGB and depth, and the depth-scale ambiguity due to unknown camera intrinsics. Recent work has proposed specialized multi-head architectures for jointly modeling indoor and outdoor scenes. In contrast, we advocate a generic, task-agnostic diffusion model, with several advancements such as log-scale depth parameterization to enable joint modeling of indoor and outdoor scenes, conditioning on the field-of-view (FOV) to handle scale ambiguity and synthetically augmenting FOV during training to generalize beyond the limited camera intrinsics in training datasets. Furthermore, by employing a more diverse training mixture than is common, and an efficient diffusion parameterization, our method, DMD (Diffusion for Metric Depth) achieves a 25\% reduction in relative error (REL) on zero-shot indoor and 33\% reduction on zero-shot outdoor datasets over the current SOTA using only a small number of denoising steps. For an overview see https://diffusion-vision.github.io/dmd
NeRFiller: Completing Scenes via Generative 3D Inpainting
Dec 07, 2023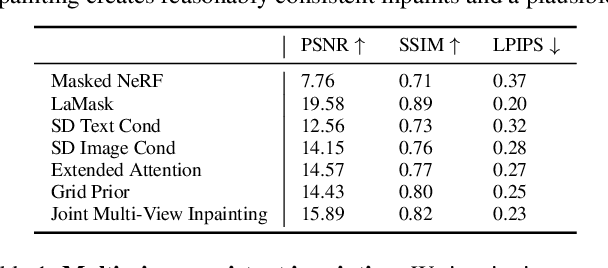

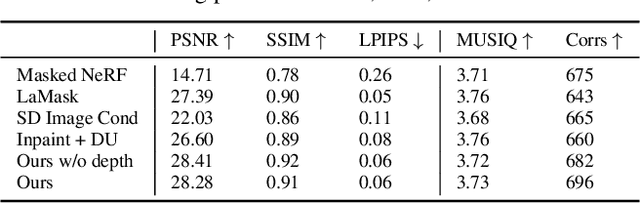

We propose NeRFiller, an approach that completes missing portions of a 3D capture via generative 3D inpainting using off-the-shelf 2D visual generative models. Often parts of a captured 3D scene or object are missing due to mesh reconstruction failures or a lack of observations (e.g., contact regions, such as the bottom of objects, or hard-to-reach areas). We approach this challenging 3D inpainting problem by leveraging a 2D inpainting diffusion model. We identify a surprising behavior of these models, where they generate more 3D consistent inpaints when images form a 2$\times$2 grid, and show how to generalize this behavior to more than four images. We then present an iterative framework to distill these inpainted regions into a single consistent 3D scene. In contrast to related works, we focus on completing scenes rather than deleting foreground objects, and our approach does not require tight 2D object masks or text. We compare our approach to relevant baselines adapted to our setting on a variety of scenes, where NeRFiller creates the most 3D consistent and plausible scene completions. Our project page is at https://ethanweber.me/nerfiller.
The Surprising Effectiveness of Diffusion Models for Optical Flow and Monocular Depth Estimation
Jun 02, 2023Denoising diffusion probabilistic models have transformed image generation with their impressive fidelity and diversity. We show that they also excel in estimating optical flow and monocular depth, surprisingly, without task-specific architectures and loss functions that are predominant for these tasks. Compared to the point estimates of conventional regression-based methods, diffusion models also enable Monte Carlo inference, e.g., capturing uncertainty and ambiguity in flow and depth. With self-supervised pre-training, the combined use of synthetic and real data for supervised training, and technical innovations (infilling and step-unrolled denoising diffusion training) to handle noisy-incomplete training data, and a simple form of coarse-to-fine refinement, one can train state-of-the-art diffusion models for depth and optical flow estimation. Extensive experiments focus on quantitative performance against benchmarks, ablations, and the model's ability to capture uncertainty and multimodality, and impute missing values. Our model, DDVM (Denoising Diffusion Vision Model), obtains a state-of-the-art relative depth error of 0.074 on the indoor NYU benchmark and an Fl-all outlier rate of 3.26\% on the KITTI optical flow benchmark, about 25\% better than the best published method. For an overview see https://diffusion-vision.github.io.
Monocular Depth Estimation using Diffusion Models
Feb 28, 2023
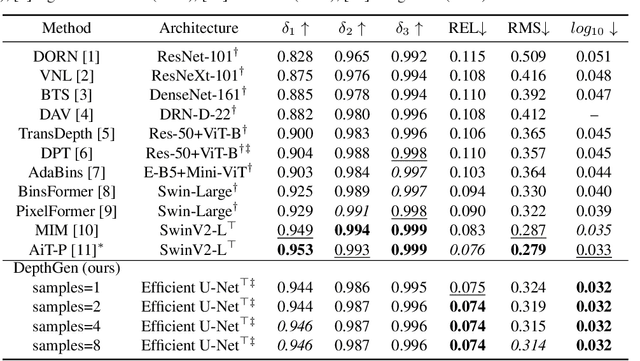
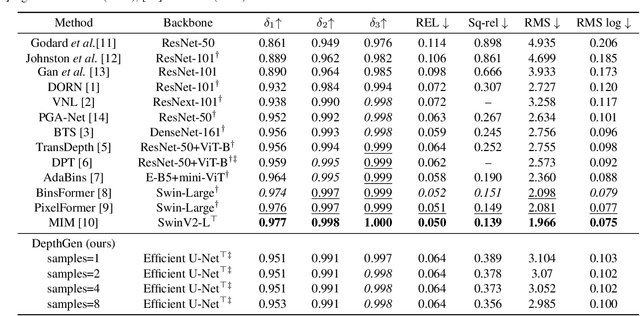

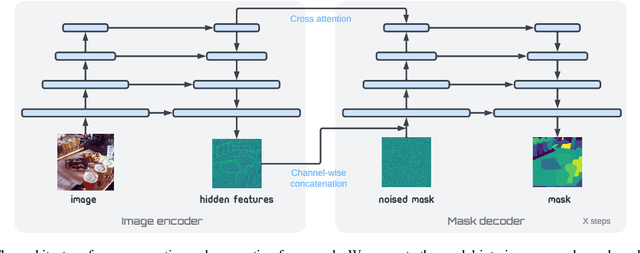
We formulate monocular depth estimation using denoising diffusion models, inspired by their recent successes in high fidelity image generation. To that end, we introduce innovations to address problems arising due to noisy, incomplete depth maps in training data, including step-unrolled denoising diffusion, an $L_1$ loss, and depth infilling during training. To cope with the limited availability of data for supervised training, we leverage pre-training on self-supervised image-to-image translation tasks. Despite the simplicity of the approach, with a generic loss and architecture, our DepthGen model achieves SOTA performance on the indoor NYU dataset, and near SOTA results on the outdoor KITTI dataset. Further, with a multimodal posterior, DepthGen naturally represents depth ambiguity (e.g., from transparent surfaces), and its zero-shot performance combined with depth imputation, enable a simple but effective text-to-3D pipeline. Project page: https://depth-gen.github.io
A Generalist Framework for Panoptic Segmentation of Images and Videos
Oct 12, 2022
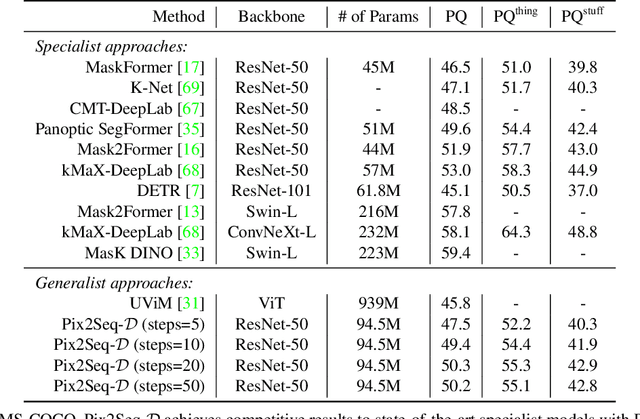
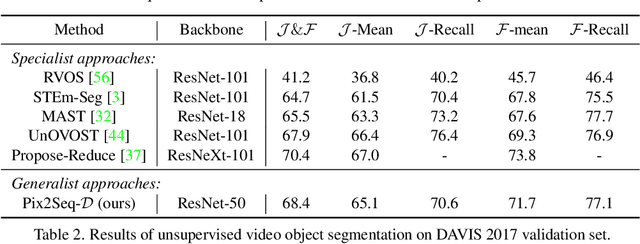
Panoptic segmentation assigns semantic and instance ID labels to every pixel of an image. As permutations of instance IDs are also valid solutions, the task requires learning of high-dimensional one-to-many mapping. As a result, state-of-the-art approaches use customized architectures and task-specific loss functions. We formulate panoptic segmentation as a discrete data generation problem, without relying on inductive bias of the task. A diffusion model based on analog bits is used to model panoptic masks, with a simple, generic architecture and loss function. By simply adding past predictions as a conditioning signal, our method is capable of modeling video (in a streaming setting) and thereby learns to track object instances automatically. With extensive experiments, we demonstrate that our generalist approach can perform competitively to state-of-the-art specialist methods in similar settings.
A Unified Sequence Interface for Vision Tasks
Jun 15, 2022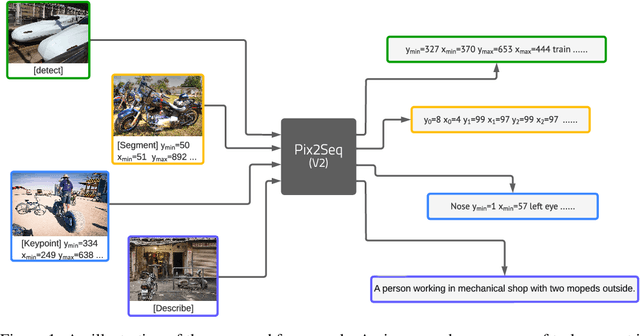
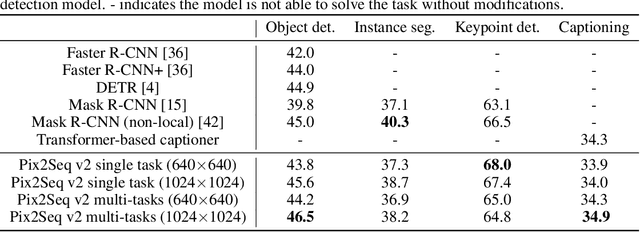
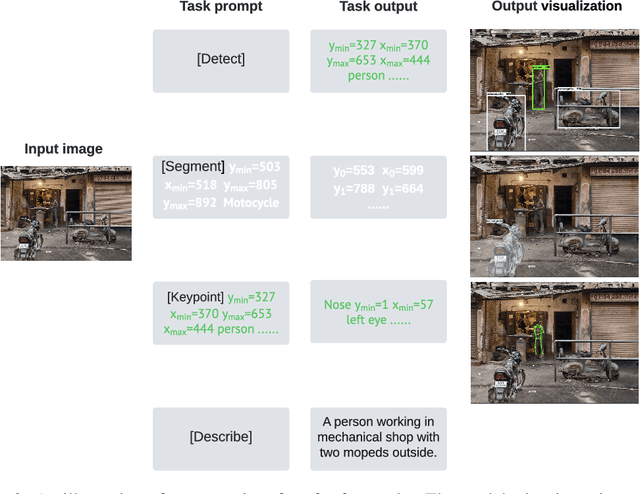

While language tasks are naturally expressed in a single, unified, modeling framework, i.e., generating sequences of tokens, this has not been the case in computer vision. As a result, there is a proliferation of distinct architectures and loss functions for different vision tasks. In this work we show that a diverse set of "core" computer vision tasks can also be unified if formulated in terms of a shared pixel-to-sequence interface. We focus on four tasks, namely, object detection, instance segmentation, keypoint detection, and image captioning, all with diverse types of outputs, e.g., bounding boxes or dense masks. Despite that, by formulating the output of each task as a sequence of discrete tokens with a unified interface, we show that one can train a neural network with a single model architecture and loss function on all these tasks, with no task-specific customization. To solve a specific task, we use a short prompt as task description, and the sequence output adapts to the prompt so it can produce task-specific output. We show that such a model can achieve competitive performance compared to well-established task-specific models.