 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen Video: High Definition Video Generation with Diffusion Models
Oct 05, 2022
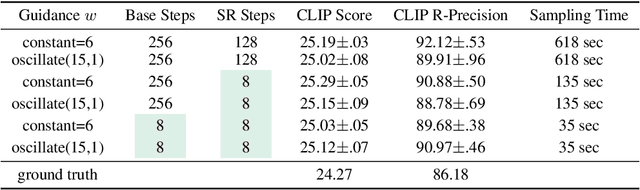
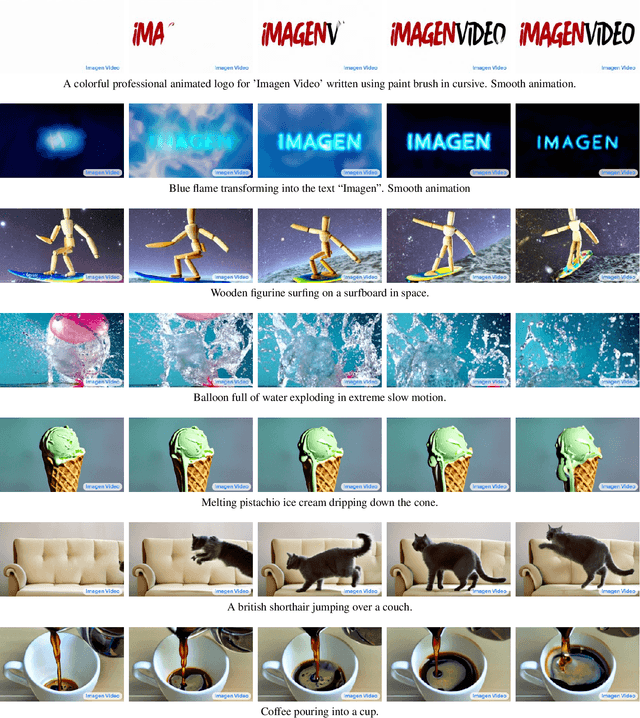

We present Imagen Video, a text-conditional video generation system based on a cascade of video diffusion models. Given a text prompt, Imagen Video generates high definition videos using a base video generation model and a sequence of interleaved spatial and temporal video super-resolution models. We describe how we scale up the system as a high definition text-to-video model including design decisions such as the choice of fully-convolutional temporal and spatial super-resolution models at certain resolutions, and the choice of the v-parameterization of diffusion models. In addition, we confirm and transfer findings from previous work on diffusion-based image generation to the video generation setting. Finally, we apply progressive distillation to our video models with classifier-free guidance for fast, high quality sampling. We find Imagen Video not only capable of generating videos of high fidelity, but also having a high degree of controllability and world knowledge, including the ability to generate diverse videos and text animations in various artistic styles and with 3D object understanding. See https://imagen.research.google/video/ for samples.
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
May 23, 2022

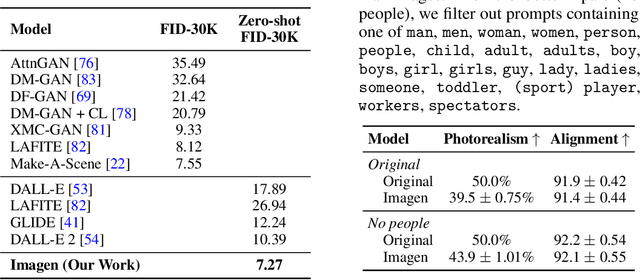
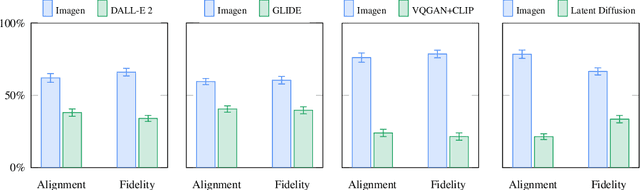
We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. Our key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model. Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment. To assess text-to-image models in greater depth, we introduce DrawBench, a comprehensive and challenging benchmark for text-to-image models. With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2, and find that human raters prefer Imagen over other models in side-by-side comparisons, both in terms of sample quality and image-text alignment. See https://imagen.research.google/ for an overview of the results.
Deblurring via Stochastic Refinement
Dec 28, 2021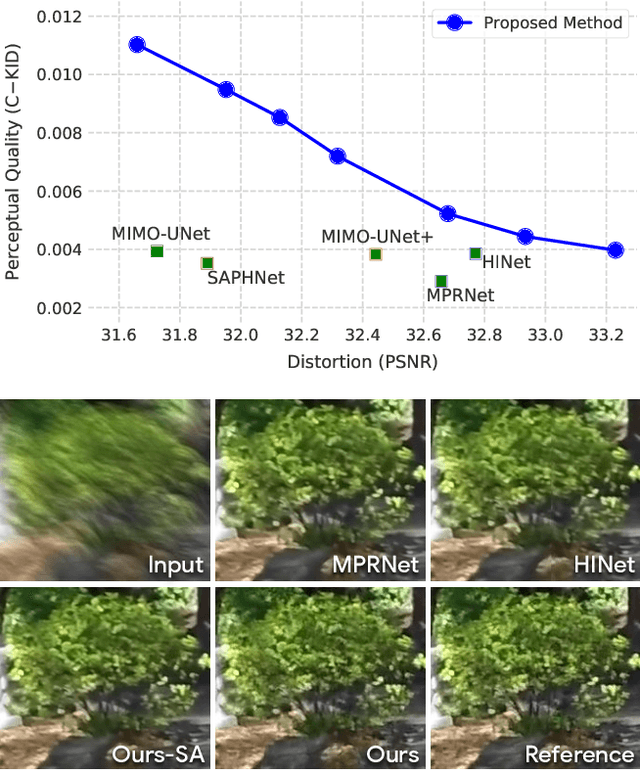



Image deblurring is an ill-posed problem with multiple plausible solutions for a given input image. However, most existing methods produce a deterministic estimate of the clean image and are trained to minimize pixel-level distortion. These metrics are known to be poorly correlated with human perception, and often lead to unrealistic reconstructions. We present an alternative framework for blind deblurring based on conditional diffusion models. Unlike existing techniques, we train a stochastic sampler that refines the output of a deterministic predictor and is capable of producing a diverse set of plausible reconstructions for a given input. This leads to a significant improvement in perceptual quality over existing state-of-the-art methods across multiple standard benchmarks. Our predict-and-refine approach also enables much more efficient sampling compared to typical diffusion models. Combined with a carefully tuned network architecture and inference procedure, our method is competitive in terms of distortion metrics such as PSNR. These results show clear benefits of our diffusion-based method for deblurring and challenge the widely used strategy of producing a single, deterministic reconstruction.
Neural Distributed Source Coding
Jun 05, 2021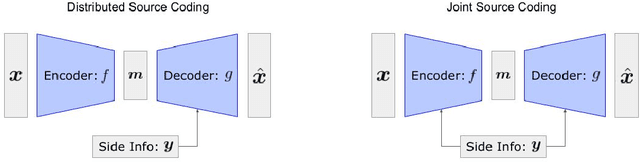
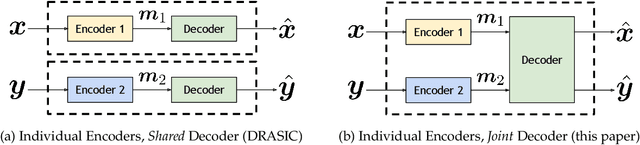


Distributed source coding is the task of encoding an input in the absence of correlated side information that is only available to the decoder. Remarkably, Slepian and Wolf showed in 1973 that an encoder that has no access to the correlated side information can asymptotically achieve the same compression rate as when the side information is available at both the encoder and the decoder. While there is significant prior work on this topic in information theory, practical distributed source coding has been limited to synthetic datasets and specific correlation structures. Here we present a general framework for lossy distributed source coding that is agnostic to the correlation structure and can scale to high dimensions. Rather than relying on hand-crafted source-modeling, our method utilizes a powerful conditional deep generative model to learn the distributed encoder and decoder. We evaluate our method on realistic high-dimensional datasets and show substantial improvements in distributed compression performance.
Model-Based Deep Learning
Dec 15, 2020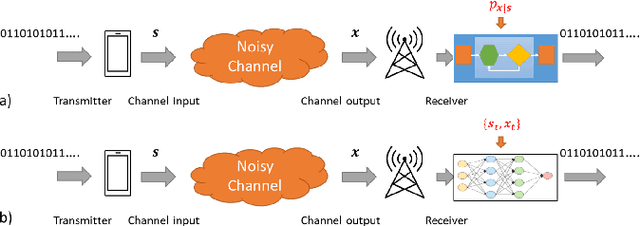
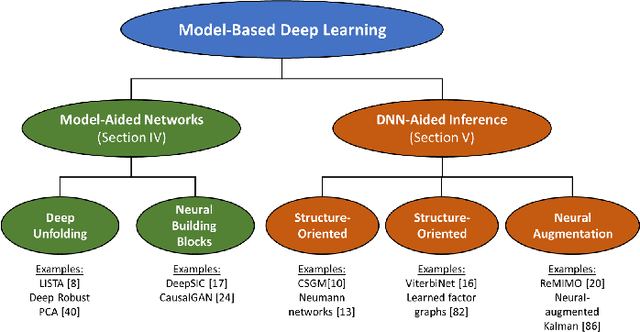


Signal processing, communications, and control have traditionally relied on classical statistical modeling techniques. Such model-based methods utilize mathematical formulations that represent the underlying physics, prior information and additional domain knowledge. Simple classical models are useful but sensitive to inaccuracies and may lead to poor performance when real systems display complex or dynamic behavior. On the other hand, purely data-driven approaches that are model-agnostic are becoming increasingly popular as datasets become abundant and the power of modern deep learning pipelines increases. Deep neural networks (DNNs) use generic architectures which learn to operate from data, and demonstrate excellent performance, especially for supervised problems. However, DNNs typically require massive amounts of data and immense computational resources, limiting their applicability for some signal processing scenarios. We are interested in hybrid techniques that combine principled mathematical models with data-driven systems to benefit from the advantages of both approaches. Such model-based deep learning methods exploit both partial domain knowledge, via mathematical structures designed for specific problems, as well as learning from limited data. In this article we survey the leading approaches for studying and designing model-based deep learning systems. We divide hybrid model-based/data-driven systems into categories based on their inference mechanism. We provide a comprehensive review of the leading approaches for combining model-based algorithms with deep learning in a systematic manner, along with concrete guidelines and detailed signal processing oriented examples from recent literature. Our aim is to facilitate the design and study of future systems on the intersection of signal processing and machine learning that incorporate the advantages of both domains.
Compressed Sensing with Invertible Generative Models and Dependent Noise
Mar 18, 2020



We study image inverse problems with invertible generative priors, specifically normalizing flow models. Our formulation views the solution as the Maximum a Posteriori (MAP) estimate of the image given the measurements. Our general formulation allows for non-linear differentiable forward operators and noise distributions with long-range dependencies. We establish theoretical recovery guarantees for denoising and compressed sensing under our framework. We also empirically validate our method on various inverse problems including compressed sensing with quantized measurements and denoising with dependent noise patterns.
Conditional Sampling from Invertible Generative Models with Applications to Inverse Problems
Feb 26, 2020
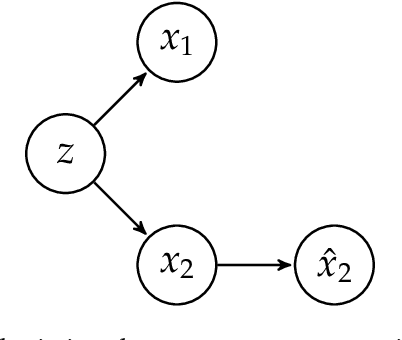

We consider uncertainty aware compressive sensing when the prior distribution is defined by an invertible generative model. In this problem, we receive a set of low dimensional measurements and we want to generate conditional samples of high dimensional objects conditioned on these measurements. We first show that the conditional sampling problem is hard in general, and thus we consider approximations to the problem. We develop a variational approach to conditional sampling that composes a new generative model with the given generative model. This allows us to utilize the sampling ability of the given generative model to quickly generate samples from the conditional distribution.
Training Variational Autoencoders with Buffered Stochastic Variational Inference
Feb 27, 2019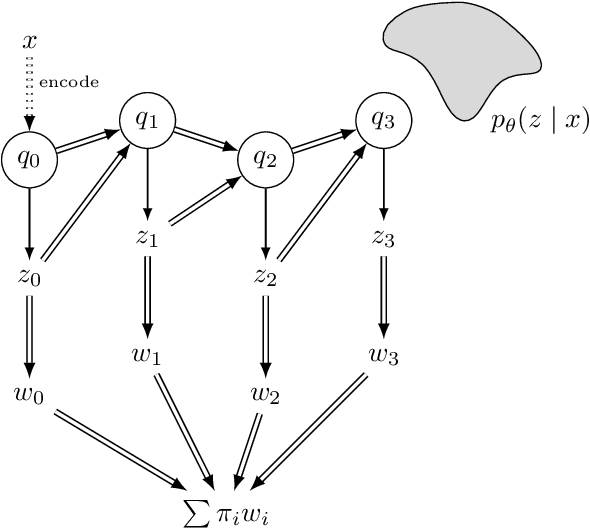
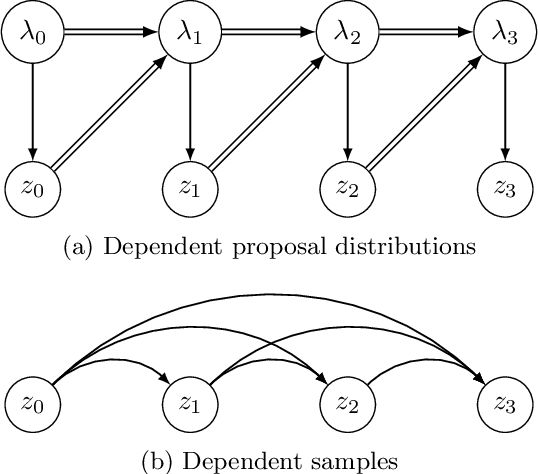
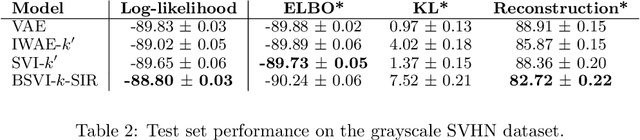

The recognition network in deep latent variable models such as variational autoencoders (VAEs) relies on amortized inference for efficient posterior approximation that can scale up to large datasets. However, this technique has also been demonstrated to select suboptimal variational parameters, often resulting in considerable additional error called the amortization gap. To close the amortization gap and improve the training of the generative model, recent works have introduced an additional refinement step that applies stochastic variational inference (SVI) to improve upon the variational parameters returned by the amortized inference model. In this paper, we propose the Buffered Stochastic Variational Inference (BSVI), a new refinement procedure that makes use of SVI's sequence of intermediate variational proposal distributions and their corresponding importance weights to construct a new generalized importance-weighted lower bound. We demonstrate empirically that training the variational autoencoders with BSVI consistently out-performs SVI, yielding an improved training procedure for VAEs.
Strategic Object Oriented Reinforcement Learning
Jun 01, 2018
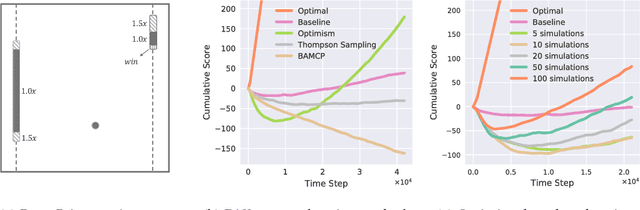
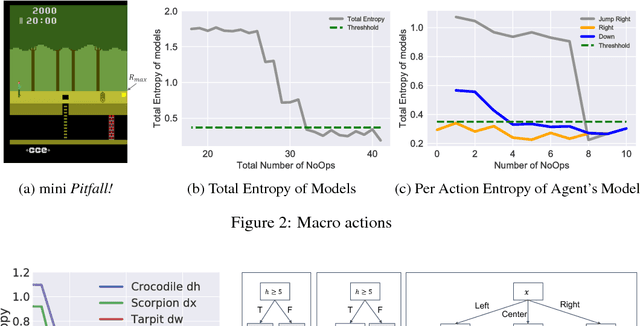
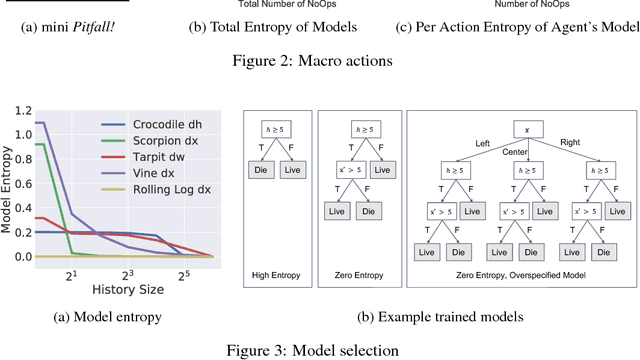
Humans learn to play video games significantly faster than state-of-the-art reinforcement learning (RL) algorithms. Inspired by this, we introduce strategic object oriented reinforcement learning (SOORL) to learn simple dynamics model through automatic model selection and perform efficient planning with strategic exploration. We compare different exploration strategies in a model-based setting in which exact planning is impossible. Additionally, we test our approach on perhaps the hardest Atari game Pitfall! and achieve significantly improved exploration and performance over prior methods.