 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Subgroups With Similar Benefits in Off-Policy Policy Evaluation
Nov 28, 2021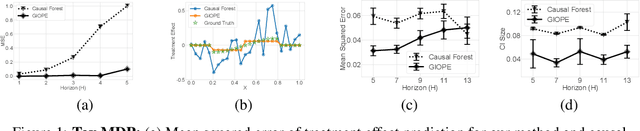
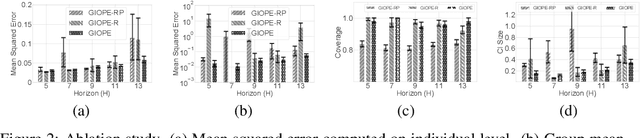
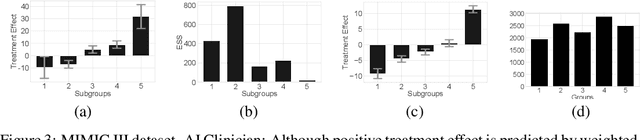
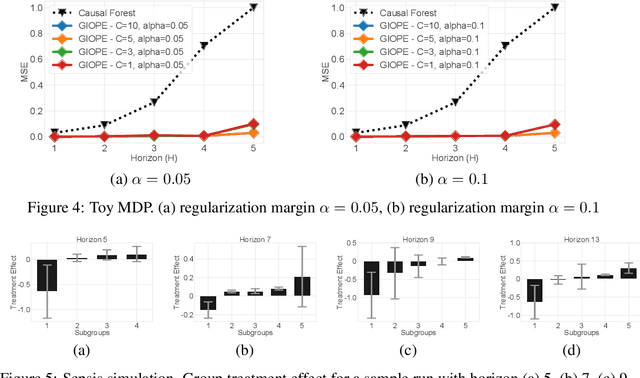
Off-policy policy evaluation methods for sequential decision making can be used to help identify if a proposed decision policy is better than a current baseline policy. However, a new decision policy may be better than a baseline policy for some individuals but not others. This has motivated a push towards personalization and accurate per-state estimates of heterogeneous treatment effects (HTEs). Given the limited data present in many important applications, individual predictions can come at a cost to accuracy and confidence in such predictions. We develop a method to balance the need for personalization with confident predictions by identifying subgroups where it is possible to confidently estimate the expected difference in a new decision policy relative to a baseline. We propose a novel loss function that accounts for uncertainty during the subgroup partitioning phase. In experiments, we show that our method can be used to form accurate predictions of HTEs where other methods struggle.
Learning Abstract Models for Strategic Exploration and Fast Reward Transfer
Jul 12, 2020
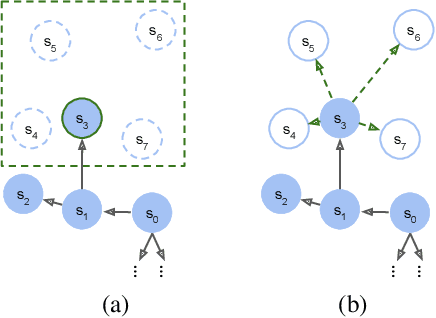

Model-based reinforcement learning (RL) is appealing because (i) it enables planning and thus more strategic exploration, and (ii) by decoupling dynamics from rewards, it enables fast transfer to new reward functions. However, learning an accurate Markov Decision Process (MDP) over high-dimensional states (e.g., raw pixels) is extremely challenging because it requires function approximation, which leads to compounding errors. Instead, to avoid compounding errors, we propose learning an abstract MDP over abstract states: low-dimensional coarse representations of the state (e.g., capturing agent position, ignoring other objects). We assume access to an abstraction function that maps the concrete states to abstract states. In our approach, we construct an abstract MDP, which grows through strategic exploration via planning. Similar to hierarchical RL approaches, the abstract actions of the abstract MDP are backed by learned subpolicies that navigate between abstract states. Our approach achieves strong results on three of the hardest Arcade Learning Environment games (Montezuma's Revenge, Pitfall!, and Private Eye), including superhuman performance on Pitfall! without demonstrations. After training on one task, we can reuse the learned abstract MDP for new reward functions, achieving higher reward in 1000x fewer samples than model-free methods trained from scratch.
Value Driven Representation for Human-in-the-Loop Reinforcement Learning
Apr 02, 2020


Interactive adaptive systems powered by Reinforcement Learning (RL) have many potential applications, such as intelligent tutoring systems. In such systems there is typically an external human system designer that is creating, monitoring and modifying the interactive adaptive system, trying to improve its performance on the target outcomes. In this paper we focus on algorithmic foundation of how to help the system designer choose the set of sensors or features to define the observation space used by reinforcement learning agent. We present an algorithm, value driven representation (VDR), that can iteratively and adaptively augment the observation space of a reinforcement learning agent so that is sufficient to capture a (near) optimal policy. To do so we introduce a new method to optimistically estimate the value of a policy using offline simulated Monte Carlo rollouts. We evaluate the performance of our approach on standard RL benchmarks with simulated humans and demonstrate significant improvement over prior baselines.
Off-policy Policy Evaluation For Sequential Decisions Under Unobserved Confounding
Mar 12, 2020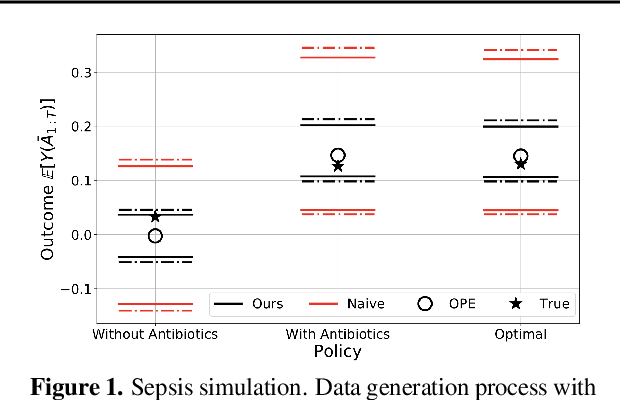
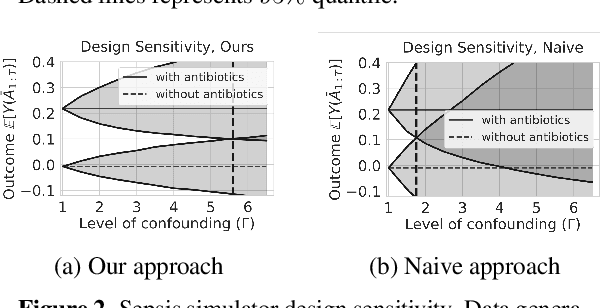

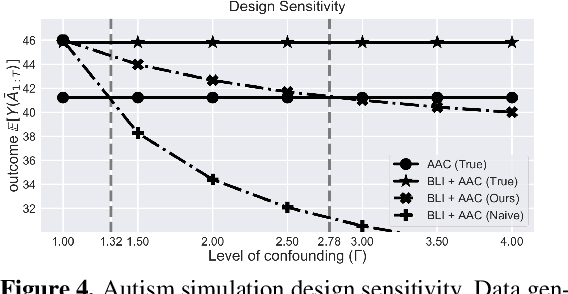
When observed decisions depend only on observed features, off-policy policy evaluation (OPE) methods for sequential decision making problems can estimate the performance of evaluation policies before deploying them. This assumption is frequently violated due to unobserved confounders, unrecorded variables that impact both the decisions and their outcomes. We assess robustness of OPE methods under unobserved confounding by developing worst-case bounds on the performance of an evaluation policy. When unobserved confounders can affect every decision in an episode, we demonstrate that even small amounts of per-decision confounding can heavily bias OPE methods. Fortunately, in a number of important settings found in healthcare, policy-making, operations, and technology, unobserved confounders may primarily affect only one of the many decisions made. Under this less pessimistic model of one-decision confounding, we propose an efficient loss-minimization-based procedure for computing worst-case bounds, and prove its statistical consistency. On two simulated healthcare examples---management of sepsis patients and developmental interventions for autistic children---where this is a reasonable model of confounding, we demonstrate that our method invalidates non-robust results and provides meaningful certificates of robustness, allowing reliable selection of policies even under unobserved confounding.
Being Optimistic to Be Conservative: Quickly Learning a CVaR Policy
Nov 05, 2019
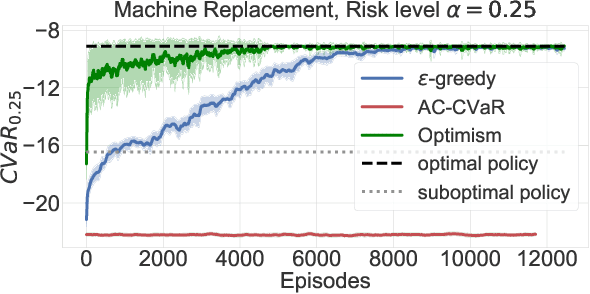
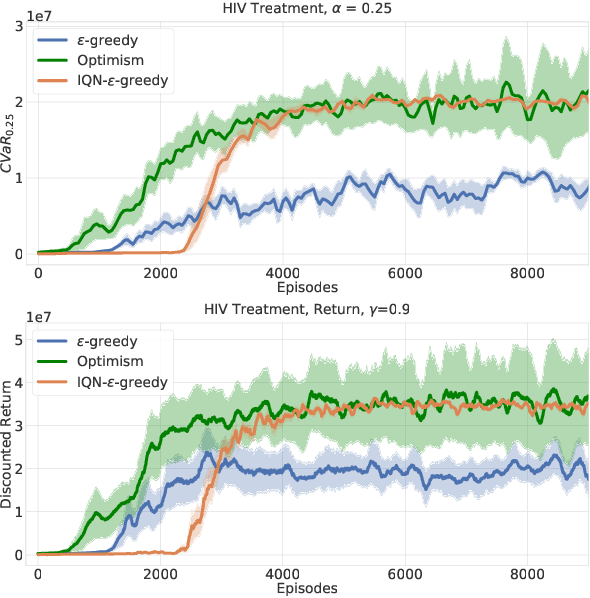
While maximizing expected return is the goal in most reinforcement learning approaches, risk-sensitive objectives such as conditional value at risk (CVaR) are more suitable for many high-stakes applications. However, relatively little is known about how to explore to quickly learn policies with good CVaR. In this paper, we present the first algorithm for sample-efficient learning of CVaR-optimal policies in Markov decision processes based on the optimism in the face of uncertainty principle. This method relies on a novel optimistic version of the distributional Bellman operator that moves probability mass from the lower to the upper tail of the return distribution. We prove asymptotic convergence and optimism of this operator for the tabular policy evaluation case. We further demonstrate that our algorithm finds CVaR-optimal policies substantially faster than existing baselines in several simulated environments with discrete and continuous state spaces.
Strategic Object Oriented Reinforcement Learning
Jun 01, 2018
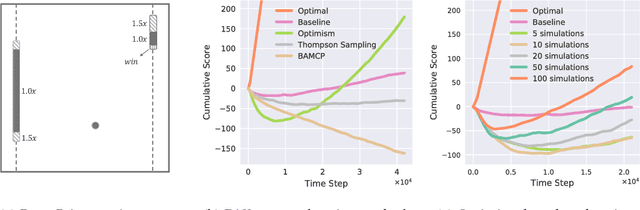
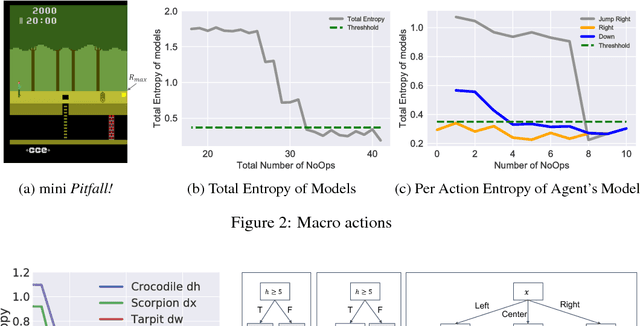
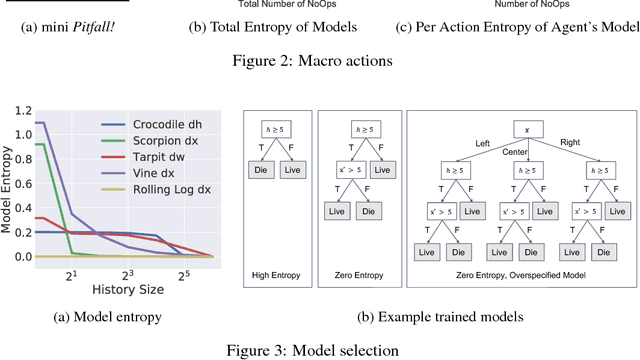
Humans learn to play video games significantly faster than state-of-the-art reinforcement learning (RL) algorithms. Inspired by this, we introduce strategic object oriented reinforcement learning (SOORL) to learn simple dynamics model through automatic model selection and perform efficient planning with strategic exploration. We compare different exploration strategies in a model-based setting in which exact planning is impossible. Additionally, we test our approach on perhaps the hardest Atari game Pitfall! and achieve significantly improved exploration and performance over prior methods.