 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous Mathematics Research
Feb 12, 2026Recent advances in foundational models have yielded reasoning systems capable of achieving a gold-medal standard at the International Mathematical Olympiad. The transition from competition-level problem-solving to professional research, however, requires navigating vast literature and constructing long-horizon proofs. In this work, we introduce Aletheia, a math research agent that iteratively generates, verifies, and revises solutions end-to-end in natural language. Specifically, Aletheia is powered by an advanced version of Gemini Deep Think for challenging reasoning problems, a novel inference-time scaling law that extends beyond Olympiad-level problems, and intensive tool use to navigate the complexities of mathematical research. We demonstrate the capability of Aletheia from Olympiad problems to PhD-level exercises and most notably, through several distinct milestones in AI-assisted mathematics research: (a) a research paper (Feng26) generated by AI without any human intervention in calculating certain structure constants in arithmetic geometry called eigenweights; (b) a research paper (LeeSeo26) demonstrating human-AI collaboration in proving bounds on systems of interacting particles called independent sets; and (c) an extensive semi-autonomous evaluation (Feng et al., 2026a) of 700 open problems on Bloom's Erdos Conjectures database, including autonomous solutions to four open questions. In order to help the public better understand the developments pertaining to AI and mathematics, we suggest quantifying standard levels of autonomy and novelty of AI-assisted results, as well as propose a novel concept of human-AI interaction cards for transparency. We conclude with reflections on human-AI collaboration in mathematics and share all prompts as well as model outputs at https://github.com/google-deepmind/superhuman/tree/main/aletheia.
AutoBencher: Creating Salient, Novel, Difficult Datasets for Language Models
Jul 11, 2024



Evaluation is critical for assessing capabilities, tracking scientific progress, and informing model selection. In this paper, we present three desiderata for a good benchmark for language models: (i) salience (e.g., knowledge about World War II is more salient than a random day in history), (ii) novelty (i.e., the benchmark reveals new trends in model rankings not shown by previous benchmarks), and (iii) difficulty (i.e., the benchmark should be difficult for existing models, leaving headroom for future improvement). We operationalize these three desiderata and cast benchmark creation as a search problem, that of finding benchmarks that that satisfy all three desiderata. To tackle this search problem, we present AutoBencher, which uses a language model to automatically search for datasets that meet the three desiderata. AutoBencher uses privileged information (e.g. relevant documents) to construct reliable datasets, and adaptivity with reranking to optimize for the search objective. We use AutoBencher to create datasets for math, multilingual, and knowledge-intensive question answering. The scalability of AutoBencher allows it to test fine-grained categories and tail knowledge, creating datasets that are on average 27% more novel and 22% more difficult than existing benchmarks. A closer investigation of our constructed datasets shows that we can identify specific gaps in LM knowledge in language models that are not captured by existing benchmarks, such as Gemini Pro performing much worse on question answering about the Permian Extinction and Fordism, while OpenAGI-7B performing surprisingly well on QA about COVID-19.
Simple Embodied Language Learning as a Byproduct of Meta-Reinforcement Learning
Jun 14, 2023



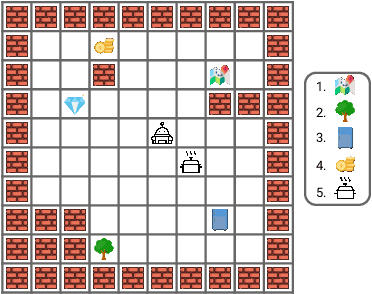
Whereas machine learning models typically learn language by directly training on language tasks (e.g., next-word prediction), language emerges in human children as a byproduct of solving non-language tasks (e.g., acquiring food). Motivated by this observation, we ask: can embodied reinforcement learning (RL) agents also indirectly learn language from non-language tasks? Learning to associate language with its meaning requires a dynamic environment with varied language. Therefore, we investigate this question in a multi-task environment with language that varies across the different tasks. Specifically, we design an office navigation environment, where the agent's goal is to find a particular office, and office locations differ in different buildings (i.e., tasks). Each building includes a floor plan with a simple language description of the goal office's location, which can be visually read as an RGB image when visited. We find RL agents indeed are able to indirectly learn language. Agents trained with current meta-RL algorithms successfully generalize to reading floor plans with held-out layouts and language phrases, and quickly navigate to the correct office, despite receiving no direct language supervision.
A Survey of Meta-Reinforcement Learning
Jan 19, 2023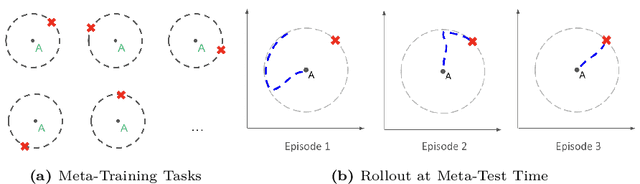
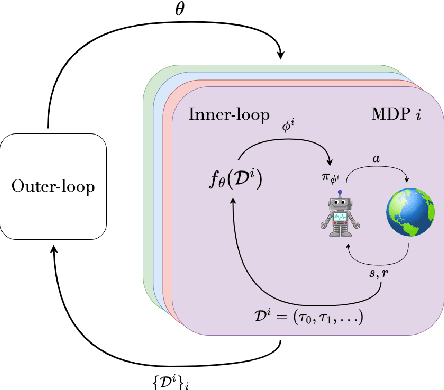

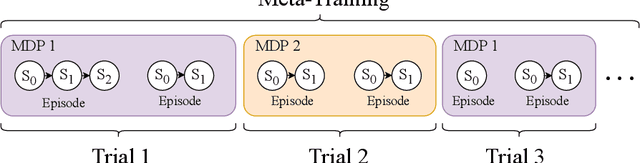
While deep reinforcement learning (RL) has fueled multiple high-profile successes in machine learning, it is held back from more widespread adoption by its often poor data efficiency and the limited generality of the policies it produces. A promising approach for alleviating these limitations is to cast the development of better RL algorithms as a machine learning problem itself in a process called meta-RL. Meta-RL is most commonly studied in a problem setting where, given a distribution of tasks, the goal is to learn a policy that is capable of adapting to any new task from the task distribution with as little data as possible. In this survey, we describe the meta-RL problem setting in detail as well as its major variations. We discuss how, at a high level, meta-RL research can be clustered based on the presence of a task distribution and the learning budget available for each individual task. Using these clusters, we then survey meta-RL algorithms and applications. We conclude by presenting the open problems on the path to making meta-RL part of the standard toolbox for a deep RL practitioner.
Learning Options via Compression
Dec 08, 2022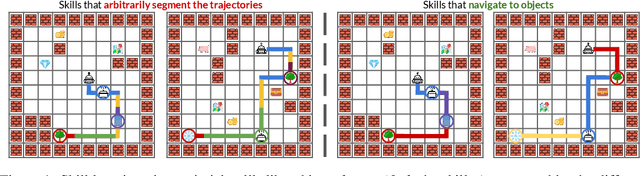
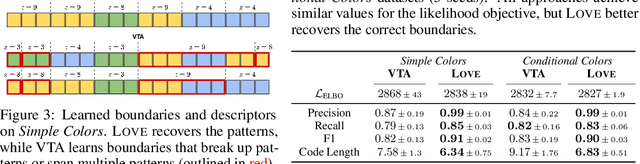
Identifying statistical regularities in solutions to some tasks in multi-task reinforcement learning can accelerate the learning of new tasks. Skill learning offers one way of identifying these regularities by decomposing pre-collected experiences into a sequence of skills. A popular approach to skill learning is maximizing the likelihood of the pre-collected experience with latent variable models, where the latent variables represent the skills. However, there are often many solutions that maximize the likelihood equally well, including degenerate solutions. To address this underspecification, we propose a new objective that combines the maximum likelihood objective with a penalty on the description length of the skills. This penalty incentivizes the skills to maximally extract common structures from the experiences. Empirically, our objective learns skills that solve downstream tasks in fewer samples compared to skills learned from only maximizing likelihood. Further, while most prior works in the offline multi-task setting focus on tasks with low-dimensional observations, our objective can scale to challenging tasks with high-dimensional image observations.
Giving Feedback on Interactive Student Programs with Meta-Exploration
Nov 16, 2022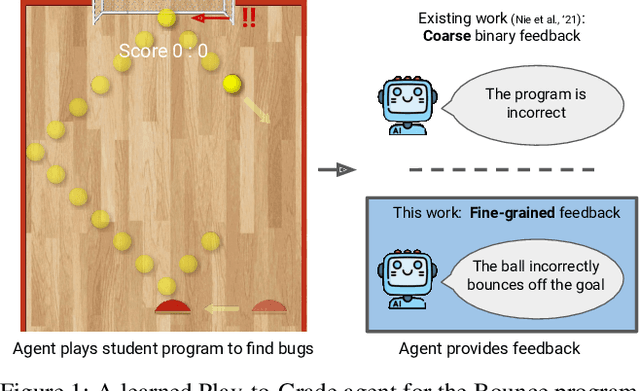
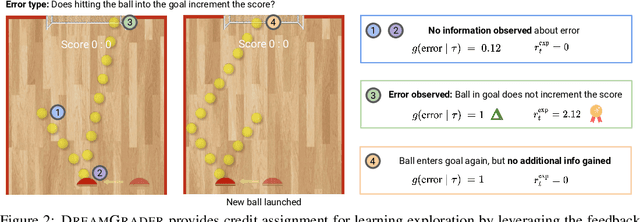
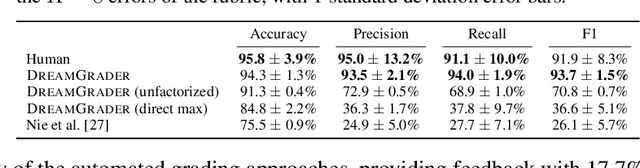
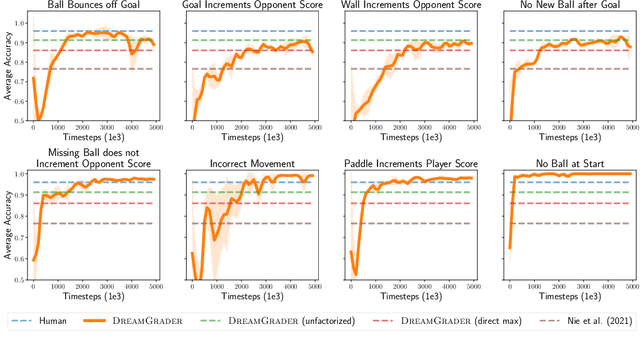
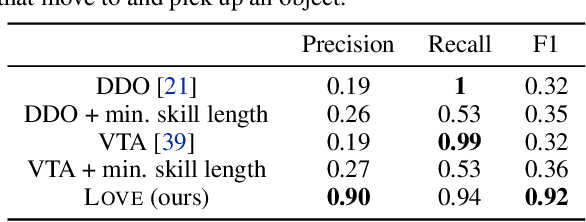
Developing interactive software, such as websites or games, is a particularly engaging way to learn computer science. However, teaching and giving feedback on such software is time-consuming -- standard approaches require instructors to manually grade student-implemented interactive programs. As a result, online platforms that serve millions, like Code.org, are unable to provide any feedback on assignments for implementing interactive programs, which critically hinders students' ability to learn. One approach toward automatic grading is to learn an agent that interacts with a student's program and explores states indicative of errors via reinforcement learning. However, existing work on this approach only provides binary feedback of whether a program is correct or not, while students require finer-grained feedback on the specific errors in their programs to understand their mistakes. In this work, we show that exploring to discover errors can be cast as a meta-exploration problem. This enables us to construct a principled objective for discovering errors and an algorithm for optimizing this objective, which provides fine-grained feedback. We evaluate our approach on a set of over 700K real anonymized student programs from a Code.org interactive assignment. Our approach provides feedback with 94.3% accuracy, improving over existing approaches by 17.7% and coming within 1.5% of human-level accuracy. Project web page: https://ezliu.github.io/dreamgrader.
Analyzing a Caching Model
Dec 13, 2021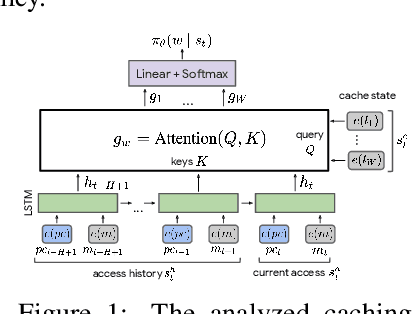

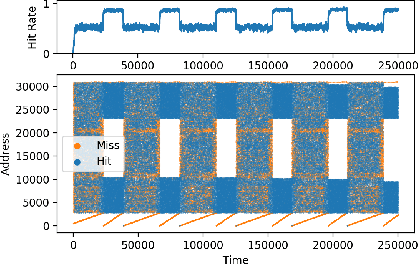
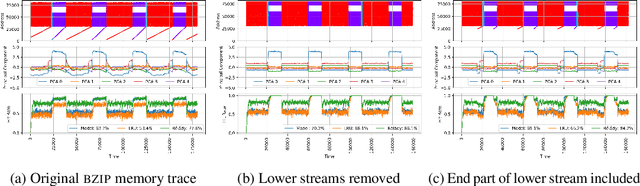
Machine Learning has been successfully applied in systems applications such as memory prefetching and caching, where learned models have been shown to outperform heuristics. However, the lack of understanding the inner workings of these models -- interpretability -- remains a major obstacle for adoption in real-world deployments. Understanding a model's behavior can help system administrators and developers gain confidence in the model, understand risks, and debug unexpected behavior in production. Interpretability for models used in computer systems poses a particular challenge: Unlike ML models trained on images or text, the input domain (e.g., memory access patterns, program counters) is not immediately interpretable. A major challenge is therefore to explain the model in terms of concepts that are approachable to a human practitioner. By analyzing a state-of-the-art caching model, we provide evidence that the model has learned concepts beyond simple statistics that can be leveraged for explanations. Our work provides a first step towards explanability of system ML models and highlights both promises and challenges of this emerging research area.
Just Train Twice: Improving Group Robustness without Training Group Information
Jul 19, 2021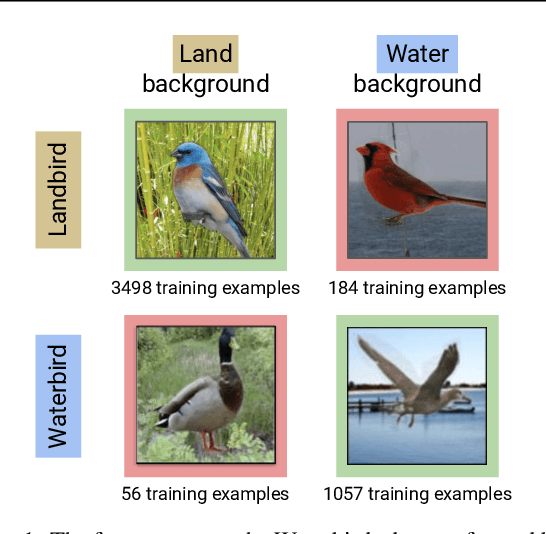
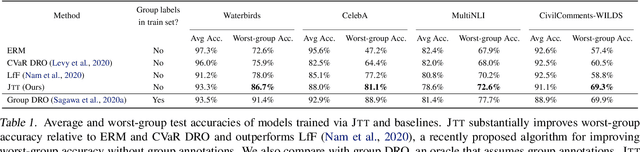

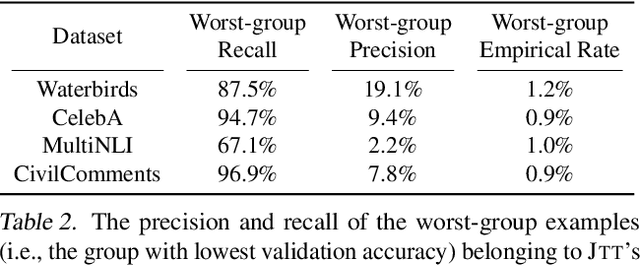
Standard training via empirical risk minimization (ERM) can produce models that achieve high accuracy on average but low accuracy on certain groups, especially in the presence of spurious correlations between the input and label. Prior approaches that achieve high worst-group accuracy, like group distributionally robust optimization (group DRO) require expensive group annotations for each training point, whereas approaches that do not use such group annotations typically achieve unsatisfactory worst-group accuracy. In this paper, we propose a simple two-stage approach, JTT, that first trains a standard ERM model for several epochs, and then trains a second model that upweights the training examples that the first model misclassified. Intuitively, this upweights examples from groups on which standard ERM models perform poorly, leading to improved worst-group performance. Averaged over four image classification and natural language processing tasks with spurious correlations, JTT closes 75% of the gap in worst-group accuracy between standard ERM and group DRO, while only requiring group annotations on a small validation set in order to tune hyperparameters.
Explore then Execute: Adapting without Rewards via Factorized Meta-Reinforcement Learning
Aug 06, 2020


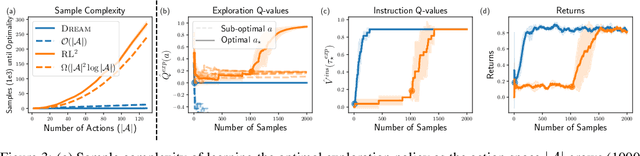
We seek to efficiently learn by leveraging shared structure between different tasks and environments. For example, cooking is similar in different kitchens, even though the ingredients may change location. In principle, meta-reinforcement learning approaches can exploit this shared structure, but in practice, they fail to adapt to new environments when adaptation requires targeted exploration (e.g., exploring the cabinets to find ingredients in a new kitchen). We show that existing approaches fail due to a chicken-and-egg problem: learning what to explore requires knowing what information is critical for solving the task, but learning to solve the task requires already gathering this information via exploration. For example, exploring to find the ingredients only helps a robot prepare a meal if it already knows how to cook, but the robot can only learn to cook if it already knows where the ingredients are. To address this, we propose a new exploration objective (DREAM), based on identifying key information in the environment, independent of how this information will exactly be used solve the task. By decoupling exploration from task execution, DREAM explores and consequently adapts to new environments, requiring no reward signal when the task is specified via an instruction. Empirically, DREAM scales to more complex problems, such as sparse-reward 3D visual navigation, while existing approaches fail from insufficient exploration.
Learning Abstract Models for Strategic Exploration and Fast Reward Transfer
Jul 12, 2020
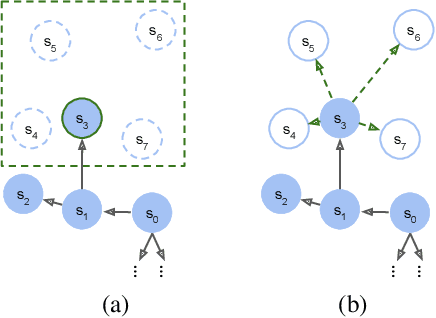

Model-based reinforcement learning (RL) is appealing because (i) it enables planning and thus more strategic exploration, and (ii) by decoupling dynamics from rewards, it enables fast transfer to new reward functions. However, learning an accurate Markov Decision Process (MDP) over high-dimensional states (e.g., raw pixels) is extremely challenging because it requires function approximation, which leads to compounding errors. Instead, to avoid compounding errors, we propose learning an abstract MDP over abstract states: low-dimensional coarse representations of the state (e.g., capturing agent position, ignoring other objects). We assume access to an abstraction function that maps the concrete states to abstract states. In our approach, we construct an abstract MDP, which grows through strategic exploration via planning. Similar to hierarchical RL approaches, the abstract actions of the abstract MDP are backed by learned subpolicies that navigate between abstract states. Our approach achieves strong results on three of the hardest Arcade Learning Environment games (Montezuma's Revenge, Pitfall!, and Private Eye), including superhuman performance on Pitfall! without demonstrations. After training on one task, we can reuse the learned abstract MDP for new reward functions, achieving higher reward in 1000x fewer samples than model-free methods trained from scratch.