 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Rigorous Study Of The Deep Taylor Decomposition
Nov 14, 2022Saliency methods attempt to explain deep neural networks by highlighting the most salient features of a sample. Some widely used methods are based on a theoretical framework called Deep Taylor Decomposition (DTD), which formalizes the recursive application of the Taylor Theorem to the network's layers. However, recent work has found these methods to be independent of the network's deeper layers and appear to respond only to lower-level image structure. Here, we investigate the DTD theory to better understand this perplexing behavior and found that the Deep Taylor Decomposition is equivalent to the basic gradient$\times$input method when the Taylor root points (an important parameter of the algorithm chosen by the user) are locally constant. If the root points are locally input-dependent, then one can justify any explanation. In this case, the theory is under-constrained. In an empirical evaluation, we find that DTD roots do not lie in the same linear regions as the input - contrary to a fundamental assumption of the Taylor theorem. The theoretical foundations of DTD were cited as a source of reliability for the explanations. However, our findings urge caution in making such claims.
DNNR: Differential Nearest Neighbors Regression
May 17, 2022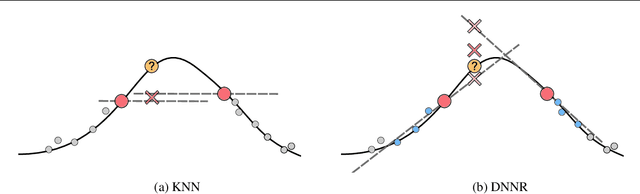
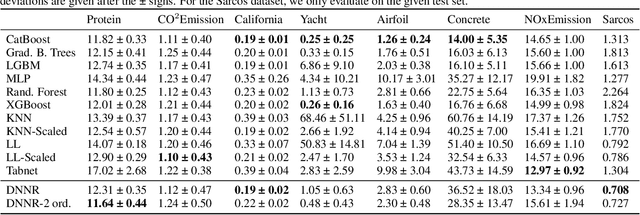
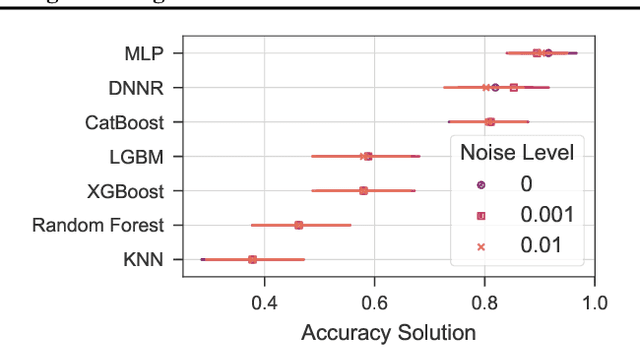
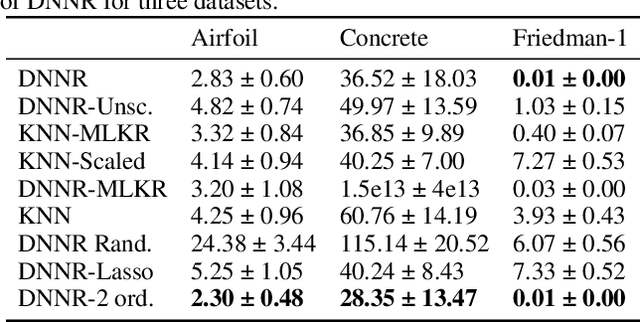
K-nearest neighbors (KNN) is one of the earliest and most established algorithms in machine learning. For regression tasks, KNN averages the targets within a neighborhood which poses a number of challenges: the neighborhood definition is crucial for the predictive performance as neighbors might be selected based on uninformative features, and averaging does not account for how the function changes locally. We propose a novel method called Differential Nearest Neighbors Regression (DNNR) that addresses both issues simultaneously: during training, DNNR estimates local gradients to scale the features; during inference, it performs an n-th order Taylor approximation using estimated gradients. In a large-scale evaluation on over 250 datasets, we find that DNNR performs comparably to state-of-the-art gradient boosting methods and MLPs while maintaining the simplicity and transparency of KNN. This allows us to derive theoretical error bounds and inspect failures. In times that call for transparency of ML models, DNNR provides a good balance between performance and interpretability.
Do Users Benefit From Interpretable Vision? A User Study, Baseline, And Dataset
Apr 25, 2022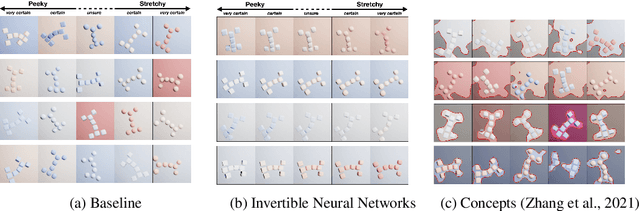


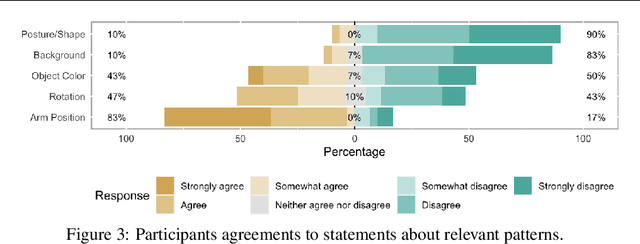
A variety of methods exist to explain image classification models. However, whether they provide any benefit to users over simply comparing various inputs and the model's respective predictions remains unclear. We conducted a user study (N=240) to test how such a baseline explanation technique performs against concept-based and counterfactual explanations. To this end, we contribute a synthetic dataset generator capable of biasing individual attributes and quantifying their relevance to the model. In a study, we assess if participants can identify the relevant set of attributes compared to the ground-truth. Our results show that the baseline outperformed concept-based explanations. Counterfactual explanations from an invertible neural network performed similarly as the baseline. Still, they allowed users to identify some attributes more accurately. Our results highlight the importance of measuring how well users can reason about biases of a model, rather than solely relying on technical evaluations or proxy tasks. We open-source our study and dataset so it can serve as a blue-print for future studies. For code see, https://github.com/berleon/do_users_benefit_from_interpretable_vision
Analyzing a Caching Model
Dec 13, 2021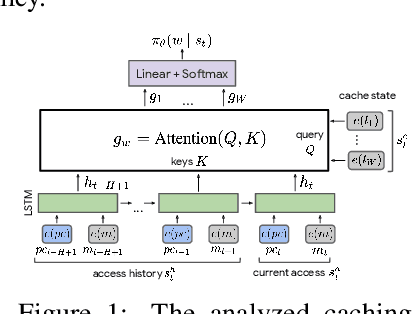

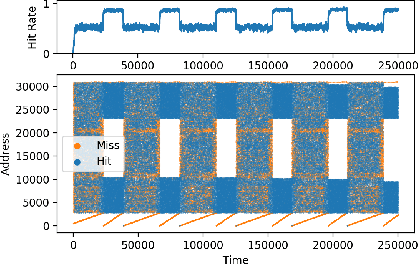
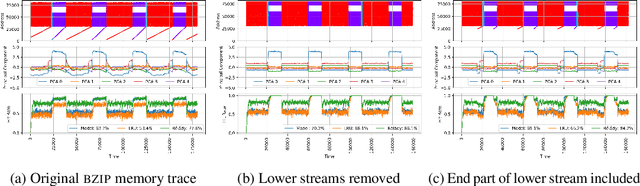
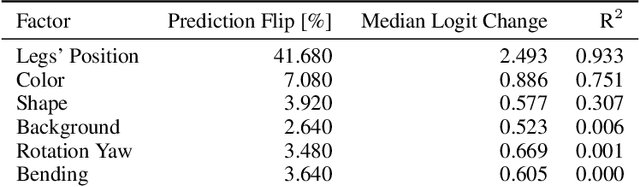
Machine Learning has been successfully applied in systems applications such as memory prefetching and caching, where learned models have been shown to outperform heuristics. However, the lack of understanding the inner workings of these models -- interpretability -- remains a major obstacle for adoption in real-world deployments. Understanding a model's behavior can help system administrators and developers gain confidence in the model, understand risks, and debug unexpected behavior in production. Interpretability for models used in computer systems poses a particular challenge: Unlike ML models trained on images or text, the input domain (e.g., memory access patterns, program counters) is not immediately interpretable. A major challenge is therefore to explain the model in terms of concepts that are approachable to a human practitioner. By analyzing a state-of-the-art caching model, we provide evidence that the model has learned concepts beyond simple statistics that can be leveraged for explanations. Our work provides a first step towards explanability of system ML models and highlights both promises and challenges of this emerging research area.
Two4Two: Evaluating Interpretable Machine Learning - A Synthetic Dataset For Controlled Experiments
May 06, 2021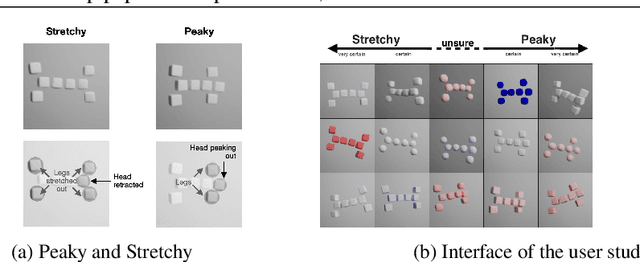
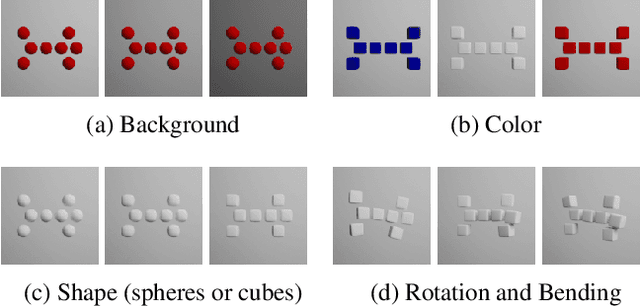
A growing number of approaches exist to generate explanations for image classification. However, few of these approaches are subjected to human-subject evaluations, partly because it is challenging to design controlled experiments with natural image datasets, as they leave essential factors out of the researcher's control. With our approach, researchers can describe their desired dataset with only a few parameters. Based on these, our library generates synthetic image data of two 3D abstract animals. The resulting data is suitable for algorithmic as well as human-subject evaluations. Our user study results demonstrate that our method can create biases predictive enough for a classifier and subtle enough to be noticeable only to every second participant inspecting the data visually. Our approach significantly lowers the barrier for conducting human subject evaluations, thereby facilitating more rigorous investigations into interpretable machine learning. For our library and datasets see, https://github.com/mschuessler/two4two/
Restricting the Flow: Information Bottlenecks for Attribution
Feb 15, 2020
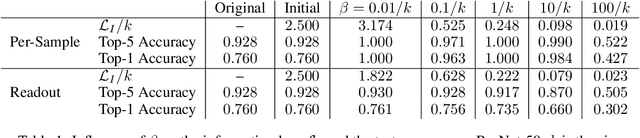
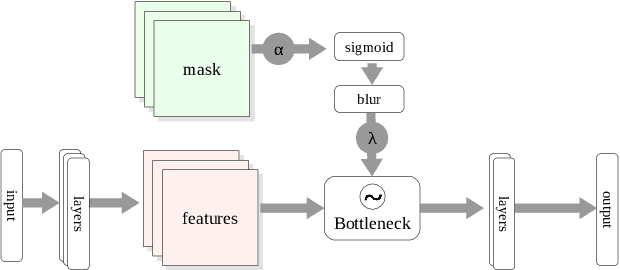
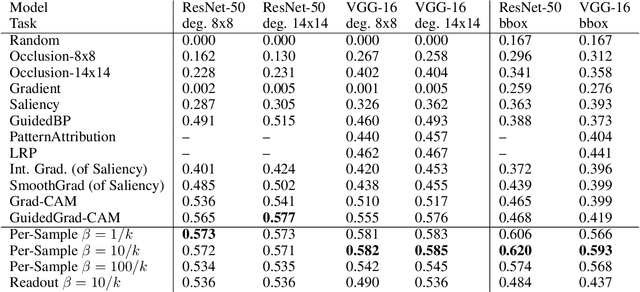
Attribution methods provide insights into the decision-making of machine learning models like artificial neural networks. For a given input sample, they assign a relevance score to each individual input variable, such as the pixels of an image. In this work we adapt the information bottleneck concept for attribution. By adding noise to intermediate feature maps we restrict the flow of information and can quantify (in bits) how much information image regions provide. We compare our method against ten baselines using three different metrics on VGG-16 and ResNet-50, and find that our methods outperform all baselines in five out of six settings. The method's information-theoretic foundation provides an absolute frame of reference for attribution values (bits) and a guarantee that regions scored close to zero are not necessary for the network's decision. For reviews: https://openreview.net/forum?id=S1xWh1rYwB For code: https://github.com/BioroboticsLab/IBA
When Explanations Lie: Why Modified BP Attribution Fails
Dec 23, 2019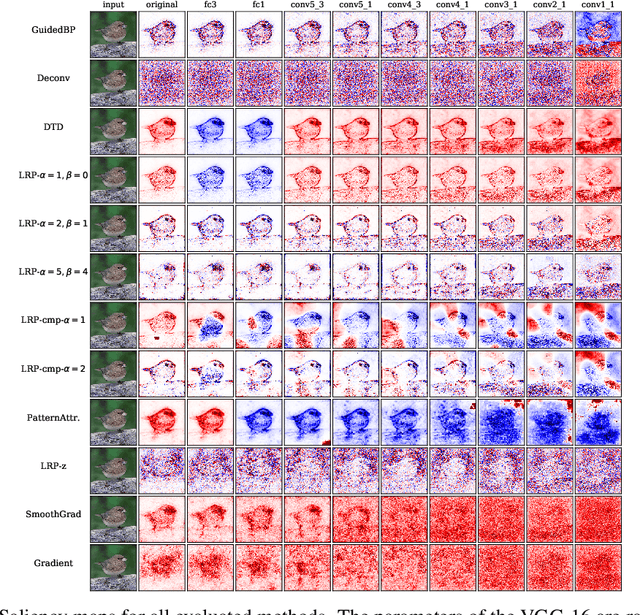
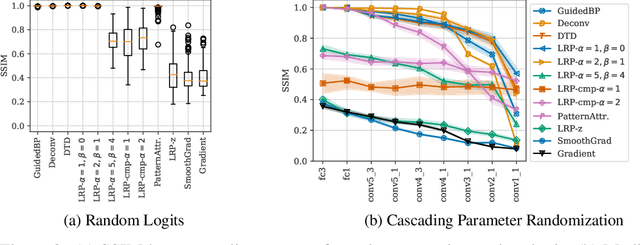
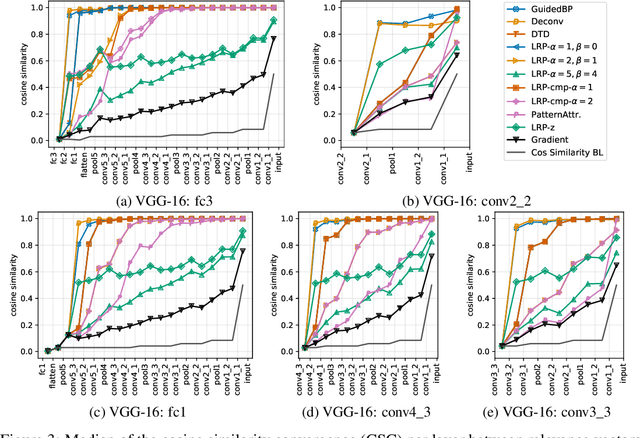
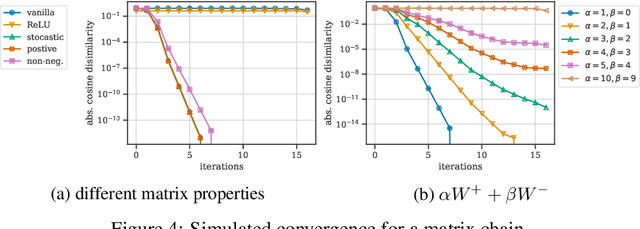
Modified backpropagation methods are a popular group of attribution methods. We analyse the most prominent methods: Deep Taylor Decomposition, Layer-wise Relevance Propagation, Excitation BP, PatternAttribution, Deconv, and Guided BP. We found empirically that the explanations of the mentioned modified BP methods are independent of the parameters of later layers and show that the $z^+$ rule used by multiple methods converges to a rank-1 matrix. This can explain well why the actual network's decision is ignored. We also develop a new metric cosine similarity convergence (CSC) to directly quantify the convergence of the modified BP methods to a rank-1 matrix. Our conclusion is that many modified BP methods do not explain the predictions of deep neural networks faithfully.
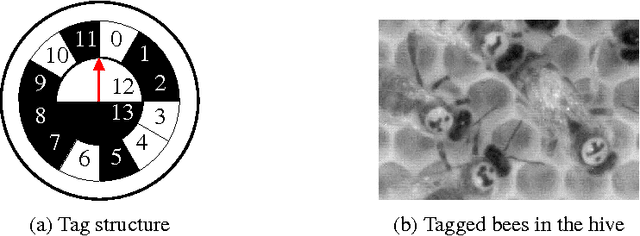
Automatic localization and decoding of honeybee markers using deep convolutional neural networks
Feb 14, 2018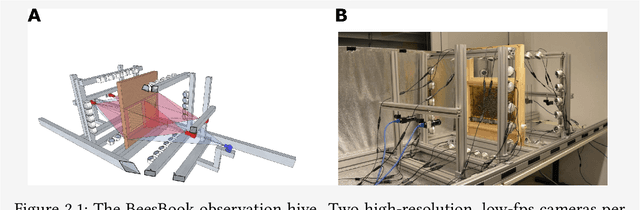
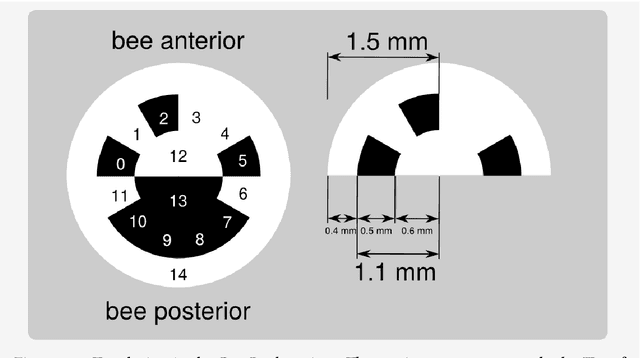
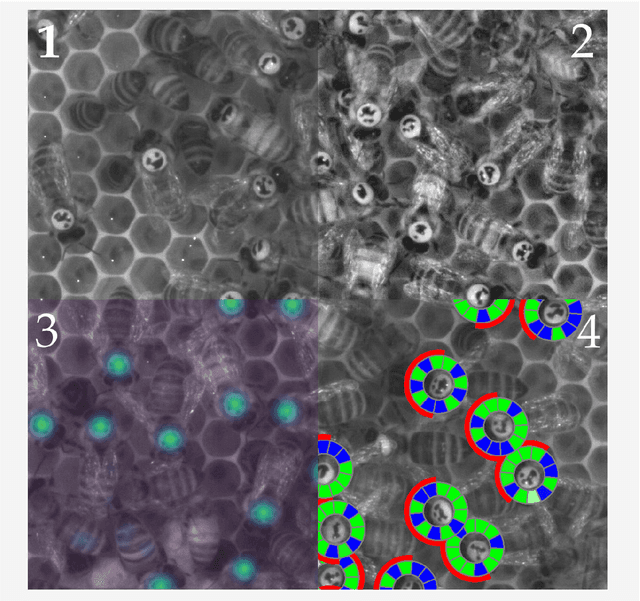
The honeybee is a fascinating model animal to investigate how collective behavior emerges from (inter-)actions of thousands of individuals. Bees may acquire unique memories throughout their lives. These experiences affect social interactions even over large time frames. Tracking and identifying all bees in the colony over their lifetimes therefore may likely shed light on the interplay of individual differences and colony behavior. This paper proposes a software pipeline based on two deep convolutional neural networks for the localization and decoding of custom binary markers that honeybees carry from their first to the last day in their life. We show that this approach outperforms similar systems proposed in recent literature. By opening this software for the public, we hope that the resulting datasets will help advancing the understanding of honeybee collective intelligence.
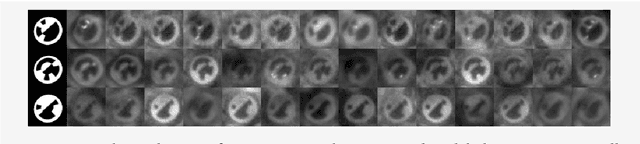
RenderGAN: Generating Realistic Labeled Data
Jan 12, 2017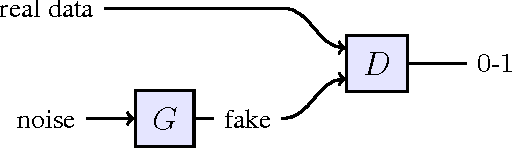
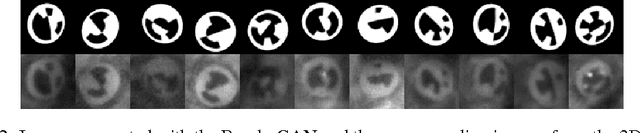
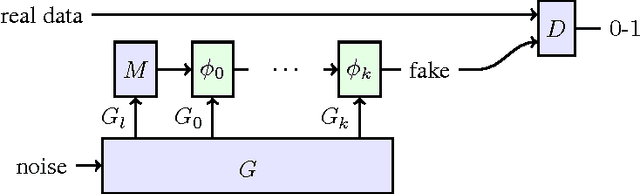
Deep Convolutional Neuronal Networks (DCNNs) are showing remarkable performance on many computer vision tasks. Due to their large parameter space, they require many labeled samples when trained in a supervised setting. The costs of annotating data manually can render the use of DCNNs infeasible. We present a novel framework called RenderGAN that can generate large amounts of realistic, labeled images by combining a 3D model and the Generative Adversarial Network framework. In our approach, image augmentations (e.g. lighting, background, and detail) are learned from unlabeled data such that the generated images are strikingly realistic while preserving the labels known from the 3D model. We apply the RenderGAN framework to generate images of barcode-like markers that are attached to honeybees. Training a DCNN on data generated by the RenderGAN yields considerably better performance than training it on various baselines.