 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal discovery with endogenous context variables
Dec 06, 2024



Causal systems often exhibit variations of the underlying causal mechanisms between the variables of the system. Often, these changes are driven by different environments or internal states in which the system operates, and we refer to context variables as those variables that indicate this change in causal mechanisms. An example are the causal relations in soil moisture-temperature interactions and their dependence on soil moisture regimes: Dry soil triggers a dependence of soil moisture on latent heat, while environments with wet soil do not feature such a feedback, making it a context-specific property. Crucially, a regime or context variable such as soil moisture need not be exogenous and can be influenced by the dynamical system variables - precipitation can make a dry soil wet - leading to joint systems with endogenous context variables. In this work we investigate the assumptions for constraint-based causal discovery of context-specific information in systems with endogenous context variables. We show that naive approaches such as learning different regime graphs on masked data, or pooling all data, can lead to uninformative results. We propose an adaptive constraint-based discovery algorithm and give a detailed discussion on the connection to structural causal models, including sufficiency assumptions, which allow to prove the soundness of our algorithm and to interpret the results causally. Numerical experiments demonstrate the performance of the proposed method over alternative baselines, but they also unveil current limitations of our method.
AI for Extreme Event Modeling and Understanding: Methodologies and Challenges
Jun 28, 2024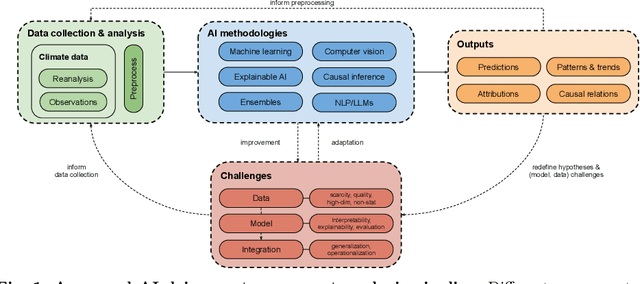

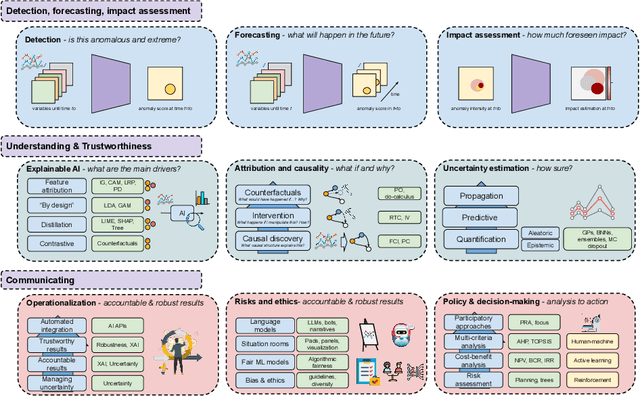

In recent years, artificial intelligence (AI) has deeply impacted various fields, including Earth system sciences. Here, AI improved weather forecasting, model emulation, parameter estimation, and the prediction of extreme events. However, the latter comes with specific challenges, such as developing accurate predictors from noisy, heterogeneous and limited annotated data. This paper reviews how AI is being used to analyze extreme events (like floods, droughts, wildfires and heatwaves), highlighting the importance of creating accurate, transparent, and reliable AI models. We discuss the hurdles of dealing with limited data, integrating information in real-time, deploying models, and making them understandable, all crucial for gaining the trust of stakeholders and meeting regulatory needs. We provide an overview of how AI can help identify and explain extreme events more effectively, improving disaster response and communication. We emphasize the need for collaboration across different fields to create AI solutions that are practical, understandable, and trustworthy for analyzing and predicting extreme events. Such collaborative efforts aim to enhance disaster readiness and disaster risk reduction.
Non-parametric Conditional Independence Testing for Mixed Continuous-Categorical Variables: A Novel Method and Numerical Evaluation
Nov 05, 2023Conditional independence testing (CIT) is a common task in machine learning, e.g., for variable selection, and a main component of constraint-based causal discovery. While most current CIT approaches assume that all variables are numerical or all variables are categorical, many real-world applications involve mixed-type datasets that include numerical and categorical variables. Non-parametric CIT can be conducted using conditional mutual information (CMI) estimators combined with a local permutation scheme. Recently, two novel CMI estimators for mixed-type datasets based on k-nearest-neighbors (k-NN) have been proposed. As with any k-NN method, these estimators rely on the definition of a distance metric. One approach computes distances by a one-hot encoding of the categorical variables, essentially treating categorical variables as discrete-numerical, while the other expresses CMI by entropy terms where the categorical variables appear as conditions only. In this work, we study these estimators and propose a variation of the former approach that does not treat categorical variables as numeric. Our numerical experiments show that our variant detects dependencies more robustly across different data distributions and preprocessing types.
Automated multilingual detection of Pro-Kremlin propaganda in newspapers and Telegram posts
Jan 25, 2023
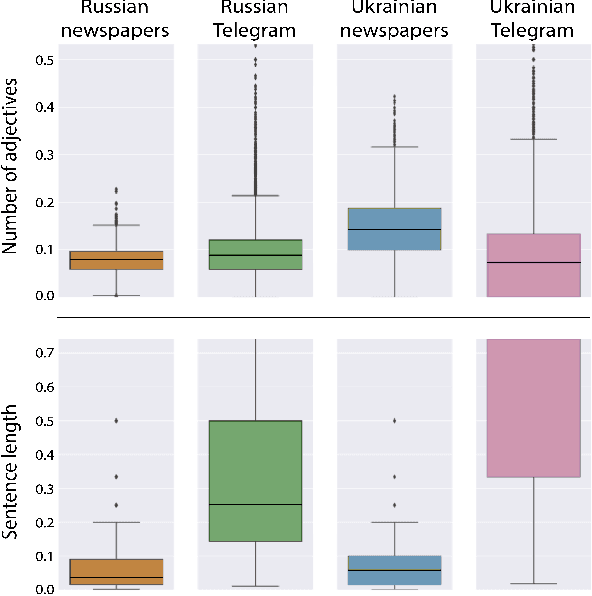

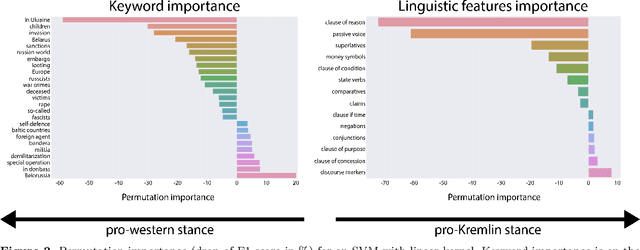
The full-scale conflict between the Russian Federation and Ukraine generated an unprecedented amount of news articles and social media data reflecting opposing ideologies and narratives. These polarized campaigns have led to mutual accusations of misinformation and fake news, shaping an atmosphere of confusion and mistrust for readers worldwide. This study analyses how the media affected and mirrored public opinion during the first month of the war using news articles and Telegram news channels in Ukrainian, Russian, Romanian and English. We propose and compare two methods of multilingual automated pro-Kremlin propaganda identification, based on Transformers and linguistic features. We analyse the advantages and disadvantages of both methods, their adaptability to new genres and languages, and ethical considerations of their usage for content moderation. With this work, we aim to lay the foundation for further development of moderation tools tailored to the current conflict.
Do Users Benefit From Interpretable Vision? A User Study, Baseline, And Dataset
Apr 25, 2022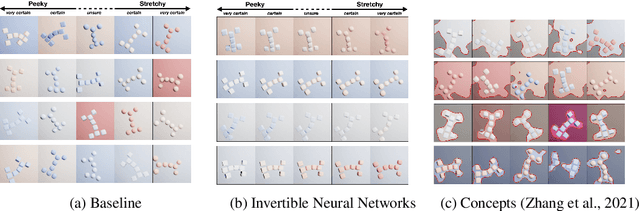
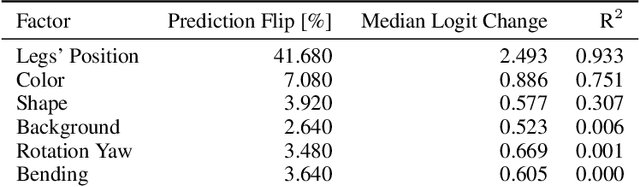


A variety of methods exist to explain image classification models. However, whether they provide any benefit to users over simply comparing various inputs and the model's respective predictions remains unclear. We conducted a user study (N=240) to test how such a baseline explanation technique performs against concept-based and counterfactual explanations. To this end, we contribute a synthetic dataset generator capable of biasing individual attributes and quantifying their relevance to the model. In a study, we assess if participants can identify the relevant set of attributes compared to the ground-truth. Our results show that the baseline outperformed concept-based explanations. Counterfactual explanations from an invertible neural network performed similarly as the baseline. Still, they allowed users to identify some attributes more accurately. Our results highlight the importance of measuring how well users can reason about biases of a model, rather than solely relying on technical evaluations or proxy tasks. We open-source our study and dataset so it can serve as a blue-print for future studies. For code see, https://github.com/berleon/do_users_benefit_from_interpretable_vision
Counterfactual Generation with Knockoffs
Feb 01, 2021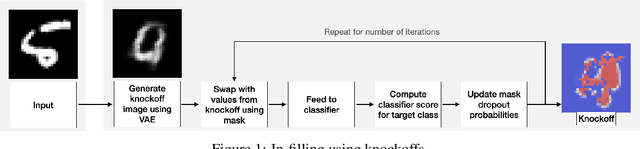
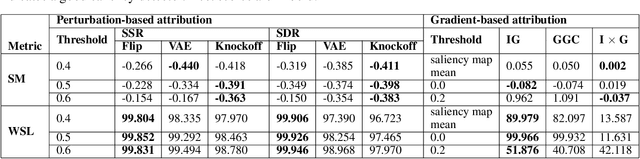

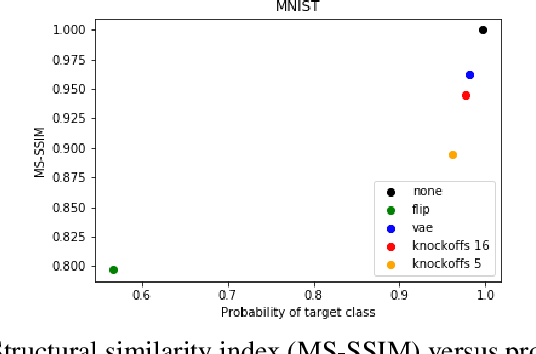
Human interpretability of deep neural networks' decisions is crucial, especially in domains where these directly affect human lives. Counterfactual explanations of already trained neural networks can be generated by perturbing input features and attributing importance according to the change in the classifier's outcome after perturbation. Perturbation can be done by replacing features using heuristic or generative in-filling methods. The choice of in-filling function significantly impacts the number of artifacts, i.e., false-positive attributions. Heuristic methods result in false-positive artifacts because the image after the perturbation is far from the original data distribution. Generative in-filling methods reduce artifacts by producing in-filling values that respect the original data distribution. However, current generative in-filling methods may also increase false-negatives due to the high correlation of in-filling values with the original data. In this paper, we propose to alleviate this by generating in-fillings with the statistically-grounded Knockoffs framework, which was developed by Barber and Cand\`es in 2015 as a tool for variable selection with controllable false discovery rate. Knockoffs are statistically null-variables as decorrelated as possible from the original data, which can be swapped with the originals without changing the underlying data distribution. A comparison of different in-filling methods indicates that in-filling with knockoffs can reveal explanations in a more causal sense while still maintaining the compactness of the explanations.