 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing a Caching Model
Dec 13, 2021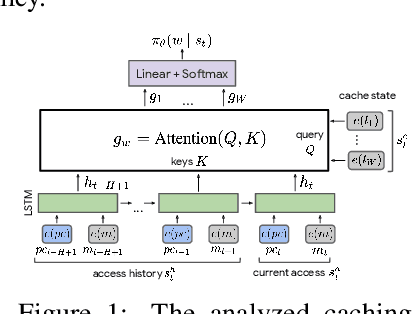

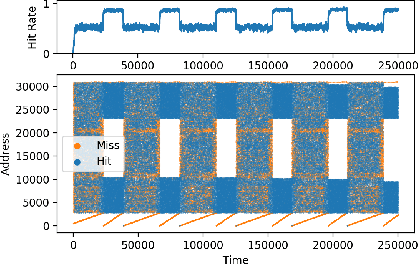
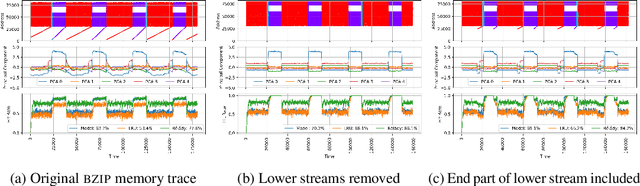
Machine Learning has been successfully applied in systems applications such as memory prefetching and caching, where learned models have been shown to outperform heuristics. However, the lack of understanding the inner workings of these models -- interpretability -- remains a major obstacle for adoption in real-world deployments. Understanding a model's behavior can help system administrators and developers gain confidence in the model, understand risks, and debug unexpected behavior in production. Interpretability for models used in computer systems poses a particular challenge: Unlike ML models trained on images or text, the input domain (e.g., memory access patterns, program counters) is not immediately interpretable. A major challenge is therefore to explain the model in terms of concepts that are approachable to a human practitioner. By analyzing a state-of-the-art caching model, we provide evidence that the model has learned concepts beyond simple statistics that can be leveraged for explanations. Our work provides a first step towards explanability of system ML models and highlights both promises and challenges of this emerging research area.