 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLVF: Learning from Verbal Feedback without Overgeneralization
Feb 16, 2024



The diversity of contexts in which large language models (LLMs) are deployed requires the ability to modify or customize default model behaviors to incorporate nuanced requirements and preferences. A convenient interface to specify such model adjustments is high-level verbal feedback, such as "Don't use emojis when drafting emails to my boss." However, while writing high-level feedback is far simpler than collecting annotations for reinforcement learning from human feedback (RLHF), we find that simply prompting a model with such feedback leads to overgeneralization of the feedback to contexts where it is not relevant. We study the problem of incorporating verbal feedback without such overgeneralization, inspiring a new method Contextualized Critiques with Constrained Preference Optimization (C3PO). C3PO uses a piece of high-level feedback to generate a small synthetic preference dataset specifying how the feedback should (and should not) be applied. It then fine-tunes the model in accordance with the synthetic preference data while minimizing the divergence from the original model for prompts where the feedback does not apply. Our experimental results indicate that our approach effectively applies verbal feedback to relevant scenarios while preserving existing behaviors for other contexts. For both human- and GPT-4-generated high-level feedback, C3PO effectively adheres to the given feedback comparably to in-context baselines while reducing overgeneralization by 30%.
Giving Feedback on Interactive Student Programs with Meta-Exploration
Nov 16, 2022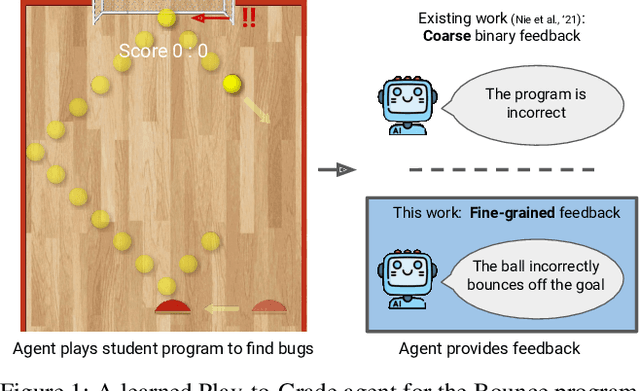
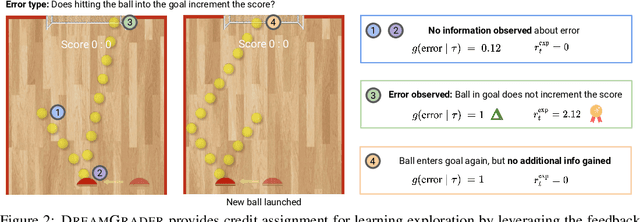
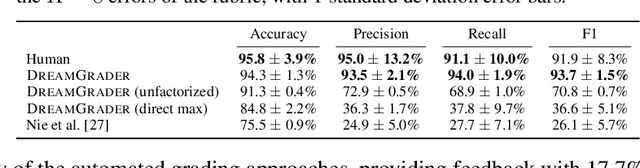
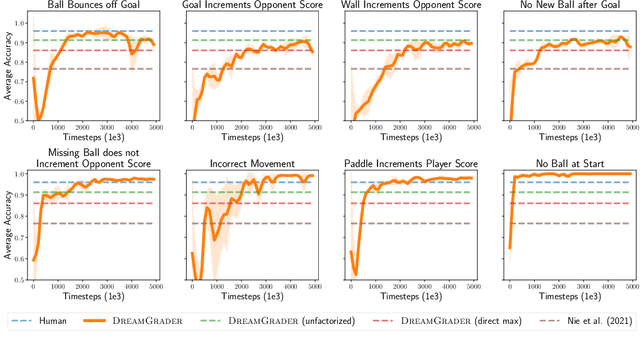
Developing interactive software, such as websites or games, is a particularly engaging way to learn computer science. However, teaching and giving feedback on such software is time-consuming -- standard approaches require instructors to manually grade student-implemented interactive programs. As a result, online platforms that serve millions, like Code.org, are unable to provide any feedback on assignments for implementing interactive programs, which critically hinders students' ability to learn. One approach toward automatic grading is to learn an agent that interacts with a student's program and explores states indicative of errors via reinforcement learning. However, existing work on this approach only provides binary feedback of whether a program is correct or not, while students require finer-grained feedback on the specific errors in their programs to understand their mistakes. In this work, we show that exploring to discover errors can be cast as a meta-exploration problem. This enables us to construct a principled objective for discovering errors and an algorithm for optimizing this objective, which provides fine-grained feedback. We evaluate our approach on a set of over 700K real anonymized student programs from a Code.org interactive assignment. Our approach provides feedback with 94.3% accuracy, improving over existing approaches by 17.7% and coming within 1.5% of human-level accuracy. Project web page: https://ezliu.github.io/dreamgrader.