 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptNCE: Pointwise Mutual Information Predictions Using Only LLMs and Contrastive Estimation Prompts
May 20, 2026Estimating mutual information from text usually requires training a task-specific critic, which limits its use in low-data settings. We ask whether large language models can instead estimate pointwise mutual information zero-shot, using only prompts and elicited probabilities. We introduce a benchmark with human-derived ground-truth PMI across three publicly available datasets, and evaluate five information-theoretic prompting-based estimators. Our main method, PromptNCE, frames conditional probability estimation as a contrastive task and augments the candidate set with an explicit OTHER category. We show theoretically that adding OTHER recovers the true conditional P(y | x) rather than just a ranking over listed candidates, turning a contrastive prompt into a general-purpose zero-shot probability estimator. PromptNCE is the best zero-shot method on all three datasets, reaching Spearman correlation up to 0.82 with human-derived PMI. We also present a case study in computer science education showing how these estimators can be used to score student knowledge summaries in a low-data setting.
Handwritten Code Recognition for Pen-and-Paper CS Education
Aug 07, 2024



Teaching Computer Science (CS) by having students write programs by hand on paper has key pedagogical advantages: It allows focused learning and requires careful thinking compared to the use of Integrated Development Environments (IDEs) with intelligent support tools or "just trying things out". The familiar environment of pens and paper also lessens the cognitive load of students with no prior experience with computers, for whom the mere basic usage of computers can be intimidating. Finally, this teaching approach opens learning opportunities to students with limited access to computers. However, a key obstacle is the current lack of teaching methods and support software for working with and running handwritten programs. Optical character recognition (OCR) of handwritten code is challenging: Minor OCR errors, perhaps due to varied handwriting styles, easily make code not run, and recognizing indentation is crucial for languages like Python but is difficult to do due to inconsistent horizontal spacing in handwriting. Our approach integrates two innovative methods. The first combines OCR with an indentation recognition module and a language model designed for post-OCR error correction without introducing hallucinations. This method, to our knowledge, surpasses all existing systems in handwritten code recognition. It reduces error from 30\% in the state of the art to 5\% with minimal hallucination of logical fixes to student programs. The second method leverages a multimodal language model to recognize handwritten programs in an end-to-end fashion. We hope this contribution can stimulate further pedagogical research and contribute to the goal of making CS education universally accessible. We release a dataset of handwritten programs and code to support future research at https://github.com/mdoumbouya/codeocr
From Tarzan to Tolkien: Controlling the Language Proficiency Level of LLMs for Content Generation
Jun 05, 2024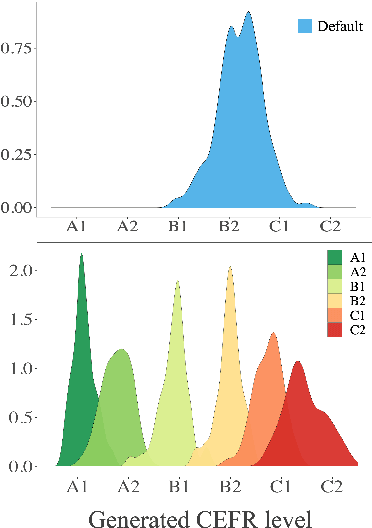
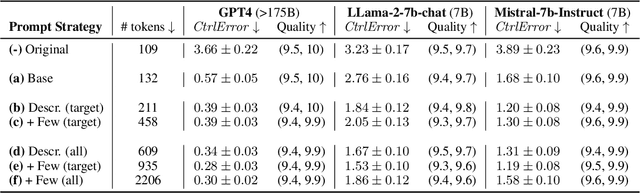
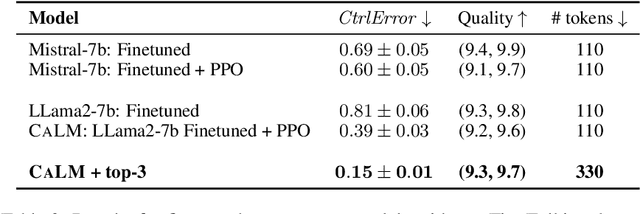
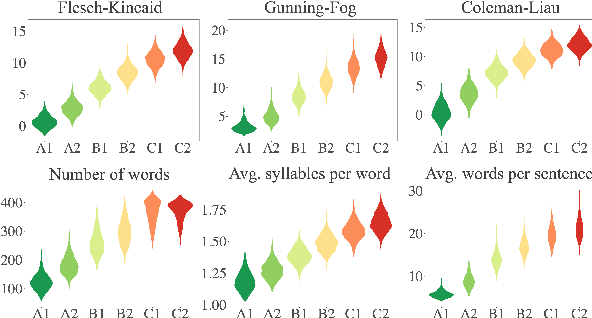
We study the problem of controlling the difficulty level of text generated by Large Language Models (LLMs) for contexts where end-users are not fully proficient, such as language learners. Using a novel framework, we evaluate the effectiveness of several key approaches for this task, including few-shot prompting, supervised finetuning, and reinforcement learning (RL), utilising both GPT-4 and open source alternatives like LLama2-7B and Mistral-7B. Our findings reveal a large performance gap between GPT-4 and the open source models when using prompt-based strategies. However, we show how to bridge this gap with a careful combination of finetuning and RL alignment. Our best model, CALM (CEFR-Aligned Language Model), surpasses the performance of GPT-4 and other strategies, at only a fraction of the cost. We further validate the quality of our results through a small-scale human study.
Variational Temporal IRT: Fast, Accurate, and Explainable Inference of Dynamic Learner Proficiency
Nov 14, 2023Dynamic Item Response Models extend the standard Item Response Theory (IRT) to capture temporal dynamics in learner ability. While these models have the potential to allow instructional systems to actively monitor the evolution of learner proficiency in real time, existing dynamic item response models rely on expensive inference algorithms that scale poorly to massive datasets. In this work, we propose Variational Temporal IRT (VTIRT) for fast and accurate inference of dynamic learner proficiency. VTIRT offers orders of magnitude speedup in inference runtime while still providing accurate inference. Moreover, the proposed algorithm is intrinsically interpretable by virtue of its modular design. When applied to 9 real student datasets, VTIRT consistently yields improvements in predicting future learner performance over other learner proficiency models.
Machine Translation for Nko: Tools, Corpora and Baseline Results
Oct 31, 2023Currently, there is no usable machine translation system for Nko \footnote{Also spelled N'Ko, but speakers prefer the name Nko.}, a language spoken by tens of millions of people across multiple West African countries, which holds significant cultural and educational value. To address this issue, we present a set of tools, resources, and baseline results aimed towards the development of usable machine translation systems for Nko and other languages that do not currently have sufficiently large parallel text corpora available. (1) Fria$\parallel$el: A novel collaborative parallel text curation software that incorporates quality control through copyedit-based workflows. (2) Expansion of the FLoRes-200 and NLLB-Seed corpora with 2,009 and 6,193 high-quality Nko translations in parallel with 204 and 40 other languages. (3) nicolingua-0005: A collection of trilingual and bilingual corpora with 130,850 parallel segments and monolingual corpora containing over 3 million Nko words. (4) Baseline bilingual and multilingual neural machine translation results with the best model scoring 30.83 English-Nko chrF++ on FLoRes-devtest.
MoCa: Measuring Human-Language Model Alignment on Causal and Moral Judgment Tasks
Oct 31, 2023



Human commonsense understanding of the physical and social world is organized around intuitive theories. These theories support making causal and moral judgments. When something bad happens, we naturally ask: who did what, and why? A rich literature in cognitive science has studied people's causal and moral intuitions. This work has revealed a number of factors that systematically influence people's judgments, such as the violation of norms and whether the harm is avoidable or inevitable. We collected a dataset of stories from 24 cognitive science papers and developed a system to annotate each story with the factors they investigated. Using this dataset, we test whether large language models (LLMs) make causal and moral judgments about text-based scenarios that align with those of human participants. On the aggregate level, alignment has improved with more recent LLMs. However, using statistical analyses, we find that LLMs weigh the different factors quite differently from human participants. These results show how curated, challenge datasets combined with insights from cognitive science can help us go beyond comparisons based merely on aggregate metrics: we uncover LLMs implicit tendencies and show to what extent these align with human intuitions.
BanditPAM++: Faster $k$-medoids Clustering
Oct 28, 2023


Clustering is a fundamental task in data science with wide-ranging applications. In $k$-medoids clustering, cluster centers must be actual datapoints and arbitrary distance metrics may be used; these features allow for greater interpretability of the cluster centers and the clustering of exotic objects in $k$-medoids clustering, respectively. $k$-medoids clustering has recently grown in popularity due to the discovery of more efficient $k$-medoids algorithms. In particular, recent research has proposed BanditPAM, a randomized $k$-medoids algorithm with state-of-the-art complexity and clustering accuracy. In this paper, we present BanditPAM++, which accelerates BanditPAM via two algorithmic improvements, and is $O(k)$ faster than BanditPAM in complexity and substantially faster than BanditPAM in wall-clock runtime. First, we demonstrate that BanditPAM has a special structure that allows the reuse of clustering information $\textit{within}$ each iteration. Second, we demonstrate that BanditPAM has additional structure that permits the reuse of information $\textit{across}$ different iterations. These observations inspire our proposed algorithm, BanditPAM++, which returns the same clustering solutions as BanditPAM but often several times faster. For example, on the CIFAR10 dataset, BanditPAM++ returns the same results as BanditPAM but runs over 10$\times$ faster. Finally, we provide a high-performance C++ implementation of BanditPAM++, callable from Python and R, that may be of interest to practitioners at https://github.com/motiwari/BanditPAM. Auxiliary code to reproduce all of our experiments via a one-line script is available at https://github.com/ThrunGroup/BanditPAM_plusplus_experiments.
The BEA 2023 Shared Task on Generating AI Teacher Responses in Educational Dialogues
Jun 12, 2023This paper describes the results of the first shared task on the generation of teacher responses in educational dialogues. The goal of the task was to benchmark the ability of generative language models to act as AI teachers, replying to a student in a teacher-student dialogue. Eight teams participated in the competition hosted on CodaLab. They experimented with a wide variety of state-of-the-art models, including Alpaca, Bloom, DialoGPT, DistilGPT-2, Flan-T5, GPT-2, GPT-3, GPT- 4, LLaMA, OPT-2.7B, and T5-base. Their submissions were automatically scored using BERTScore and DialogRPT metrics, and the top three among them were further manually evaluated in terms of pedagogical ability based on Tack and Piech (2022). The NAISTeacher system, which ranked first in both automated and human evaluation, generated responses with GPT-3.5 using an ensemble of prompts and a DialogRPT-based ranking of responses for given dialogue contexts. Despite the promising achievements of the participating teams, the results also highlight the need for evaluation metrics better suited to educational contexts.
Bayesian Decision Trees via Tractable Priors and Probabilistic Context-Free Grammars
Feb 15, 2023



Decision Trees are some of the most popular machine learning models today due to their out-of-the-box performance and interpretability. Often, Decision Trees models are constructed greedily in a top-down fashion via heuristic search criteria, such as Gini impurity or entropy. However, trees constructed in this manner are sensitive to minor fluctuations in training data and are prone to overfitting. In contrast, Bayesian approaches to tree construction formulate the selection process as a posterior inference problem; such approaches are more stable and provide greater theoretical guarantees. However, generating Bayesian Decision Trees usually requires sampling from complex, multimodal posterior distributions. Current Markov Chain Monte Carlo-based approaches for sampling Bayesian Decision Trees are prone to mode collapse and long mixing times, which makes them impractical. In this paper, we propose a new criterion for training Bayesian Decision Trees. Our criterion gives rise to BCART-PCFG, which can efficiently sample decision trees from a posterior distribution across trees given the data and find the maximum a posteriori (MAP) tree. Learning the posterior and training the sampler can be done in time that is polynomial in the dataset size. Once the posterior has been learned, trees can be sampled efficiently (linearly in the number of nodes). At the core of our method is a reduction of sampling the posterior to sampling a derivation from a probabilistic context-free grammar. We find that trees sampled via BCART-PCFG perform comparable to or better than greedily-constructed Decision Trees in classification accuracy on several datasets. Additionally, the trees sampled via BCART-PCFG are significantly smaller -- sometimes by as much as 20x.
MABSplit: Faster Forest Training Using Multi-Armed Bandits
Dec 14, 2022



Random forests are some of the most widely used machine learning models today, especially in domains that necessitate interpretability. We present an algorithm that accelerates the training of random forests and other popular tree-based learning methods. At the core of our algorithm is a novel node-splitting subroutine, dubbed MABSplit, used to efficiently find split points when constructing decision trees. Our algorithm borrows techniques from the multi-armed bandit literature to judiciously determine how to allocate samples and computational power across candidate split points. We provide theoretical guarantees that MABSplit improves the sample complexity of each node split from linear to logarithmic in the number of data points. In some settings, MABSplit leads to 100x faster training (an 99% reduction in training time) without any decrease in generalization performance. We demonstrate similar speedups when MABSplit is used across a variety of forest-based variants, such as Extremely Random Forests and Random Patches. We also show our algorithm can be used in both classification and regression tasks. Finally, we show that MABSplit outperforms existing methods in generalization performance and feature importance calculations under a fixed computational budget. All of our experimental results are reproducible via a one-line script at https://github.com/ThrunGroup/FastForest.