 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanditCAT and AutoIRT: Machine Learning Approaches to Computerized Adaptive Testing and Item Calibration
Oct 28, 2024

In this paper, we present a complete framework for quickly calibrating and administering a robust large-scale computerized adaptive test (CAT) with a small number of responses. Calibration - learning item parameters in a test - is done using AutoIRT, a new method that uses automated machine learning (AutoML) in combination with item response theory (IRT), originally proposed in [Sharpnack et al., 2024]. AutoIRT trains a non-parametric AutoML grading model using item features, followed by an item-specific parametric model, which results in an explanatory IRT model. In our work, we use tabular AutoML tools (AutoGluon.tabular, [Erickson et al., 2020]) along with BERT embeddings and linguistically motivated NLP features. In this framework, we use Bayesian updating to obtain test taker ability posterior distributions for administration and scoring. For administration of our adaptive test, we propose the BanditCAT framework, a methodology motivated by casting the problem in the contextual bandit framework and utilizing item response theory (IRT). The key insight lies in defining the bandit reward as the Fisher information for the selected item, given the latent test taker ability from IRT assumptions. We use Thompson sampling to balance between exploring items with different psychometric characteristics and selecting highly discriminative items that give more precise information about ability. To control item exposure, we inject noise through an additional randomization step before computing the Fisher information. This framework was used to initially launch two new item types on the DET practice test using limited training data. We outline some reliability and exposure metrics for the 5 practice test experiments that utilized this framework.
AutoIRT: Calibrating Item Response Theory Models with Automated Machine Learning
Sep 13, 2024



Item response theory (IRT) is a class of interpretable factor models that are widely used in computerized adaptive tests (CATs), such as language proficiency tests. Traditionally, these are fit using parametric mixed effects models on the probability of a test taker getting the correct answer to a test item (i.e., question). Neural net extensions of these models, such as BertIRT, require specialized architectures and parameter tuning. We propose a multistage fitting procedure that is compatible with out-of-the-box Automated Machine Learning (AutoML) tools. It is based on a Monte Carlo EM (MCEM) outer loop with a two stage inner loop, which trains a non-parametric AutoML grade model using item features followed by an item specific parametric model. This greatly accelerates the modeling workflow for scoring tests. We demonstrate its effectiveness by applying it to the Duolingo English Test, a high stakes, online English proficiency test. We show that the resulting model is typically more well calibrated, gets better predictive performance, and more accurate scores than existing methods (non-explanatory IRT models and explanatory IRT models like BERT-IRT). Along the way, we provide a brief survey of machine learning methods for calibration of item parameters for CATs.
From Tarzan to Tolkien: Controlling the Language Proficiency Level of LLMs for Content Generation
Jun 05, 2024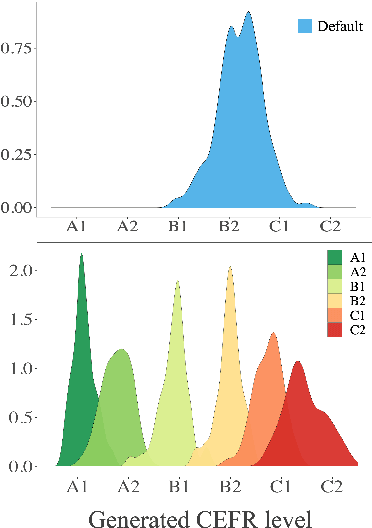
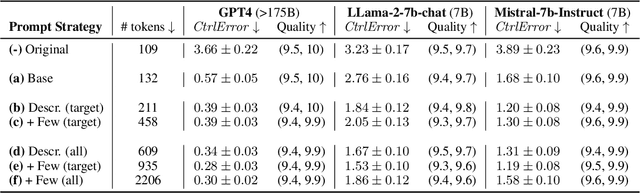
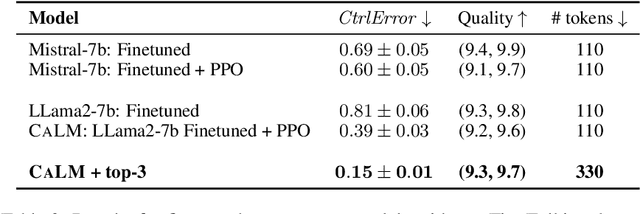
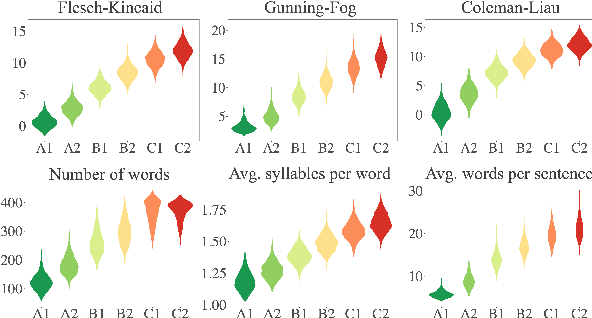
We study the problem of controlling the difficulty level of text generated by Large Language Models (LLMs) for contexts where end-users are not fully proficient, such as language learners. Using a novel framework, we evaluate the effectiveness of several key approaches for this task, including few-shot prompting, supervised finetuning, and reinforcement learning (RL), utilising both GPT-4 and open source alternatives like LLama2-7B and Mistral-7B. Our findings reveal a large performance gap between GPT-4 and the open source models when using prompt-based strategies. However, we show how to bridge this gap with a careful combination of finetuning and RL alignment. Our best model, CALM (CEFR-Aligned Language Model), surpasses the performance of GPT-4 and other strategies, at only a fraction of the cost. We further validate the quality of our results through a small-scale human study.
Local word statistics affect reading times independently of surprisal
Mar 15, 2021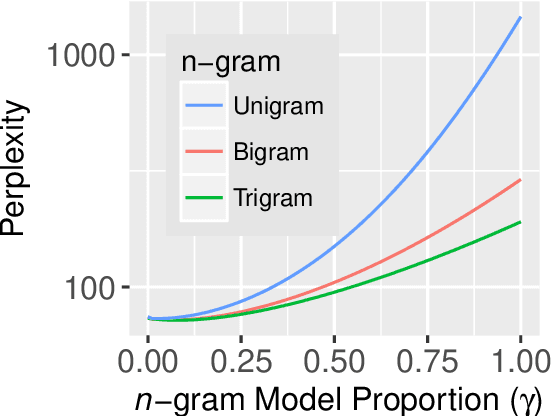
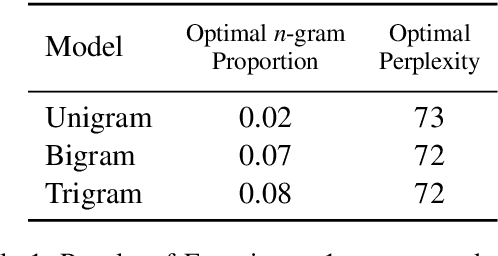

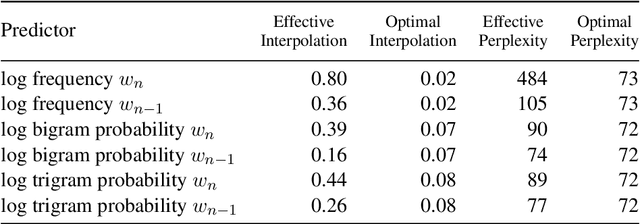
Surprisal theory has provided a unifying framework for understanding many phenomena in sentence processing (Hale, 2001; Levy, 2008a), positing that a word's conditional probability given all prior context fully determines processing difficulty. Problematically for this claim, one local statistic, word frequency, has also been shown to affect processing, even when conditional probability given context is held constant. Here, we ask whether other local statistics have a role in processing, or whether word frequency is a special case. We present the first clear evidence that more complex local statistics, word bigram and trigram probability, also affect processing independently of surprisal. These findings suggest a significant and independent role of local statistics in processing. Further, it motivates research into new generalizations of surprisal that can also explain why local statistical information should have an outsized effect.