 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanditCAT and AutoIRT: Machine Learning Approaches to Computerized Adaptive Testing and Item Calibration
Oct 28, 2024

In this paper, we present a complete framework for quickly calibrating and administering a robust large-scale computerized adaptive test (CAT) with a small number of responses. Calibration - learning item parameters in a test - is done using AutoIRT, a new method that uses automated machine learning (AutoML) in combination with item response theory (IRT), originally proposed in [Sharpnack et al., 2024]. AutoIRT trains a non-parametric AutoML grading model using item features, followed by an item-specific parametric model, which results in an explanatory IRT model. In our work, we use tabular AutoML tools (AutoGluon.tabular, [Erickson et al., 2020]) along with BERT embeddings and linguistically motivated NLP features. In this framework, we use Bayesian updating to obtain test taker ability posterior distributions for administration and scoring. For administration of our adaptive test, we propose the BanditCAT framework, a methodology motivated by casting the problem in the contextual bandit framework and utilizing item response theory (IRT). The key insight lies in defining the bandit reward as the Fisher information for the selected item, given the latent test taker ability from IRT assumptions. We use Thompson sampling to balance between exploring items with different psychometric characteristics and selecting highly discriminative items that give more precise information about ability. To control item exposure, we inject noise through an additional randomization step before computing the Fisher information. This framework was used to initially launch two new item types on the DET practice test using limited training data. We outline some reliability and exposure metrics for the 5 practice test experiments that utilized this framework.
AI-assisted Gaze Detection for Proctoring Online Exams
Sep 25, 2024For high-stakes online exams, it is important to detect potential rule violations to ensure the security of the test. In this study, we investigate the task of detecting whether test takers are looking away from the screen, as such behavior could be an indication that the test taker is consulting external resources. For asynchronous proctoring, the exam videos are recorded and reviewed by the proctors. However, when the length of the exam is long, it could be tedious for proctors to watch entire exam videos to determine the exact moments when test takers look away. We present an AI-assisted gaze detection system, which allows proctors to navigate between different video frames and discover video frames where the test taker is looking in similar directions. The system enables proctors to work more effectively to identify suspicious moments in videos. An evaluation framework is proposed to evaluate the system against human-only and ML-only proctoring, and a user study is conducted to gather feedback from proctors, aiming to demonstrate the effectiveness of the system.
AutoIRT: Calibrating Item Response Theory Models with Automated Machine Learning
Sep 13, 2024



Item response theory (IRT) is a class of interpretable factor models that are widely used in computerized adaptive tests (CATs), such as language proficiency tests. Traditionally, these are fit using parametric mixed effects models on the probability of a test taker getting the correct answer to a test item (i.e., question). Neural net extensions of these models, such as BertIRT, require specialized architectures and parameter tuning. We propose a multistage fitting procedure that is compatible with out-of-the-box Automated Machine Learning (AutoML) tools. It is based on a Monte Carlo EM (MCEM) outer loop with a two stage inner loop, which trains a non-parametric AutoML grade model using item features followed by an item specific parametric model. This greatly accelerates the modeling workflow for scoring tests. We demonstrate its effectiveness by applying it to the Duolingo English Test, a high stakes, online English proficiency test. We show that the resulting model is typically more well calibrated, gets better predictive performance, and more accurate scores than existing methods (non-explanatory IRT models and explanatory IRT models like BERT-IRT). Along the way, we provide a brief survey of machine learning methods for calibration of item parameters for CATs.
Improving Lung Cancer Diagnosis and Survival Prediction with Deep Learning and CT Imaging
Aug 18, 2024



Lung cancer is a major cause of cancer-related deaths, and early diagnosis and treatment are crucial for improving patients' survival outcomes. In this paper, we propose to employ convolutional neural networks to model the non-linear relationship between the risk of lung cancer and the lungs' morphology revealed in the CT images. We apply a mini-batched loss that extends the Cox proportional hazards model to handle the non-convexity induced by neural networks, which also enables the training of large data sets. Additionally, we propose to combine mini-batched loss and binary cross-entropy to predict both lung cancer occurrence and the risk of mortality. Simulation results demonstrate the effectiveness of both the mini-batched loss with and without the censoring mechanism, as well as its combination with binary cross-entropy. We evaluate our approach on the National Lung Screening Trial data set with several 3D convolutional neural network architectures, achieving high AUC and C-index scores for lung cancer classification and survival prediction. These results, obtained from simulations and real data experiments, highlight the potential of our approach to improving the diagnosis and treatment of lung cancer.
RLSbench: Domain Adaptation Under Relaxed Label Shift
Feb 06, 2023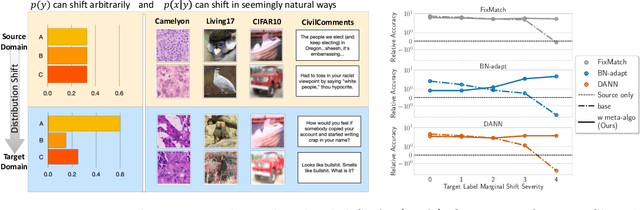
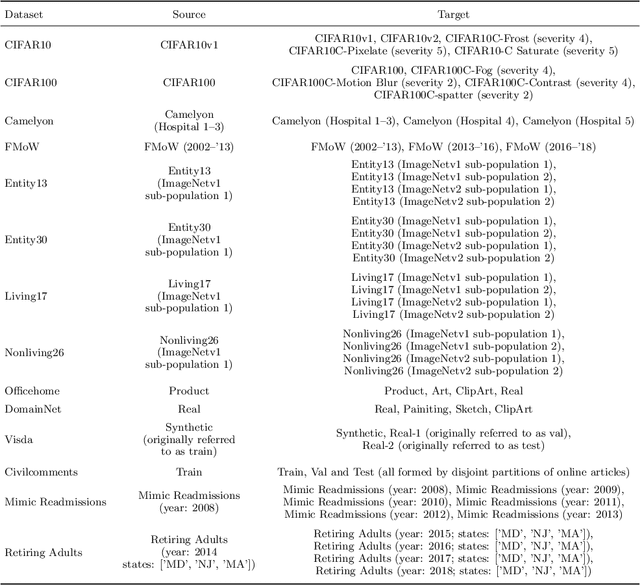
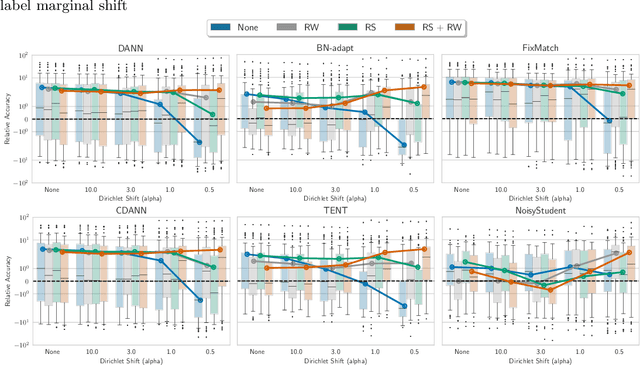
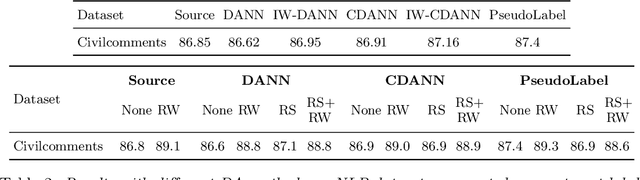
Despite the emergence of principled methods for domain adaptation under label shift, the sensitivity of these methods for minor shifts in the class conditional distributions remains precariously under explored. Meanwhile, popular deep domain adaptation heuristics tend to falter when faced with shifts in label proportions. While several papers attempt to adapt these heuristics to accommodate shifts in label proportions, inconsistencies in evaluation criteria, datasets, and baselines, make it hard to assess the state of the art. In this paper, we introduce RLSbench, a large-scale relaxed label shift benchmark, consisting of >500 distribution shift pairs that draw on 14 datasets across vision, tabular, and language modalities and compose them with varying label proportions. First, we evaluate 13 popular domain adaptation methods, demonstrating more widespread failures under label proportion shifts than were previously known. Next, we develop an effective two-step meta-algorithm that is compatible with most deep domain adaptation heuristics: (i) pseudo-balance the data at each epoch; and (ii) adjust the final classifier with (an estimate of) target label distribution. The meta-algorithm improves existing domain adaptation heuristics often by 2--10\% accuracy points under extreme label proportion shifts and has little (i.e., <0.5\%) effect when label proportions do not shift. We hope that these findings and the availability of RLSbench will encourage researchers to rigorously evaluate proposed methods in relaxed label shift settings. Code is publicly available at https://github.com/acmi-lab/RLSbench.
Syndicated Bandits: A Framework for Auto Tuning Hyper-parameters in Contextual Bandit Algorithms
Jun 05, 2021
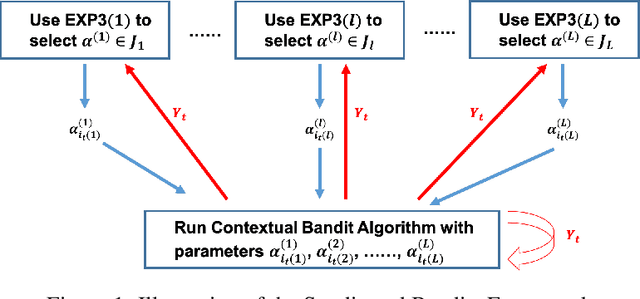

The stochastic contextual bandit problem, which models the trade-off between exploration and exploitation, has many real applications, including recommender systems, online advertising and clinical trials. As many other machine learning algorithms, contextual bandit algorithms often have one or more hyper-parameters. As an example, in most optimal stochastic contextual bandit algorithms, there is an unknown exploration parameter which controls the trade-off between exploration and exploitation. A proper choice of the hyper-parameters is essential for contextual bandit algorithms to perform well. However, it is infeasible to use offline tuning methods to select hyper-parameters in contextual bandit environment since there is no pre-collected dataset and the decisions have to be made in real time. To tackle this problem, we first propose a two-layer bandit structure for auto tuning the exploration parameter and further generalize it to the Syndicated Bandits framework which can learn multiple hyper-parameters dynamically in contextual bandit environment. We show our Syndicated Bandits framework can achieve the optimal regret upper bounds and is general enough to handle the tuning tasks in many popular contextual bandit algorithms, such as LinUCB, LinTS, UCB-GLM, etc. Experiments on both synthetic and real datasets validate the effectiveness of our proposed framework.
Robust Stochastic Linear Contextual Bandits Under Adversarial Attacks
Jun 05, 2021
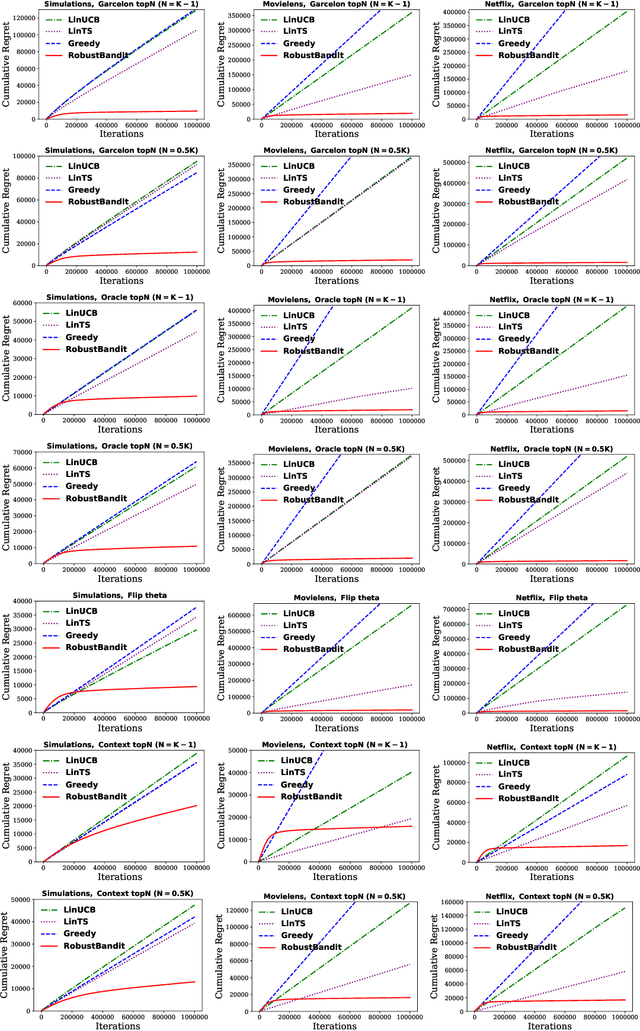

Stochastic linear contextual bandit algorithms have substantial applications in practice, such as recommender systems, online advertising, clinical trials, etc. Recent works show that optimal bandit algorithms are vulnerable to adversarial attacks and can fail completely in the presence of attacks. Existing robust bandit algorithms only work for the non-contextual setting under the attack of rewards and cannot improve the robustness in the general and popular contextual bandit environment. In addition, none of the existing methods can defend against attacked context. In this work, we provide the first robust bandit algorithm for stochastic linear contextual bandit setting under a fully adaptive and omniscient attack. Our algorithm not only works under the attack of rewards, but also under attacked context. Moreover, it does not need any information about the attack budget or the particular form of the attack. We provide theoretical guarantees for our proposed algorithm and show by extensive experiments that our proposed algorithm significantly improves the robustness against various kinds of popular attacks.
An Efficient Algorithm For Generalized Linear Bandit: Online Stochastic Gradient Descent and Thompson Sampling
Jun 07, 2020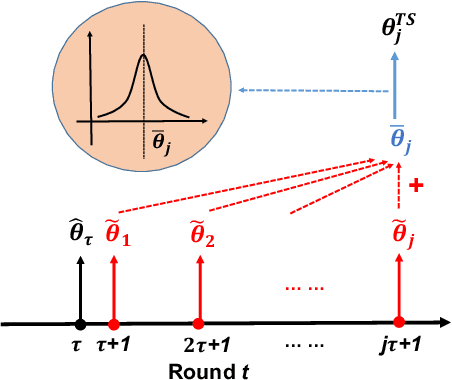

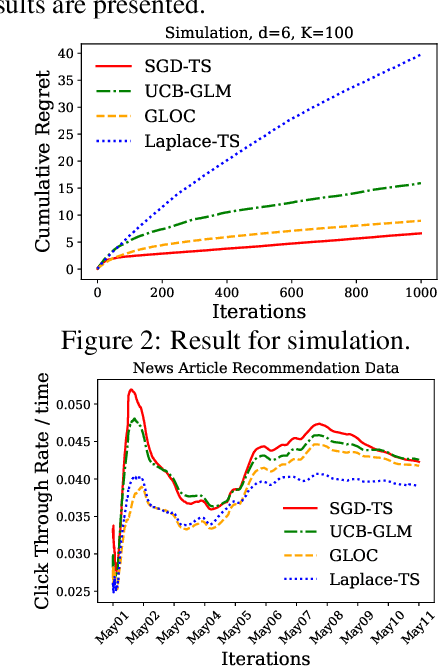
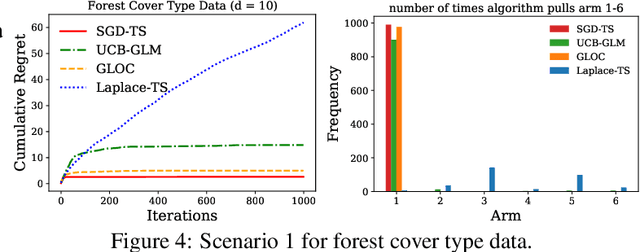
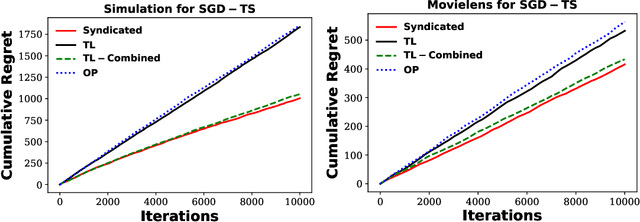
We consider the contextual bandit problem, where a player sequentially makes decisions based on past observations to maximize the cumulative reward. Although many algorithms have been proposed for contextual bandit, most of them rely on finding the maximum likelihood estimator at each iteration, which requires $O(t)$ time at the $t$-th iteration and are memory inefficient. A natural way to resolve this problem is to apply online stochastic gradient descent (SGD) so that the per-step time and memory complexity can be reduced to constant with respect to $t$, but a contextual bandit policy based on online SGD updates that balances exploration and exploitation has remained elusive. In this work, we show that online SGD can be applied to the generalized linear bandit problem. The proposed SGD-TS algorithm, which uses a single-step SGD update to exploit past information and uses Thompson Sampling for exploration, achieves $\tilde{O}(\sqrt{dT})$ regret with the total time complexity that scales linearly in $T$ and $d$, where $T$ is the total number of rounds and $d$ is the number of features. Experimental results show that SGD-TS consistently outperforms existing algorithms on both synthetic and real datasets.
Multiscale Non-stationary Stochastic Bandits
Feb 13, 2020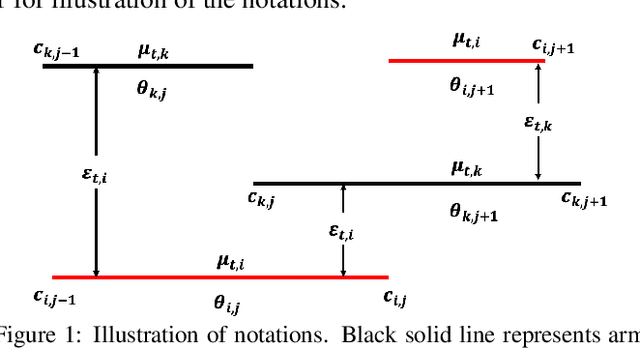


Classic contextual bandit algorithms for linear models, such as LinUCB, assume that the reward distribution for an arm is modeled by a stationary linear regression. When the linear regression model is non-stationary over time, the regret of LinUCB can scale linearly with time. In this paper, we propose a novel multiscale changepoint detection method for the non-stationary linear bandit problems, called Multiscale-LinUCB, which actively adapts to the changing environment. We also provide theoretical analysis of regret bound for Multiscale-LinUCB algorithm. Experimental results show that our proposed Multiscale-LinUCB algorithm outperforms other state-of-the-art algorithms in non-stationary contextual environments.
Unsupervised Object Segmentation with Explicit Localization Module
Nov 21, 2019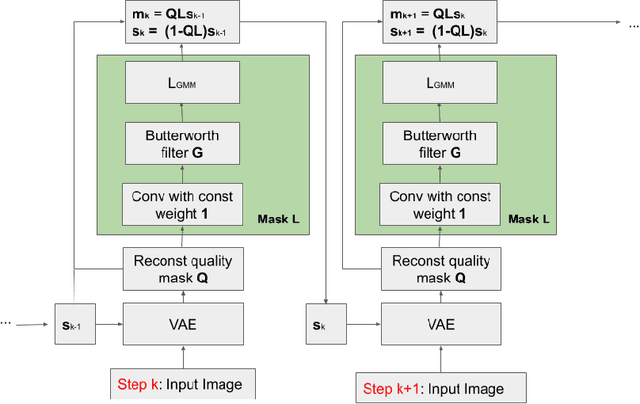


In this paper, we propose a novel architecture that iteratively discovers and segments out the objects of a scene based on the image reconstruction quality. Different from other approaches, our model uses an explicit localization module that localizes objects of the scene based on the pixel-level reconstruction qualities at each iteration, where simpler objects tend to be reconstructed better at earlier iterations and thus are segmented out first. We show that our localization module improves the quality of the segmentation, especially on a challenging background.