 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding
Dec 12, 2025The growing demand for long-context inference capabilities in Large Language Models (LLMs) has intensified the computational and memory bottlenecks inherent to the standard attention mechanism. To address this challenge, we introduce BLASST, a drop-in sparse attention method that dynamically prunes the attention matrix without any pre-computation or proxy scores. Our method uses a fixed threshold and existing information from online softmax to identify negligible attention scores, skipping softmax computation, Value block loading, and the subsequent matrix multiplication. This fits seamlessly into existing FlashAttention kernel designs with negligible latency overhead. The approach is applicable to both prefill and decode stages across all attention variants (MHA, GQA, MQA, and MLA), providing a unified solution for accelerating long-context inference. We develop an automated calibration procedure that reveals a simple inverse relationship between optimal threshold and context length, enabling robust deployment across diverse scenarios. Maintaining high accuracy, we demonstrate a 1.62x speedup for prefill at 74.7% sparsity and a 1.48x speedup for decode at 73.2% sparsity on modern GPUs. Furthermore, we explore sparsity-aware training as a natural extension, showing that models can be trained to be inherently more robust to sparse attention patterns, pushing the accuracy-sparsity frontier even further.
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Apr 19, 2024



Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
The Sparsity Roofline: Understanding the Hardware Limits of Sparse Neural Networks
Sep 30, 2023



We introduce the Sparsity Roofline, a visual performance model for evaluating sparsity in neural networks. The Sparsity Roofline jointly models network accuracy, sparsity, and predicted inference speedup. Our approach does not require implementing and benchmarking optimized kernels, and the predicted speedup is equal to what would be measured when the corresponding dense and sparse kernels are equally well-optimized. We achieve this through a novel analytical model for predicting sparse network performance, and validate the predicted speedup using several real-world computer vision architectures pruned across a range of sparsity patterns and degrees. We demonstrate the utility and ease-of-use of our model through two case studies: (1) we show how machine learning researchers can predict the performance of unimplemented or unoptimized block-structured sparsity patterns, and (2) we show how hardware designers can predict the performance implications of new sparsity patterns and sparse data formats in hardware. In both scenarios, the Sparsity Roofline helps performance experts identify sparsity regimes with the highest performance potential.
Building a Performance Model for Deep Learning Recommendation Model Training on GPUs
Jan 19, 2022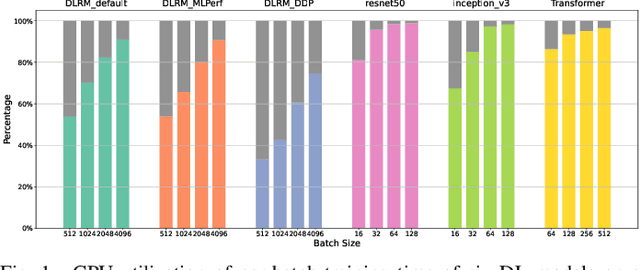
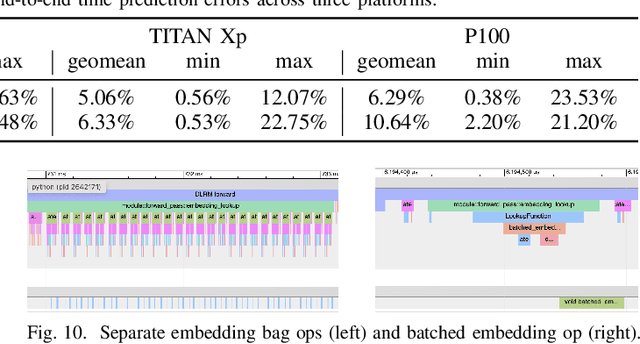

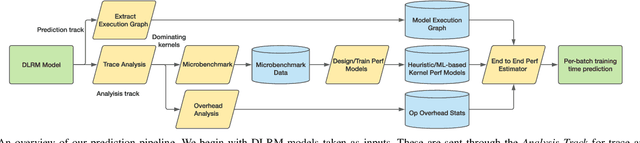
We devise a performance model for GPU training of Deep Learning Recommendation Models (DLRM), whose GPU utilization is low compared to other well-optimized CV and NLP models. We show that both the device active time (the sum of kernel runtimes) and the device idle time are important components of the overall device time. We therefore tackle them separately by (1) flexibly adopting heuristic-based and ML-based kernel performance models for operators that dominate the device active time, and (2) categorizing operator overheads into five types to determine quantitatively their contribution to the device active time. Combining these two parts, we propose a critical-path-based algorithm to predict the per-batch training time of DLRM by traversing its execution graph. We achieve less than 10% geometric mean average error (GMAE) in all kernel performance modeling, and 5.23% and 7.96% geomean errors for GPU active time and overall end-to-end per-batch training time prediction, respectively. We show that our general performance model not only achieves low prediction error on DLRM, which has highly customized configurations and is dominated by multiple factors, but also yields comparable accuracy on other compute-bound ML models targeted by most previous methods. Using this performance model and graph-level data and task dependency analyses, we show our system can provide more general model-system co-design than previous methods.
Energy-based Out-of-distribution Detection
Oct 13, 2020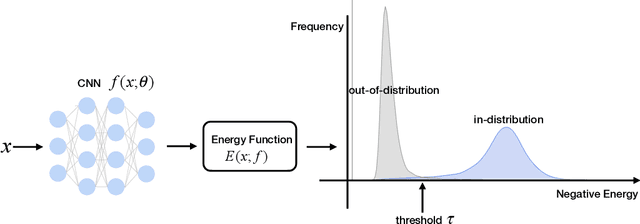
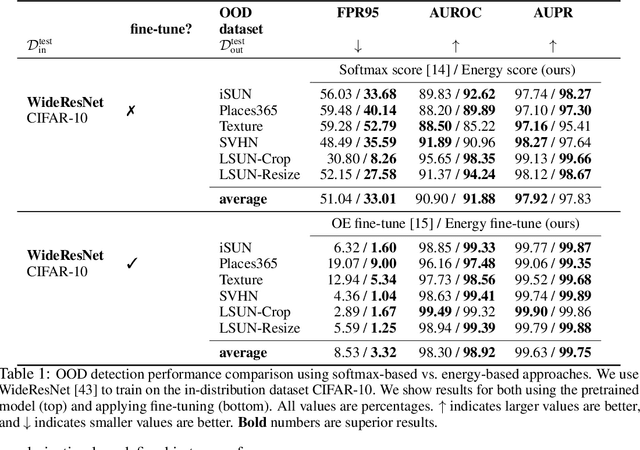
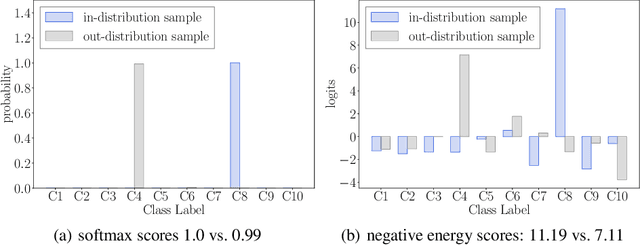
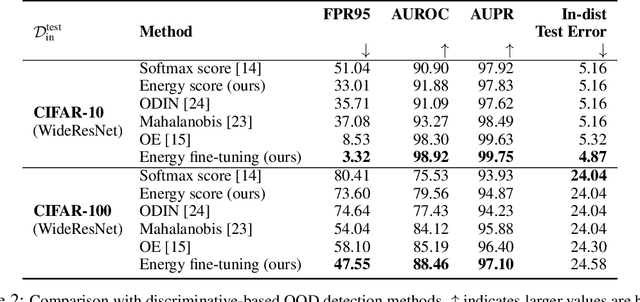
Determining whether inputs are out-of-distribution (OOD) is an essential building block for safely deploying machine learning models in the open world. However, previous methods relying on the softmax confidence score suffer from overconfident posterior distributions for OOD data. We propose a unified framework for OOD detection that uses an energy score. We show that energy scores better distinguish in- and out-of-distribution samples than the traditional approach using the softmax scores. Unlike softmax confidence scores, energy scores are theoretically aligned with the probability density of the inputs and are less susceptible to the overconfidence issue. Within this framework, energy can be flexibly used as a scoring function for any pre-trained neural classifier as well as a trainable cost function to shape the energy surface explicitly for OOD detection. On a CIFAR-10 pre-trained WideResNet, using the energy score reduces the average FPR (at TPR 95%) by 18.03% compared to the softmax confidence score. With energy-based training, our method outperforms the state-of-the-art on common benchmarks.
Unsupervised Object Segmentation with Explicit Localization Module
Nov 21, 2019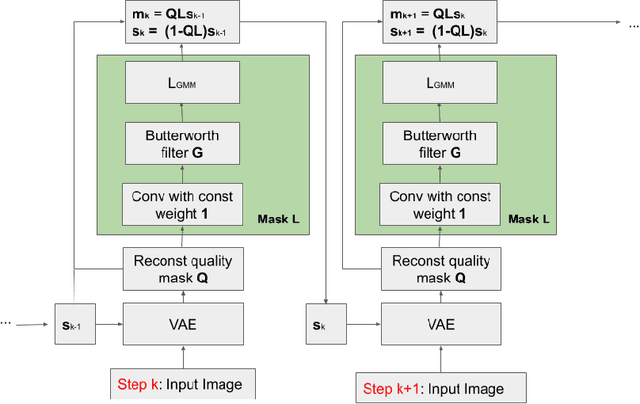


In this paper, we propose a novel architecture that iteratively discovers and segments out the objects of a scene based on the image reconstruction quality. Different from other approaches, our model uses an explicit localization module that localizes objects of the scene based on the pixel-level reconstruction qualities at each iteration, where simpler objects tend to be reconstructed better at earlier iterations and thus are segmented out first. We show that our localization module improves the quality of the segmentation, especially on a challenging background.
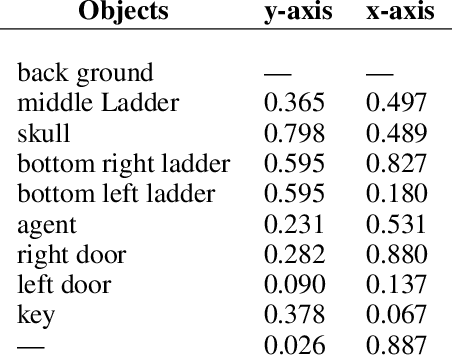
Object Localization and Motion Transfer learning with Capsules
May 20, 2018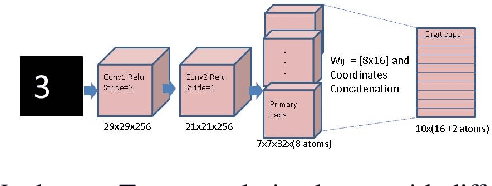
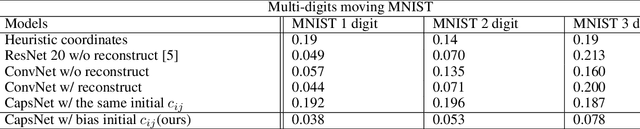
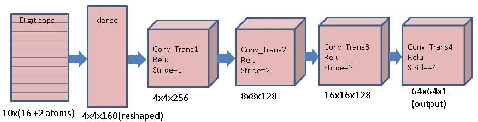

Inspired by CapsNet's routing-by-agreement mechanism, with its ability to learn object properties, and by center-of-mass calculations from physics, we propose a CapsNet architecture with object coordinate atoms and an LSTM network for evaluation. The first is based on CapsNet but uses a new routing algorithm to find the objects' approximate positions in the image coordinate system, and the second is a parameterized affine transformation network that can predict future positions from past positions by learning the translation transformation from 2D object coordinates generated from the first network. We demonstrate the learned translation transformation is transferable to another dataset without the need to train the transformation network again. Only the CapsNet needs training on the new dataset. As a result, our work shows that object recognition and motion prediction can be separated, and that motion prediction can be transferred to another dataset with different object types.