 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIris: First-Class Multi-GPU Programming Experience in Triton
Nov 16, 2025Multi-GPU programming traditionally requires developers to navigate complex trade-offs between performance and programmability. High-performance implementations typically rely on low-level HIP/CUDA communication libraries that demand substantial engineering effort for even basic overlap patterns, while simpler abstractions often sacrifice performance. We present Iris, a multi-GPU communication library implemented entirely in Python and Triton that eliminates this trade-off. Iris provides tile-based symmetric memory abstractions that naturally align with Triton's programming model, enabling developers to write single-source kernels that seamlessly interleave computation and communication. We demonstrate a taxonomy of compute-communication overlap patterns--from bulk-synchronous to fine-grained workgroup specialization--that can be implemented with minimal code changes in Iris, often requiring just a few additional lines within the same Triton kernel. Our evaluation shows that Iris achieves near-optimal bandwidth utilization in microbenchmarks and delivers up to 1.79x speedup over PyTorch and RCCL for GEMM+All-Scatter workloads, demonstrating that high-level implementations can match or exceed heavily-optimized libraries while dramatically simplifying multi-GPU programming.
HipKittens: Fast and Furious AMD Kernels
Nov 11, 2025AMD GPUs offer state-of-the-art compute and memory bandwidth; however, peak performance AMD kernels are written in raw assembly. To address the difficulty of mapping AI algorithms to hardware, recent work proposes C++ embedded and PyTorch-inspired domain-specific languages like ThunderKittens (TK) to simplify high performance AI kernel development on NVIDIA hardware. We explore the extent to which such primitives -- for explicit tile-based programming with optimized memory accesses and fine-grained asynchronous execution across workers -- are NVIDIA-specific or general. We provide the first detailed study of the programming primitives that lead to performant AMD AI kernels, and we encapsulate these insights in the HipKittens (HK) programming framework. We find that tile-based abstractions used in prior DSLs generalize to AMD GPUs, however we need to rethink the algorithms that instantiate these abstractions for AMD. We validate the HK primitives across CDNA3 and CDNA4 AMD platforms. In evaluations, HK kernels compete with AMD's hand-optimized assembly kernels for GEMMs and attention, and consistently outperform compiler baselines. Moreover, assembly is difficult to scale to the breadth of AI workloads; reflecting this, in some settings HK outperforms all available kernel baselines by $1.2-2.4\times$ (e.g., $d=64$ attention, GQA backwards, memory-bound kernels). These findings help pave the way for a single, tile-based software layer for high-performance AI kernels that translates across GPU vendors. HipKittens is released at: https://github.com/HazyResearch/HipKittens.
The Sparsity Roofline: Understanding the Hardware Limits of Sparse Neural Networks
Sep 30, 2023We introduce the Sparsity Roofline, a visual performance model for evaluating sparsity in neural networks. The Sparsity Roofline jointly models network accuracy, sparsity, and predicted inference speedup. Our approach does not require implementing and benchmarking optimized kernels, and the predicted speedup is equal to what would be measured when the corresponding dense and sparse kernels are equally well-optimized. We achieve this through a novel analytical model for predicting sparse network performance, and validate the predicted speedup using several real-world computer vision architectures pruned across a range of sparsity patterns and degrees. We demonstrate the utility and ease-of-use of our model through two case studies: (1) we show how machine learning researchers can predict the performance of unimplemented or unoptimized block-structured sparsity patterns, and (2) we show how hardware designers can predict the performance implications of new sparsity patterns and sparse data formats in hardware. In both scenarios, the Sparsity Roofline helps performance experts identify sparsity regimes with the highest performance potential.
Distributionally Robust Learning in Heterogeneous Contexts
May 18, 2021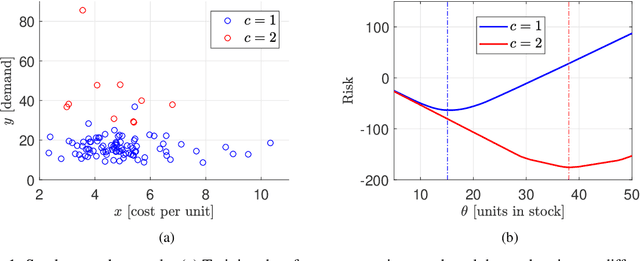
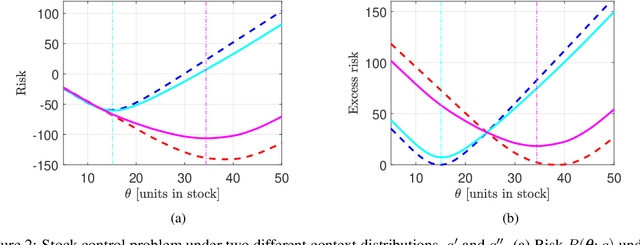
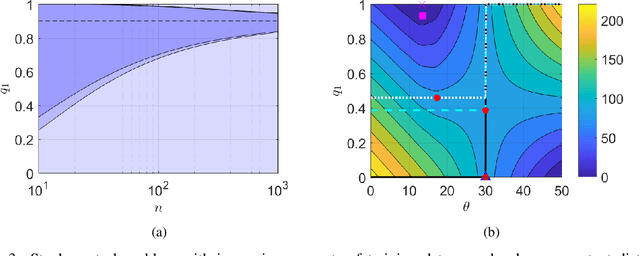

We consider the problem of learning from training data obtained in different contexts, where the test data is subject to distributional shifts. We develop a distributionally robust method that focuses on excess risks and achieves a more appropriate trade-off between performance and robustness than the conventional and overly conservative minimax approach. The proposed method is computationally feasible and provides statistical guarantees. We demonstrate its performance using both real and synthetic data.
Prediction of Spatial Point Processes: Regularized Method with Out-of-Sample Guarantees
Jul 03, 2020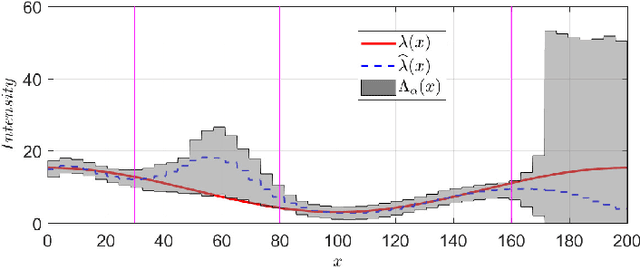


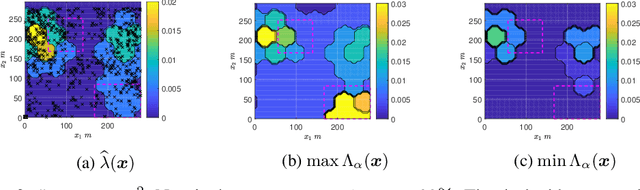
A spatial point process can be characterized by an intensity function which predicts the number of events that occur across space. In this paper, we develop a method to infer predictive intensity intervals by learning a spatial model using a regularized criterion. We prove that the proposed method exhibits out-of-sample prediction performance guarantees which, unlike standard estimators, are valid even when the spatial model is misspecified. The method is demonstrated using synthetic as well as real spatial data.
Learning Robust Decision Policies from Observational Data
Jun 03, 2020

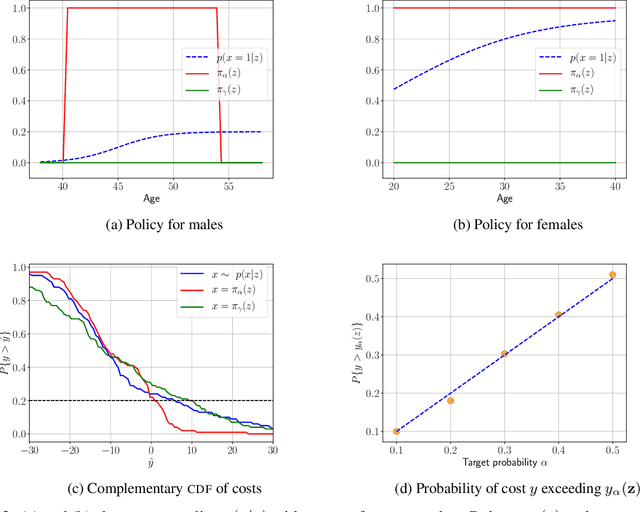

We address the problem of learning a decision policy from observational data of past decisions in contexts with features and associated outcomes. The past policy maybe unknown and in safety-critical applications, such as medical decision support, it is of interest to learn robust policies that reduce the risk of outcomes with high costs. In this paper, we develop a method for learning policies that reduce tails of the cost distribution at a specified level and, moreover, provide a statistically valid bound on the cost of each decision. These properties are valid under finite samples -- even in scenarios with uneven or no overlap between features for different decisions in the observed data -- by building on recent results in conformal prediction. The performance and statistical properties of the proposed method are illustrated using both real and synthetic data.
DENS: A Dataset for Multi-class Emotion Analysis
Oct 25, 2019


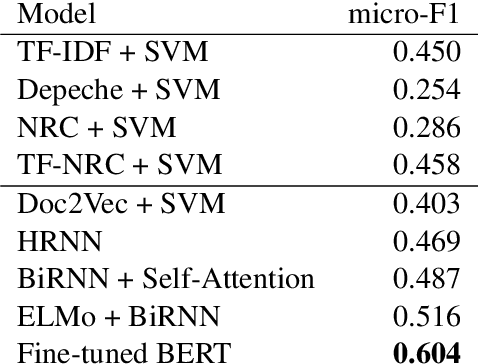
We introduce a new dataset for multi-class emotion analysis from long-form narratives in English. The Dataset for Emotions of Narrative Sequences (DENS) was collected from both classic literature available on Project Gutenberg and modern online narratives available on Wattpad, annotated using Amazon Mechanical Turk. A number of statistics and baseline benchmarks are provided for the dataset. Of the tested techniques, we find that the fine-tuning of a pre-trained BERT model achieves the best results, with an average micro-F1 score of 60.4%. Our results show that the dataset provides a novel opportunity in emotion analysis that requires moving beyond existing sentence-level techniques.
Exploring Multilingual Syntactic Sentence Representations
Oct 25, 2019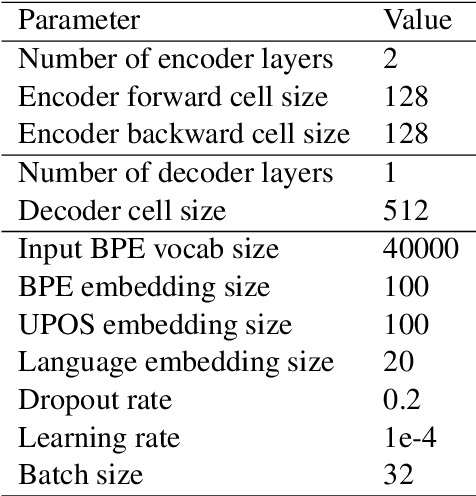
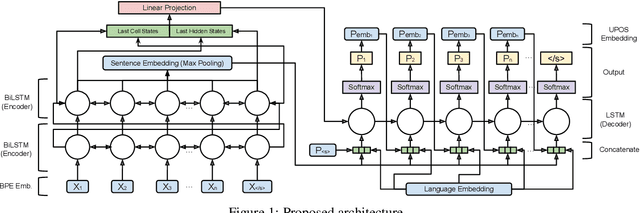
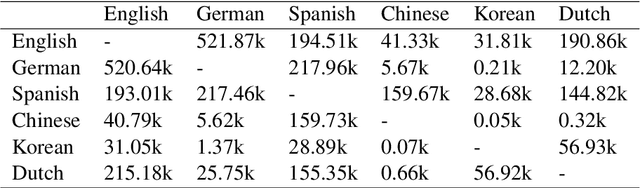
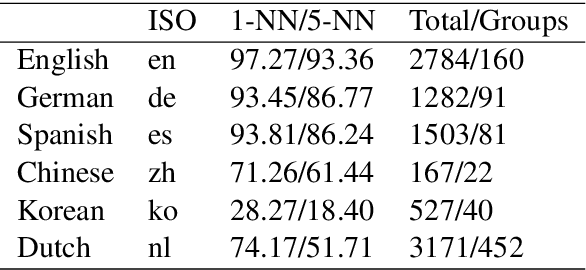
We study methods for learning sentence embeddings with syntactic structure. We focus on methods of learning syntactic sentence-embeddings by using a multilingual parallel-corpus augmented by Universal Parts-of-Speech tags. We evaluate the quality of the learned embeddings by examining sentence-level nearest neighbours and functional dissimilarity in the embedding space. We also evaluate the ability of the method to learn syntactic sentence-embeddings for low-resource languages and demonstrate strong evidence for transfer learning. Our results show that syntactic sentence-embeddings can be learned while using less training data, fewer model parameters, and resulting in better evaluation metrics than state-of-the-art language models.
Robust Risk Minimization for Statistical Learning
Oct 03, 2019

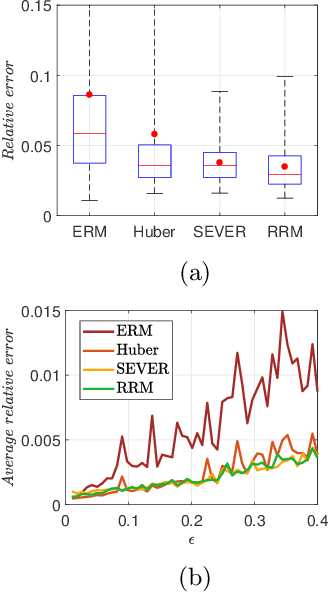

We consider a general statistical learning problem where an unknown fraction of the training data is corrupted. We develop a robust learning method that only requires specifying an upper bound on the corrupted data fraction. The method is formulated as a risk minimization problem that can be solved using a blockwise coordinate descent algorithm. We demonstrate the wide range applicability of the method, including regression, classification, unsupervised learning and classic parameter estimation, with state-of-the-art performance.
Inferring Heterogeneous Causal Effects in Presence of Spatial Confounding
Jan 28, 2019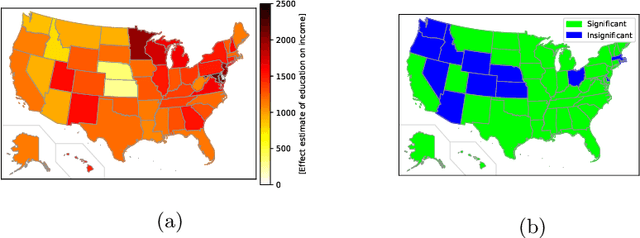
We address the problem of inferring the causal effect of an exposure on an outcome across space, using observational data. The data is possibly subject to unmeasured confounding variables which, in a standard approach, must be adjusted for by estimating a nuisance function. Here we develop a method that eliminates the nuisance function, while mitigating the resulting errors-in-variables. The result is a robust and accurate inference method for spatially varying heterogeneous causal effects. The properties of the method are demonstrated on synthetic as well as real data from Germany and the US.