Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Learning in Heterogeneous Contexts
Paper and Code
May 18, 2021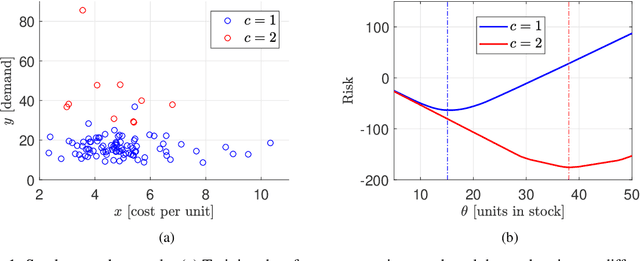
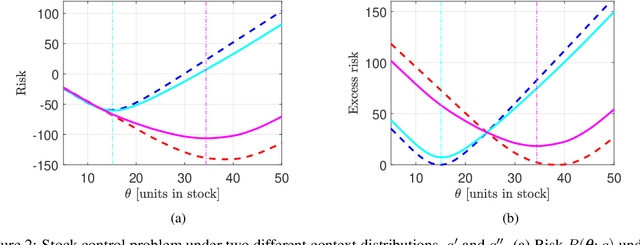
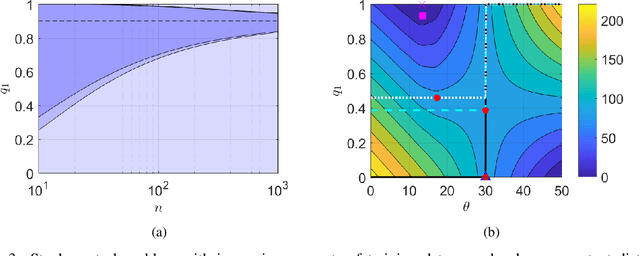

We consider the problem of learning from training data obtained in different contexts, where the test data is subject to distributional shifts. We develop a distributionally robust method that focuses on excess risks and achieves a more appropriate trade-off between performance and robustness than the conventional and overly conservative minimax approach. The proposed method is computationally feasible and provides statistical guarantees. We demonstrate its performance using both real and synthetic data.
View paper on