Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDENS: A Dataset for Multi-class Emotion Analysis
Paper and Code
Oct 25, 2019


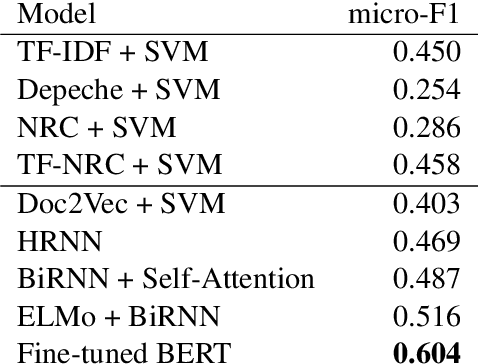
We introduce a new dataset for multi-class emotion analysis from long-form narratives in English. The Dataset for Emotions of Narrative Sequences (DENS) was collected from both classic literature available on Project Gutenberg and modern online narratives available on Wattpad, annotated using Amazon Mechanical Turk. A number of statistics and baseline benchmarks are provided for the dataset. Of the tested techniques, we find that the fine-tuning of a pre-trained BERT model achieves the best results, with an average micro-F1 score of 60.4%. Our results show that the dataset provides a novel opportunity in emotion analysis that requires moving beyond existing sentence-level techniques.
* Accepted to EMNLP 2019
View paper on