 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Basics: Revisiting ASR in the Age of Voice Agents
Mar 26, 2026Automatic speech recognition (ASR) systems have achieved near-human accuracy on curated benchmarks, yet still fail in real-world voice agents under conditions that current evaluations do not systematically cover. Without diagnostic tools that isolate specific failure factors, practitioners cannot anticipate which conditions, in which languages, will cause what degree of degradation. We introduce WildASR, a multilingual (four-language) diagnostic benchmark sourced entirely from real human speech that factorizes ASR robustness along three axes: environmental degradation, demographic shift, and linguistic diversity. Evaluating seven widely used ASR systems, we find severe and uneven performance degradation, and model robustness does not transfer across languages or conditions. Critically, models often hallucinate plausible but unspoken content under partial or degraded inputs, creating concrete safety risks for downstream agent behavior. Our results demonstrate that targeted, factor-isolated evaluation is essential for understanding and improving ASR reliability in production systems. Besides the benchmark itself, we also present three analytical tools that practitioners can use to guide deployment decisions.
EmergentTTS-Eval: Evaluating TTS Models on Complex Prosodic, Expressiveness, and Linguistic Challenges Using Model-as-a-Judge
May 29, 2025Text-to-Speech (TTS) benchmarks often fail to capture how well models handle nuanced and semantically complex text. Building on $\textit{EmergentTTS}$, we introduce $\textit{EmergentTTS-Eval}$, a comprehensive benchmark covering six challenging TTS scenarios: emotions, paralinguistics, foreign words, syntactic complexity, complex pronunciation (e.g. URLs, formulas), and questions. Crucially, our framework automates both test-case generation and evaluation, making the benchmark easily extensible. Starting from a small set of human-written seed prompts, we iteratively extend them using LLMs to target specific structural, phonetic and prosodic challenges, resulting in 1,645 diverse test cases. Moreover, we employ a model-as-a-judge approach, using a Large Audio Language Model (LALM) to assess the speech across multiple dimensions such as expressed emotion, prosodic, intonational, and pronunciation accuracy. We evaluate state-of-the-art open-source and proprietary TTS systems, such as 11Labs, Deepgram, and OpenAI's 4o-mini-TTS, on EmergentTTS-Eval, demonstrating its ability to reveal fine-grained performance differences. Results show that the model-as-a-judge approach offers robust TTS assessment and a high correlation with human preferences. We open source the evaluation $\href{https://github.com/boson-ai/EmergentTTS-Eval-public}{code}$ and the $\href{https://huggingface.co/datasets/bosonai/EmergentTTS-Eval}{dataset}$.
L3Ms -- Lagrange Large Language Models
Oct 28, 2024



Supervised fine-tuning (SFT) and alignment of large language models (LLMs) are key steps in providing a good user experience. However, the concept of an appropriate alignment is inherently application-dependent, and current methods often rely on heuristic choices to drive the optimization. In this work, we formulate SFT and alignment as a constrained optimization problem, where the LLM is trained on a task while being required to meet application-specific requirements, without resorting to heuristics. To solve this, we propose Lagrange Large Language Models (L3Ms), which employ logarithmic barriers to enforce the constraints. This approach allows for the customization of L3Ms across diverse applications while avoiding heuristic-driven processes. We demonstrate experimentally the versatility and efficacy of L3Ms in achieving tailored alignments for various applications.
A Cheaper and Better Diffusion Language Model with Soft-Masked Noise
Apr 10, 2023Diffusion models that are based on iterative denoising have been recently proposed and leveraged in various generation tasks like image generation. Whereas, as a way inherently built for continuous data, existing diffusion models still have some limitations in modeling discrete data, e.g., languages. For example, the generally used Gaussian noise can not handle the discrete corruption well, and the objectives in continuous spaces fail to be stable for textual data in the diffusion process especially when the dimension is high. To alleviate these issues, we introduce a novel diffusion model for language modeling, Masked-Diffuse LM, with lower training cost and better performances, inspired by linguistic features in languages. Specifically, we design a linguistic-informed forward process which adds corruptions to the text through strategically soft-masking to better noise the textual data. Also, we directly predict the categorical distribution with cross-entropy loss function in every diffusion step to connect the continuous space and discrete space in a more efficient and straightforward way. Through experiments on 5 controlled generation tasks, we demonstrate that our Masked-Diffuse LM can achieve better generation quality than the state-of-the-art diffusion models with better efficiency.
Prompt Pre-Training with Twenty-Thousand Classes for Open-Vocabulary Visual Recognition
Apr 10, 2023



This work proposes POMP, a prompt pre-training method for vision-language models. Being memory and computation efficient, POMP enables the learned prompt to condense semantic information for a rich set of visual concepts with over twenty-thousand classes. Once pre-trained, the prompt with a strong transferable ability can be directly plugged into a variety of visual recognition tasks including image classification, semantic segmentation, and object detection, to boost recognition performances in a zero-shot manner. Empirical evaluation shows that POMP achieves state-of-the-art performances on 21 downstream datasets, e.g., 67.0% average accuracy on 10 classification dataset (+3.1% compared to CoOp) and 84.4 hIoU on open-vocabulary Pascal VOC segmentation (+6.9 compared to ZSSeg).
Multimodal Chain-of-Thought Reasoning in Language Models
Feb 17, 2023



Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. With Multimodal-CoT, our model under 1 billion parameters outperforms the previous state-of-the-art LLM (GPT-3.5) by 16 percentage points (75.17%->91.68% accuracy) on the ScienceQA benchmark and even surpasses human performance. Code is publicly available available at https://github.com/amazon-science/mm-cot.
RLSbench: Domain Adaptation Under Relaxed Label Shift
Feb 06, 2023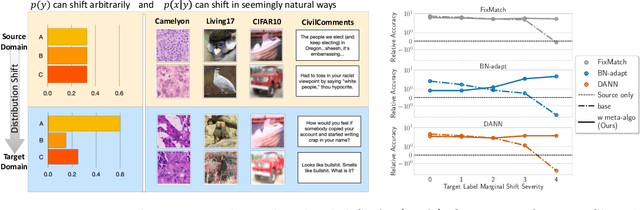
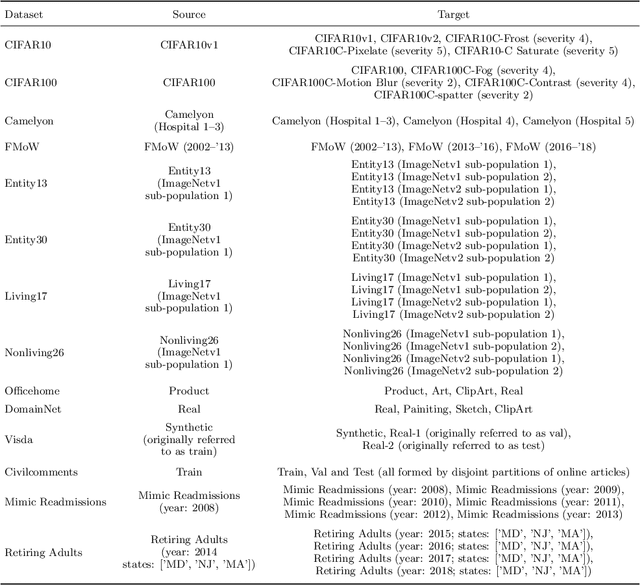
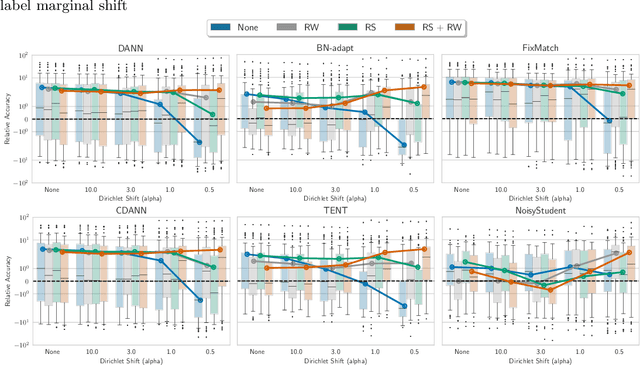
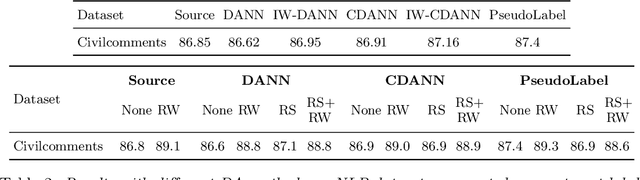
Despite the emergence of principled methods for domain adaptation under label shift, the sensitivity of these methods for minor shifts in the class conditional distributions remains precariously under explored. Meanwhile, popular deep domain adaptation heuristics tend to falter when faced with shifts in label proportions. While several papers attempt to adapt these heuristics to accommodate shifts in label proportions, inconsistencies in evaluation criteria, datasets, and baselines, make it hard to assess the state of the art. In this paper, we introduce RLSbench, a large-scale relaxed label shift benchmark, consisting of >500 distribution shift pairs that draw on 14 datasets across vision, tabular, and language modalities and compose them with varying label proportions. First, we evaluate 13 popular domain adaptation methods, demonstrating more widespread failures under label proportion shifts than were previously known. Next, we develop an effective two-step meta-algorithm that is compatible with most deep domain adaptation heuristics: (i) pseudo-balance the data at each epoch; and (ii) adjust the final classifier with (an estimate of) target label distribution. The meta-algorithm improves existing domain adaptation heuristics often by 2--10\% accuracy points under extreme label proportion shifts and has little (i.e., <0.5\%) effect when label proportions do not shift. We hope that these findings and the availability of RLSbench will encourage researchers to rigorously evaluate proposed methods in relaxed label shift settings. Code is publicly available at https://github.com/acmi-lab/RLSbench.
Parameter-Efficient Fine-Tuning Design Spaces
Jan 04, 2023



Parameter-efficient fine-tuning aims to achieve performance comparable to fine-tuning, using fewer trainable parameters. Several strategies (e.g., Adapters, prefix tuning, BitFit, and LoRA) have been proposed. However, their designs are hand-crafted separately, and it remains unclear whether certain design patterns exist for parameter-efficient fine-tuning. Thus, we present a parameter-efficient fine-tuning design paradigm and discover design patterns that are applicable to different experimental settings. Instead of focusing on designing another individual tuning strategy, we introduce parameter-efficient fine-tuning design spaces that parameterize tuning structures and tuning strategies. Specifically, any design space is characterized by four components: layer grouping, trainable parameter allocation, tunable groups, and strategy assignment. Starting from an initial design space, we progressively refine the space based on the model quality of each design choice and make greedy selection at each stage over these four components. We discover the following design patterns: (i) group layers in a spindle pattern; (ii) allocate the number of trainable parameters to layers uniformly; (iii) tune all the groups; (iv) assign proper tuning strategies to different groups. These design patterns result in new parameter-efficient fine-tuning methods. We show experimentally that these methods consistently and significantly outperform investigated parameter-efficient fine-tuning strategies across different backbone models and different tasks in natural language processing.
Automatic Chain of Thought Prompting in Large Language Models
Oct 07, 2022



Large language models (LLMs) can perform complex reasoning by generating intermediate reasoning steps. Providing these steps for prompting demonstrations is called chain-of-thought (CoT) prompting. CoT prompting has two major paradigms. One leverages a simple prompt like "Let's think step by step" to facilitate step-by-step thinking before answering a question. The other uses a few manual demonstrations one by one, each composed of a question and a reasoning chain that leads to an answer. The superior performance of the second paradigm hinges on the hand-crafting of task-specific demonstrations one by one. We show that such manual efforts may be eliminated by leveraging LLMs with the "Let's think step by step" prompt to generate reasoning chains for demonstrations one by one, i.e., let's think not just step by step, but also one by one. However, these generated chains often come with mistakes. To mitigate the effect of such mistakes, we find that diversity matters for automatically constructing demonstrations. We propose an automatic CoT prompting method: Auto-CoT. It samples questions with diversity and generates reasoning chains to construct demonstrations. On ten public benchmark reasoning tasks with GPT-3, Auto-CoT consistently matches or exceeds the performance of the CoT paradigm that requires manual designs of demonstrations. Code is available at https://github.com/amazon-research/auto-cot
Partial and Asymmetric Contrastive Learning for Out-of-Distribution Detection in Long-Tailed Recognition
Jul 04, 2022

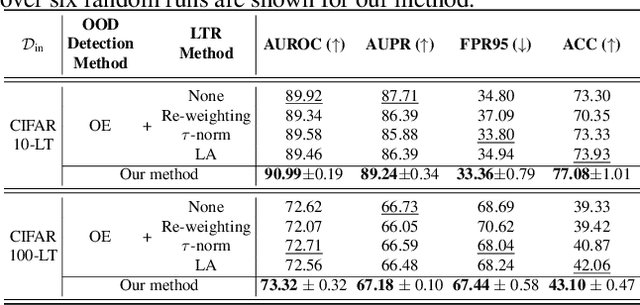

Existing out-of-distribution (OOD) detection methods are typically benchmarked on training sets with balanced class distributions. However, in real-world applications, it is common for the training sets to have long-tailed distributions. In this work, we first demonstrate that existing OOD detection methods commonly suffer from significant performance degradation when the training set is long-tail distributed. Through analysis, we posit that this is because the models struggle to distinguish the minority tail-class in-distribution samples, from the true OOD samples, making the tail classes more prone to be falsely detected as OOD. To solve this problem, we propose Partial and Asymmetric Supervised Contrastive Learning (PASCL), which explicitly encourages the model to distinguish between tail-class in-distribution samples and OOD samples. To further boost in-distribution classification accuracy, we propose Auxiliary Branch Finetuning, which uses two separate branches of BN and classification layers for anomaly detection and in-distribution classification, respectively. The intuition is that in-distribution and OOD anomaly data have different underlying distributions. Our method outperforms previous state-of-the-art method by $1.29\%$, $1.45\%$, $0.69\%$ anomaly detection false positive rate (FPR) and $3.24\%$, $4.06\%$, $7.89\%$ in-distribution classification accuracy on CIFAR10-LT, CIFAR100-LT, and ImageNet-LT, respectively. Code and pre-trained models are available at https://github.com/amazon-research/long-tailed-ood-detection.