 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergentTTS-Eval: Evaluating TTS Models on Complex Prosodic, Expressiveness, and Linguistic Challenges Using Model-as-a-Judge
May 29, 2025Text-to-Speech (TTS) benchmarks often fail to capture how well models handle nuanced and semantically complex text. Building on $\textit{EmergentTTS}$, we introduce $\textit{EmergentTTS-Eval}$, a comprehensive benchmark covering six challenging TTS scenarios: emotions, paralinguistics, foreign words, syntactic complexity, complex pronunciation (e.g. URLs, formulas), and questions. Crucially, our framework automates both test-case generation and evaluation, making the benchmark easily extensible. Starting from a small set of human-written seed prompts, we iteratively extend them using LLMs to target specific structural, phonetic and prosodic challenges, resulting in 1,645 diverse test cases. Moreover, we employ a model-as-a-judge approach, using a Large Audio Language Model (LALM) to assess the speech across multiple dimensions such as expressed emotion, prosodic, intonational, and pronunciation accuracy. We evaluate state-of-the-art open-source and proprietary TTS systems, such as 11Labs, Deepgram, and OpenAI's 4o-mini-TTS, on EmergentTTS-Eval, demonstrating its ability to reveal fine-grained performance differences. Results show that the model-as-a-judge approach offers robust TTS assessment and a high correlation with human preferences. We open source the evaluation $\href{https://github.com/boson-ai/EmergentTTS-Eval-public}{code}$ and the $\href{https://huggingface.co/datasets/bosonai/EmergentTTS-Eval}{dataset}$.
DeepCuts: Single-Shot Interpretability based Pruning for BERT
Dec 27, 2022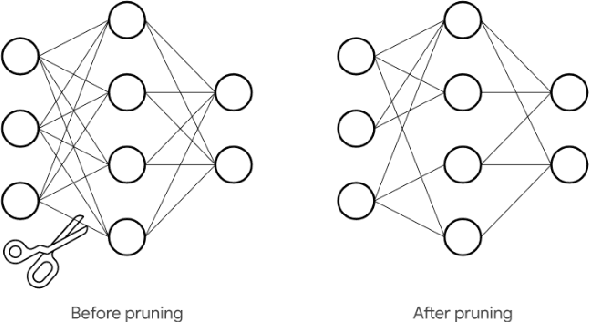
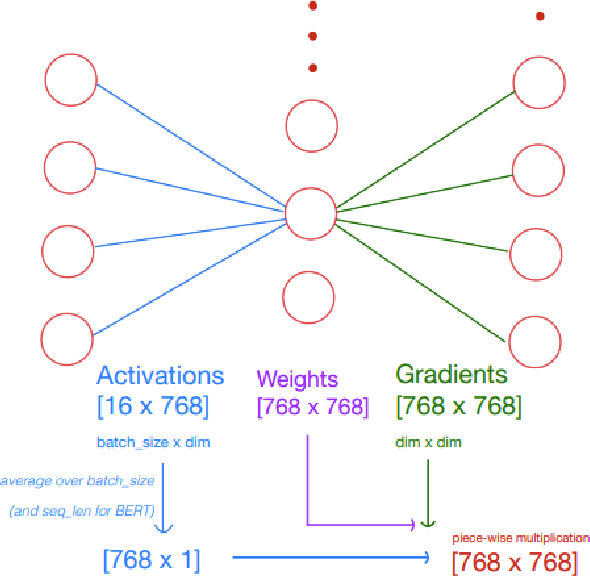
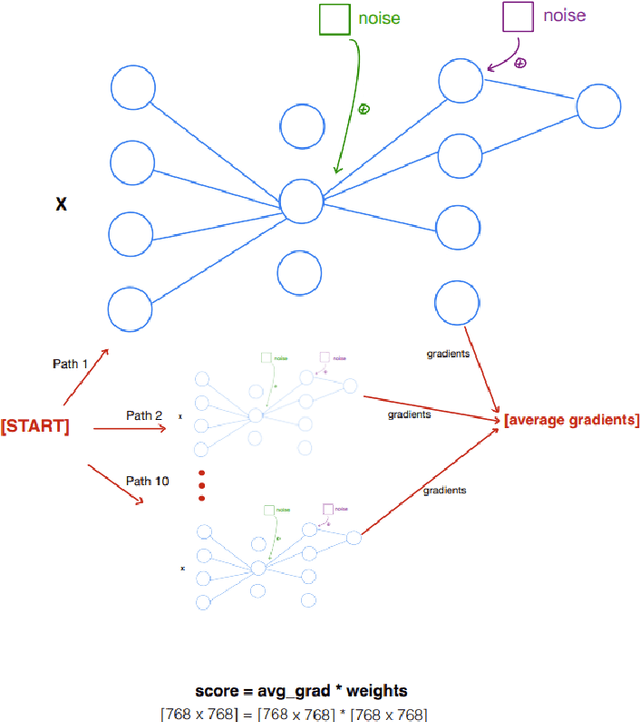
As language models have grown in parameters and layers, it has become much harder to train and infer with them on single GPUs. This is severely restricting the availability of large language models such as GPT-3, BERT-Large, and many others. A common technique to solve this problem is pruning the network architecture by removing transformer heads, fully-connected weights, and other modules. The main challenge is to discern the important parameters from the less important ones. Our goal is to find strong metrics for identifying such parameters. We thus propose two strategies: Cam-Cut based on the GradCAM interpretations, and Smooth-Cut based on the SmoothGrad, for calculating the importance scores. Through this work, we show that our scoring functions are able to assign more relevant task-based scores to the network parameters, and thus both our pruning approaches significantly outperform the standard weight and gradient-based strategies, especially at higher compression ratios in BERT-based models. We also analyze our pruning masks and find them to be significantly different from the ones obtained using standard metrics.
Local and Global Context-Based Pairwise Models for Sentence Ordering
Oct 08, 2021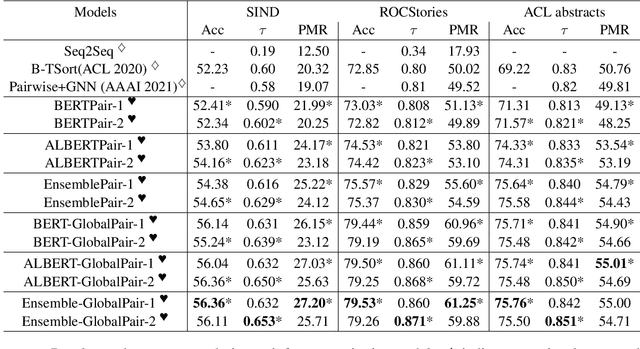
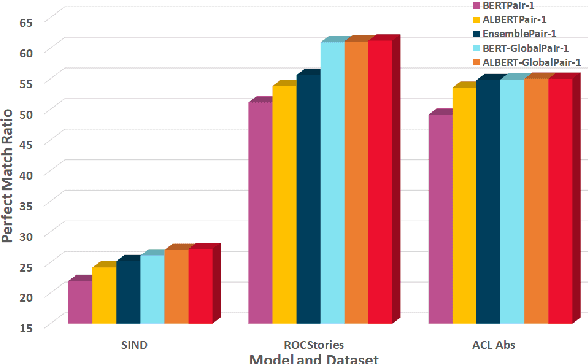
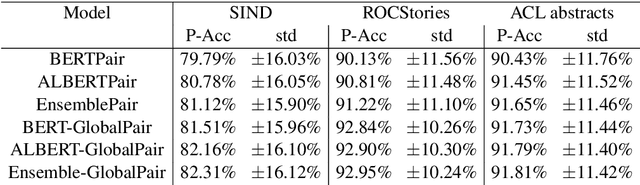
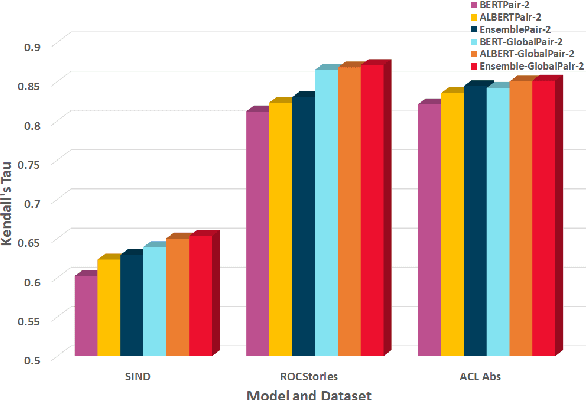
Sentence Ordering refers to the task of rearranging a set of sentences into the appropriate coherent order. For this task, most previous approaches have explored global context-based end-to-end methods using Sequence Generation techniques. In this paper, we put forward a set of robust local and global context-based pairwise ordering strategies, leveraging which our prediction strategies outperform all previous works in this domain. Our proposed encoding method utilizes the paragraph's rich global contextual information to predict the pairwise order using novel transformer architectures. Analysis of the two proposed decoding strategies helps better explain error propagation in pairwise models. This approach is the most accurate pure pairwise model and our encoding strategy also significantly improves the performance of other recent approaches that use pairwise models, including the previous state-of-the-art, demonstrating the research novelty and generalizability of this work. Additionally, we show how the pre-training task for ALBERT helps it to significantly outperform BERT, despite having considerably lesser parameters. The extensive experimental results, architectural analysis and ablation studies demonstrate the effectiveness and superiority of the proposed models compared to the previous state-of-the-art, besides providing a much better understanding of the functioning of pairwise models.
Malaria Detection and Classificaiton
Nov 29, 2020Malaria is a disease of global concern according to the World Health Organization. Billions of people in the world are at risk of Malaria today. Microscopy is considered the gold standard for Malaria diagnosis. Microscopic assessment of blood samples requires the need of trained professionals who at times are not available in rural areas where Malaria is a problem. Full automation of Malaria diagnosis is a challenging task. In this work, we put forward a framework for diagnosis of malaria. We adopt a two layer approach, where we detect infected cells using a Faster-RCNN in the first layer, crop them out, and feed the cropped cells to a seperate neural network for classification. The proposed methodology was tested on an openly available dataset, this will serve as a baseline for the future methods as currently there is no common dataset on which results are reported for Malaria Diagnosis.