 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCuts: Single-Shot Interpretability based Pruning for BERT
Paper and Code
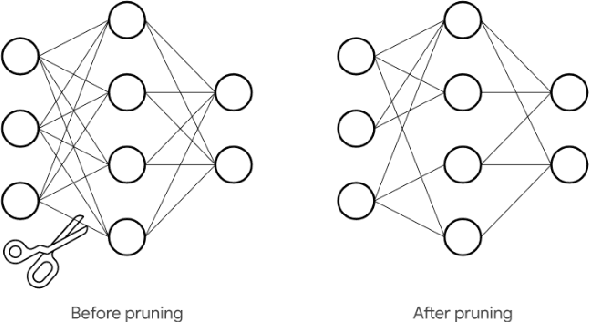
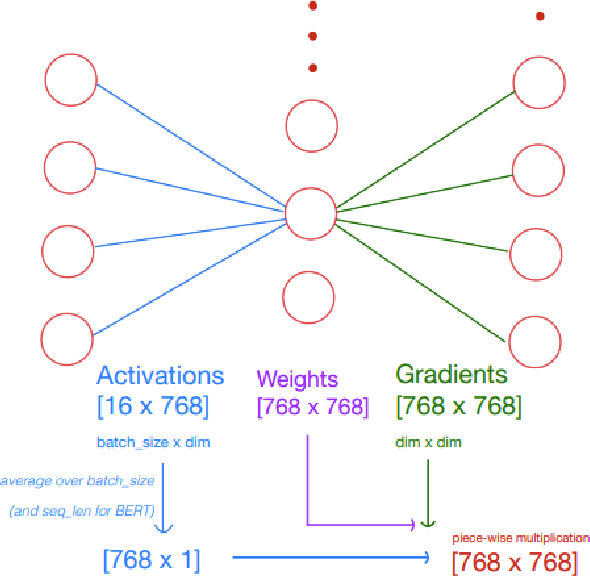
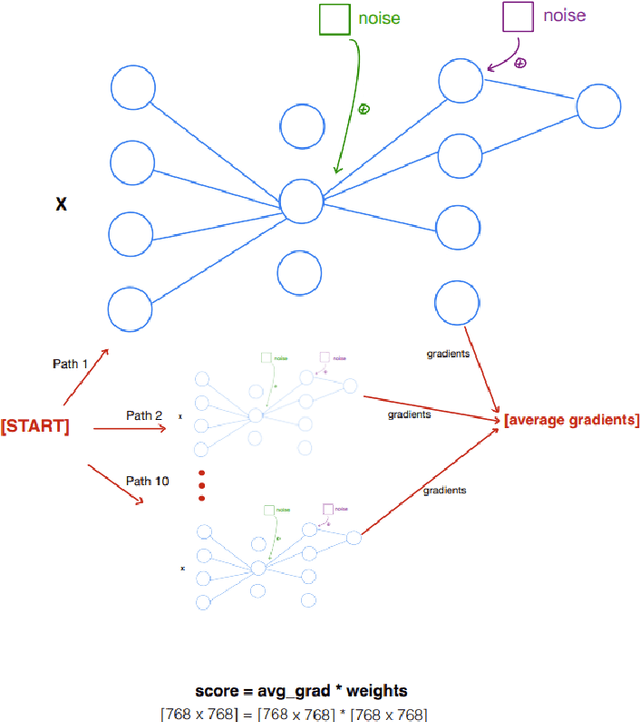
As language models have grown in parameters and layers, it has become much harder to train and infer with them on single GPUs. This is severely restricting the availability of large language models such as GPT-3, BERT-Large, and many others. A common technique to solve this problem is pruning the network architecture by removing transformer heads, fully-connected weights, and other modules. The main challenge is to discern the important parameters from the less important ones. Our goal is to find strong metrics for identifying such parameters. We thus propose two strategies: Cam-Cut based on the GradCAM interpretations, and Smooth-Cut based on the SmoothGrad, for calculating the importance scores. Through this work, we show that our scoring functions are able to assign more relevant task-based scores to the network parameters, and thus both our pruning approaches significantly outperform the standard weight and gradient-based strategies, especially at higher compression ratios in BERT-based models. We also analyze our pruning masks and find them to be significantly different from the ones obtained using standard metrics.