 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-Scores for (In)Correctness Assessment of Generative Model Outputs
Oct 29, 2025While generative models, especially large language models (LLMs), are ubiquitous in today's world, principled mechanisms to assess their (in)correctness are limited. Using the conformal prediction framework, previous works construct sets of LLM responses where the probability of including an incorrect response, or error, is capped at a desired user-defined tolerance level. However, since these methods are based on p-values, they are susceptible to p-hacking, i.e., choosing the tolerance level post-hoc can invalidate the guarantees. We therefore leverage e-values to complement generative model outputs with e-scores as a measure of incorrectness. In addition to achieving the same statistical guarantees as before, e-scores provide users flexibility in adaptively choosing tolerance levels after observing the e-scores themselves, by upper bounding a post-hoc notion of error called size distortion. We experimentally demonstrate their efficacy in assessing LLM outputs for different correctness types: mathematical factuality and property constraints satisfaction.
L3Ms -- Lagrange Large Language Models
Oct 28, 2024



Supervised fine-tuning (SFT) and alignment of large language models (LLMs) are key steps in providing a good user experience. However, the concept of an appropriate alignment is inherently application-dependent, and current methods often rely on heuristic choices to drive the optimization. In this work, we formulate SFT and alignment as a constrained optimization problem, where the LLM is trained on a task while being required to meet application-specific requirements, without resorting to heuristics. To solve this, we propose Lagrange Large Language Models (L3Ms), which employ logarithmic barriers to enforce the constraints. This approach allows for the customization of L3Ms across diverse applications while avoiding heuristic-driven processes. We demonstrate experimentally the versatility and efficacy of L3Ms in achieving tailored alignments for various applications.
On the Expected Size of Conformal Prediction Sets
Jun 12, 2023
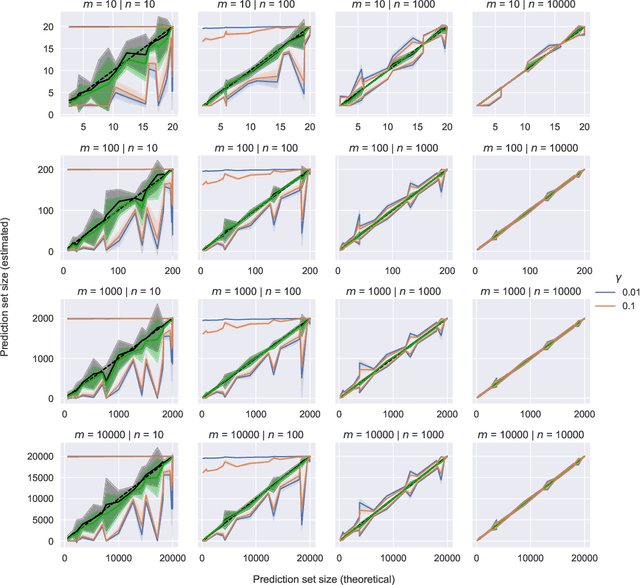
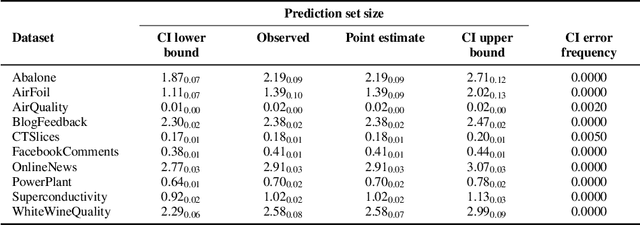
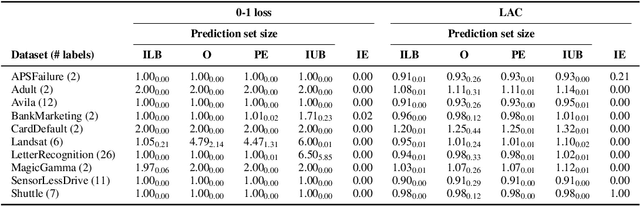
While conformal predictors reap the benefits of rigorous statistical guarantees for their error frequency, the size of their corresponding prediction sets is critical to their practical utility. Unfortunately, there is currently a lack of finite-sample analysis and guarantees for their prediction set sizes. To address this shortfall, we theoretically quantify the expected size of the prediction set under the split conformal prediction framework. As this precise formulation cannot usually be calculated directly, we further derive point estimates and high probability intervals that can be easily computed, providing a practical method for characterizing the expected prediction set size across different possible realizations of the test and calibration data. Additionally, we corroborate the efficacy of our results with experiments on real-world datasets, for both regression and classification problems.
Uniform Sampling over Episode Difficulty
Aug 03, 2021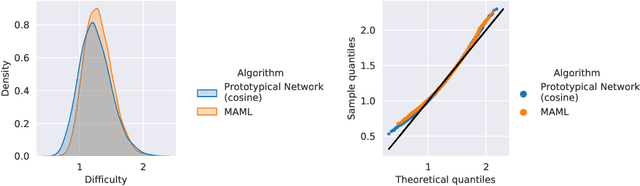
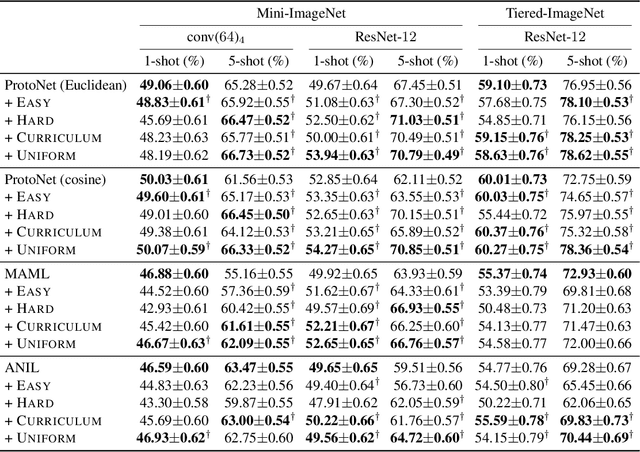
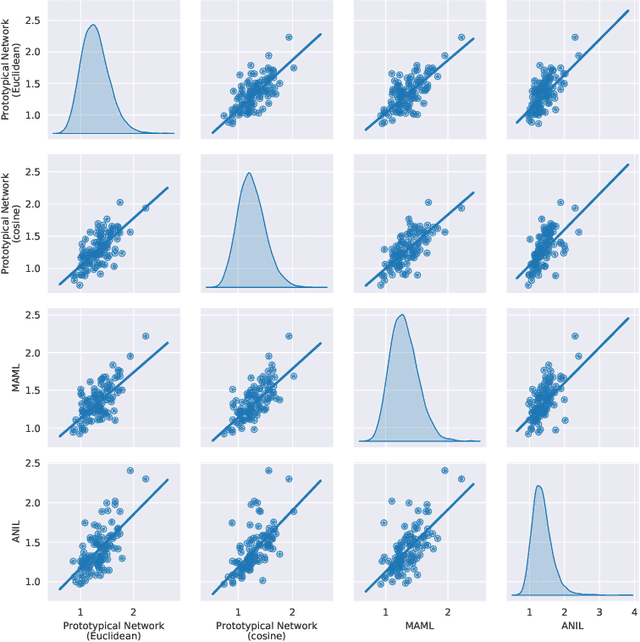
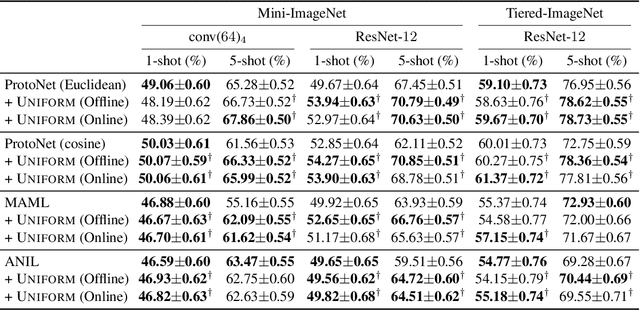
Episodic training is a core ingredient of few-shot learning to train models on tasks with limited labelled data. Despite its success, episodic training remains largely understudied, prompting us to ask the question: what is the best way to sample episodes? In this paper, we first propose a method to approximate episode sampling distributions based on their difficulty. Building on this method, we perform an extensive analysis and find that sampling uniformly over episode difficulty outperforms other sampling schemes, including curriculum and easy-/hard-mining. As the proposed sampling method is algorithm agnostic, we can leverage these insights to improve few-shot learning accuracies across many episodic training algorithms. We demonstrate the efficacy of our method across popular few-shot learning datasets, algorithms, network architectures, and protocols.
Erratum Concerning the Obfuscated Gradients Attack on Stochastic Activation Pruning
Sep 30, 2020Stochastic Activation Pruning (SAP) (Dhillon et al., 2018) is a defense to adversarial examples that was attacked and found to be broken by the "Obfuscated Gradients" paper (Athalye et al., 2018). We discover a flaw in the re-implementation that artificially weakens SAP. When SAP is applied properly, the proposed attack is not effective. However, we show that a new use of the BPDA attack technique can still reduce the accuracy of SAP to 0.1%.
A Baseline for Few-Shot Image Classification
Sep 06, 2019
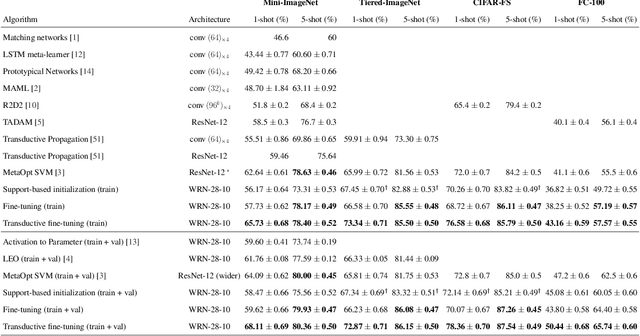

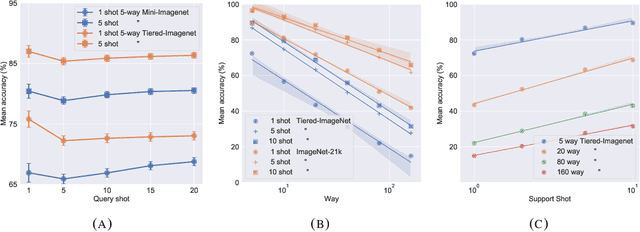
Fine-tuning a deep network trained with the standard cross-entropy loss is a strong baseline for few-shot learning. When fine-tuned transductively, this outperforms the current state-of-the-art on standard datasets such as Mini-Imagenet, Tiered-Imagenet, CIFAR-FS and FC-100 with the same hyper-parameters. The simplicity of this approach enables us to demonstrate the first few-shot learning results on the Imagenet-21k dataset. We find that using a large number of meta-training classes results in high few-shot accuracies even for a large number of test classes. We do not advocate our approach as the solution for few-shot learning, but simply use the results to highlight limitations of current benchmarks and few-shot protocols. We perform extensive studies on benchmark datasets to propose a metric that quantifies the "hardness" of a test episode. This metric can be used to report the performance of few-shot algorithms in a more systematic way.
Stochastic Activation Pruning for Robust Adversarial Defense
Mar 05, 2018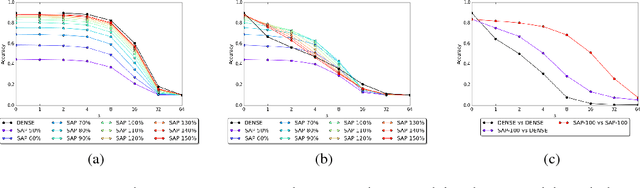
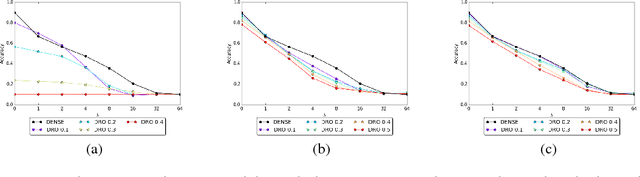
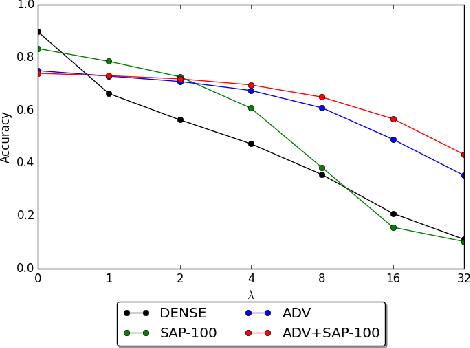
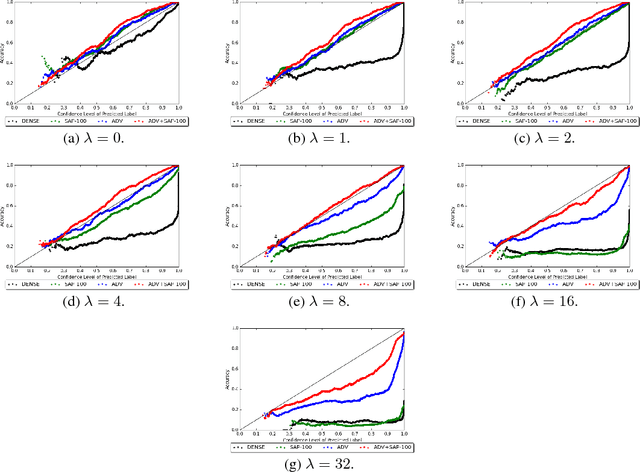
Neural networks are known to be vulnerable to adversarial examples. Carefully chosen perturbations to real images, while imperceptible to humans, induce misclassification and threaten the reliability of deep learning systems in the wild. To guard against adversarial examples, we take inspiration from game theory and cast the problem as a minimax zero-sum game between the adversary and the model. In general, for such games, the optimal strategy for both players requires a stochastic policy, also known as a mixed strategy. In this light, we propose Stochastic Activation Pruning (SAP), a mixed strategy for adversarial defense. SAP prunes a random subset of activations (preferentially pruning those with smaller magnitude) and scales up the survivors to compensate. We can apply SAP to pretrained networks, including adversarially trained models, without fine-tuning, providing robustness against adversarial examples. Experiments demonstrate that SAP confers robustness against attacks, increasing accuracy and preserving calibration.