 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Robust Watermark Injection with a Single OoD Image
Sep 04, 2023



Training a high-performance deep neural network requires large amounts of data and computational resources. Protecting the intellectual property (IP) and commercial ownership of a deep model is challenging yet increasingly crucial. A major stream of watermarking strategies implants verifiable backdoor triggers by poisoning training samples, but these are often unrealistic due to data privacy and safety concerns and are vulnerable to minor model changes such as fine-tuning. To overcome these challenges, we propose a safe and robust backdoor-based watermark injection technique that leverages the diverse knowledge from a single out-of-distribution (OoD) image, which serves as a secret key for IP verification. The independence of training data makes it agnostic to third-party promises of IP security. We induce robustness via random perturbation of model parameters during watermark injection to defend against common watermark removal attacks, including fine-tuning, pruning, and model extraction. Our experimental results demonstrate that the proposed watermarking approach is not only time- and sample-efficient without training data, but also robust against the watermark removal attacks above.
Graph Mixture of Experts: Learning on Large-Scale Graphs with Explicit Diversity Modeling
Apr 06, 2023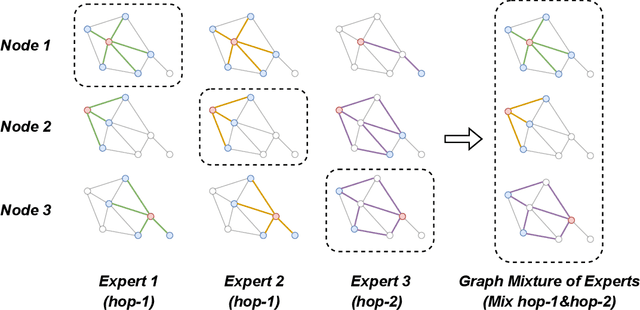

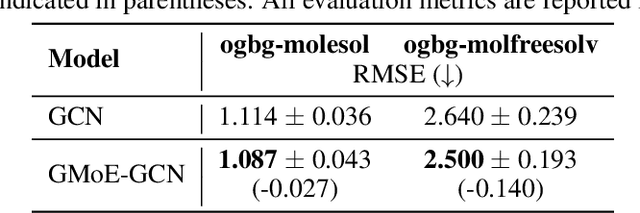
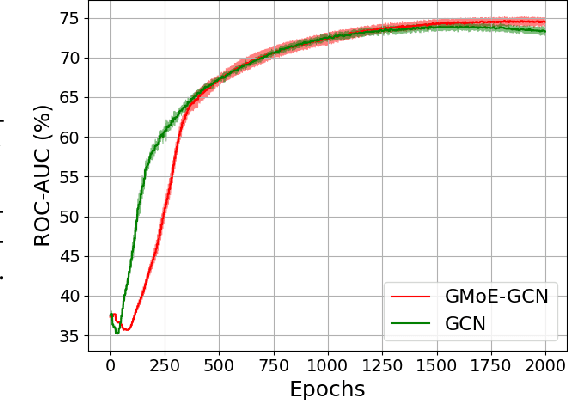
Graph neural networks (GNNs) have been widely applied to learning over graph data. Yet, real-world graphs commonly exhibit diverse graph structures and contain heterogeneous nodes and edges. Moreover, to enhance the generalization ability of GNNs, it has become common practice to further increase the diversity of training graph structures by incorporating graph augmentations and/or performing large-scale pre-training on more graphs. Therefore, it becomes essential for a GNN to simultaneously model diverse graph structures. Yet, naively increasing the GNN model capacity will suffer from both higher inference costs and the notorious trainability issue of GNNs. This paper introduces the Mixture-of-Expert (MoE) idea to GNNs, aiming to enhance their ability to accommodate the diversity of training graph structures, without incurring computational overheads. Our new Graph Mixture of Expert (GMoE) model enables each node in the graph to dynamically select its own optimal \textit{information aggregation experts}. These experts are trained to model different subgroups of graph structures in the training set. Additionally, GMoE includes information aggregation experts with varying aggregation hop sizes, where the experts with larger hop sizes are specialized in capturing information over longer ranges. The effectiveness of GMoE is verified through experimental results on a large variety of graph, node, and link prediction tasks in the OGB benchmark. For instance, it enhances ROC-AUC by $1.81\%$ in ogbg-molhiv and by $1.40\%$ in ogbg-molbbbp, as compared to the non-MoE baselines. Our code is available at https://github.com/VITA-Group/Graph-Mixture-of-Experts.
Trap and Replace: Defending Backdoor Attacks by Trapping Them into an Easy-to-Replace Subnetwork
Oct 12, 2022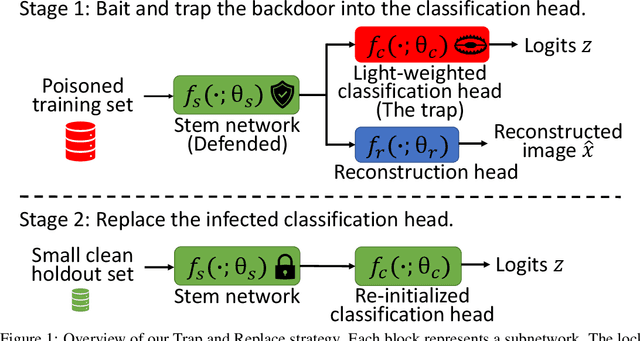

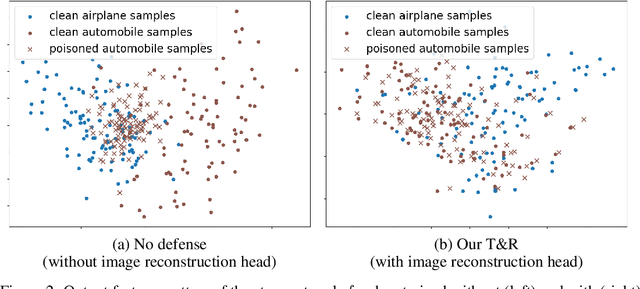
Deep neural networks (DNNs) are vulnerable to backdoor attacks. Previous works have shown it extremely challenging to unlearn the undesired backdoor behavior from the network, since the entire network can be affected by the backdoor samples. In this paper, we propose a brand-new backdoor defense strategy, which makes it much easier to remove the harmful influence of backdoor samples from the model. Our defense strategy, \emph{Trap and Replace}, consists of two stages. In the first stage, we bait and trap the backdoors in a small and easy-to-replace subnetwork. Specifically, we add an auxiliary image reconstruction head on top of the stem network shared with a light-weighted classification head. The intuition is that the auxiliary image reconstruction task encourages the stem network to keep sufficient low-level visual features that are hard to learn but semantically correct, instead of overfitting to the easy-to-learn but semantically incorrect backdoor correlations. As a result, when trained on backdoored datasets, the backdoors are easily baited towards the unprotected classification head, since it is much more vulnerable than the shared stem, leaving the stem network hardly poisoned. In the second stage, we replace the poisoned light-weighted classification head with an untainted one, by re-training it from scratch only on a small holdout dataset with clean samples, while fixing the stem network. As a result, both the stem and the classification head in the final network are hardly affected by backdoor training samples. We evaluate our method against ten different backdoor attacks. Our method outperforms previous state-of-the-art methods by up to $20.57\%$, $9.80\%$, and $13.72\%$ attack success rate and on-average $3.14\%$, $1.80\%$, and $1.21\%$ clean classification accuracy on CIFAR10, GTSRB, and ImageNet-12, respectively. Code is available online.
How Robust is Your Fairness? Evaluating and Sustaining Fairness under Unseen Distribution Shifts
Jul 04, 2022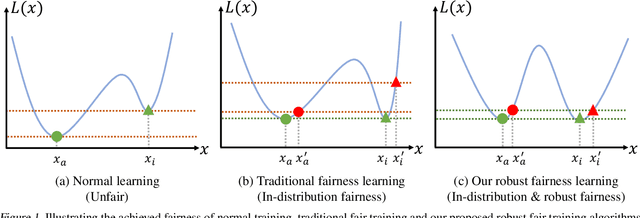
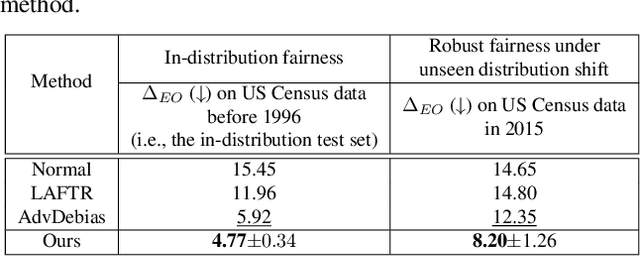

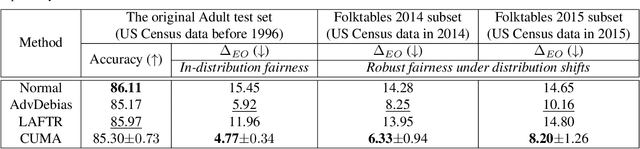
Increasing concerns have been raised on deep learning fairness in recent years. Existing fairness-aware machine learning methods mainly focus on the fairness of in-distribution data. However, in real-world applications, it is common to have distribution shift between the training and test data. In this paper, we first show that the fairness achieved by existing methods can be easily broken by slight distribution shifts. To solve this problem, we propose a novel fairness learning method termed CUrvature MAtching (CUMA), which can achieve robust fairness generalizable to unseen domains with unknown distributional shifts. Specifically, CUMA enforces the model to have similar generalization ability on the majority and minority groups, by matching the loss curvature distributions of the two groups. We evaluate our method on three popular fairness datasets. Compared with existing methods, CUMA achieves superior fairness under unseen distribution shifts, without sacrificing either the overall accuracy or the in-distribution fairness.
Partial and Asymmetric Contrastive Learning for Out-of-Distribution Detection in Long-Tailed Recognition
Jul 04, 2022

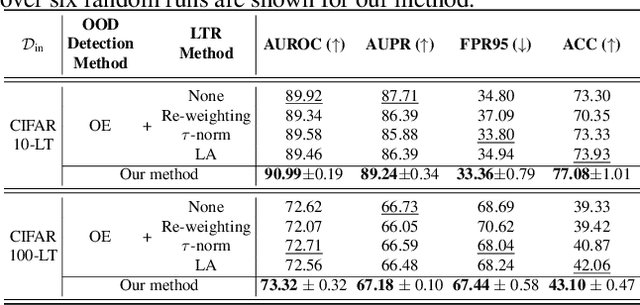

Existing out-of-distribution (OOD) detection methods are typically benchmarked on training sets with balanced class distributions. However, in real-world applications, it is common for the training sets to have long-tailed distributions. In this work, we first demonstrate that existing OOD detection methods commonly suffer from significant performance degradation when the training set is long-tail distributed. Through analysis, we posit that this is because the models struggle to distinguish the minority tail-class in-distribution samples, from the true OOD samples, making the tail classes more prone to be falsely detected as OOD. To solve this problem, we propose Partial and Asymmetric Supervised Contrastive Learning (PASCL), which explicitly encourages the model to distinguish between tail-class in-distribution samples and OOD samples. To further boost in-distribution classification accuracy, we propose Auxiliary Branch Finetuning, which uses two separate branches of BN and classification layers for anomaly detection and in-distribution classification, respectively. The intuition is that in-distribution and OOD anomaly data have different underlying distributions. Our method outperforms previous state-of-the-art method by $1.29\%$, $1.45\%$, $0.69\%$ anomaly detection false positive rate (FPR) and $3.24\%$, $4.06\%$, $7.89\%$ in-distribution classification accuracy on CIFAR10-LT, CIFAR100-LT, and ImageNet-LT, respectively. Code and pre-trained models are available at https://github.com/amazon-research/long-tailed-ood-detection.
Removing Batch Normalization Boosts Adversarial Training
Jul 04, 2022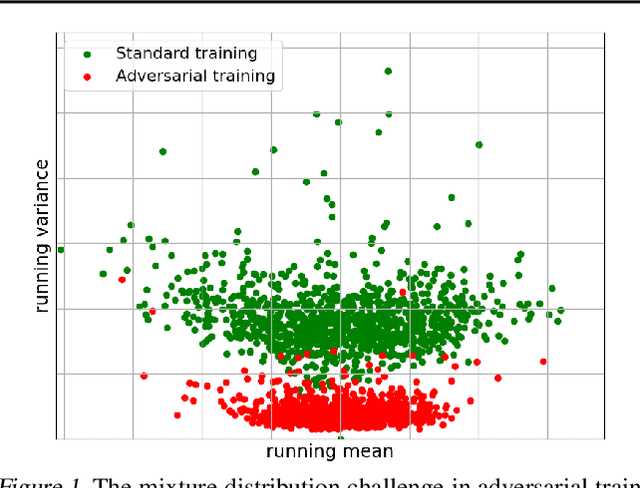
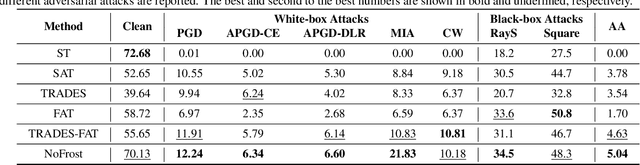
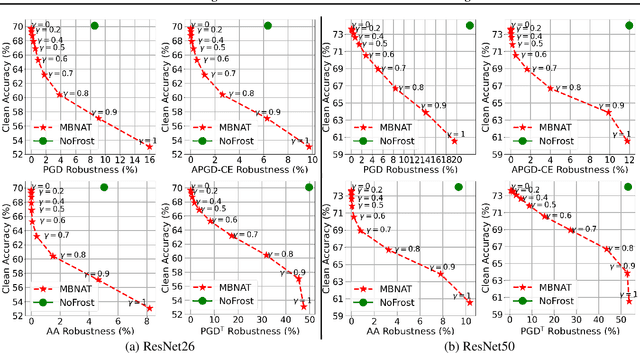
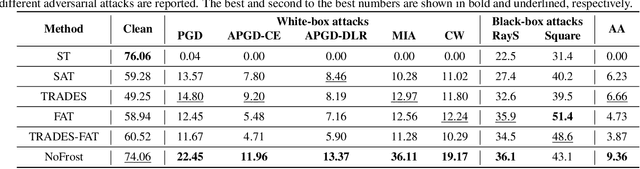
Adversarial training (AT) defends deep neural networks against adversarial attacks. One challenge that limits its practical application is the performance degradation on clean samples. A major bottleneck identified by previous works is the widely used batch normalization (BN), which struggles to model the different statistics of clean and adversarial training samples in AT. Although the dominant approach is to extend BN to capture this mixture of distribution, we propose to completely eliminate this bottleneck by removing all BN layers in AT. Our normalizer-free robust training (NoFrost) method extends recent advances in normalizer-free networks to AT for its unexplored advantage on handling the mixture distribution challenge. We show that NoFrost achieves adversarial robustness with only a minor sacrifice on clean sample accuracy. On ImageNet with ResNet50, NoFrost achieves $74.06\%$ clean accuracy, which drops merely $2.00\%$ from standard training. In contrast, BN-based AT obtains $59.28\%$ clean accuracy, suffering a significant $16.78\%$ drop from standard training. In addition, NoFrost achieves a $23.56\%$ adversarial robustness against PGD attack, which improves the $13.57\%$ robustness in BN-based AT. We observe better model smoothness and larger decision margins from NoFrost, which make the models less sensitive to input perturbations and thus more robust. Moreover, when incorporating more data augmentations into NoFrost, it achieves comprehensive robustness against multiple distribution shifts. Code and pre-trained models are public at https://github.com/amazon-research/normalizer-free-robust-training.
Efficient Split-Mix Federated Learning for On-Demand and In-Situ Customization
Mar 18, 2022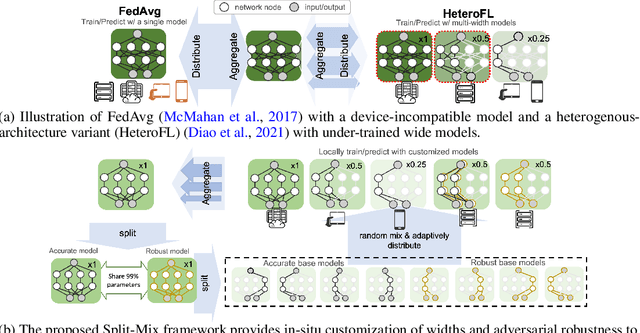
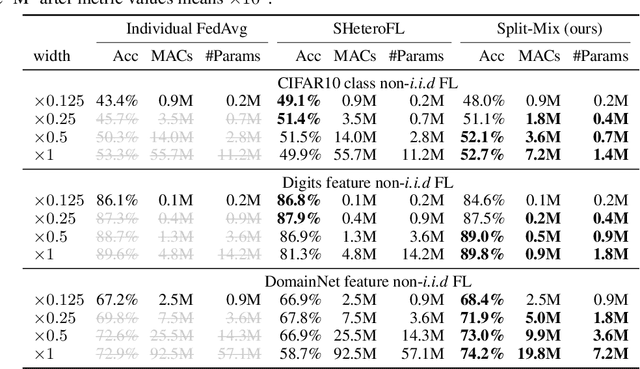
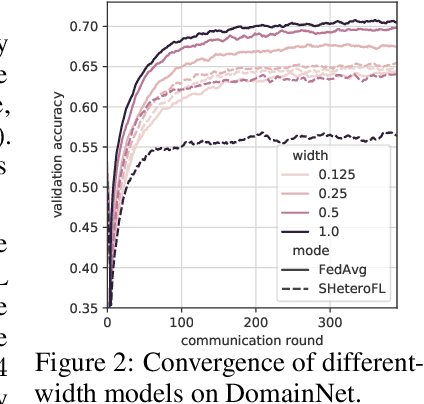
Federated learning (FL) provides a distributed learning framework for multiple participants to collaborate learning without sharing raw data. In many practical FL scenarios, participants have heterogeneous resources due to disparities in hardware and inference dynamics that require quickly loading models of different sizes and levels of robustness. The heterogeneity and dynamics together impose significant challenges to existing FL approaches and thus greatly limit FL's applicability. In this paper, we propose a novel Split-Mix FL strategy for heterogeneous participants that, once training is done, provides in-situ customization of model sizes and robustness. Specifically, we achieve customization by learning a set of base sub-networks of different sizes and robustness levels, which are later aggregated on-demand according to inference requirements. This split-mix strategy achieves customization with high efficiency in communication, storage, and inference. Extensive experiments demonstrate that our method provides better in-situ customization than the existing heterogeneous-architecture FL methods. Codes and pre-trained models are available: https://github.com/illidanlab/SplitMix.
AugMax: Adversarial Composition of Random Augmentations for Robust Training
Oct 26, 2021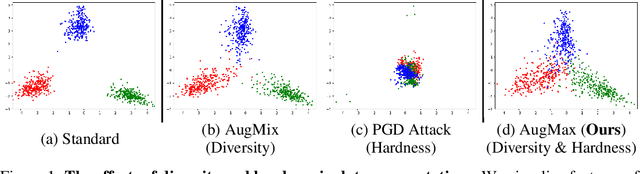
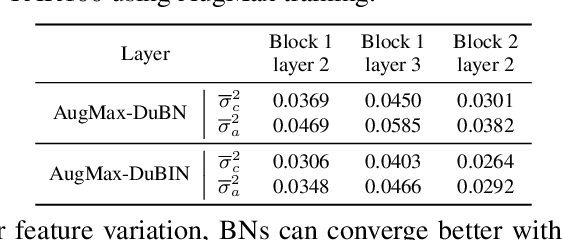
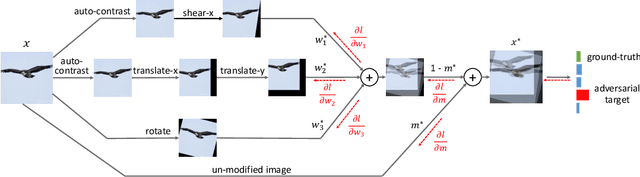
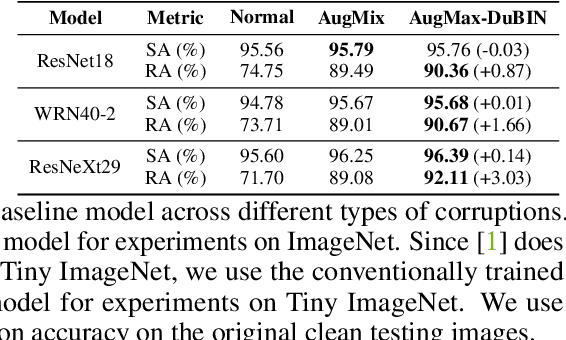
Data augmentation is a simple yet effective way to improve the robustness of deep neural networks (DNNs). Diversity and hardness are two complementary dimensions of data augmentation to achieve robustness. For example, AugMix explores random compositions of a diverse set of augmentations to enhance broader coverage, while adversarial training generates adversarially hard samples to spot the weakness. Motivated by this, we propose a data augmentation framework, termed AugMax, to unify the two aspects of diversity and hardness. AugMax first randomly samples multiple augmentation operators and then learns an adversarial mixture of the selected operators. Being a stronger form of data augmentation, AugMax leads to a significantly augmented input distribution which makes model training more challenging. To solve this problem, we further design a disentangled normalization module, termed DuBIN (Dual-Batch-and-Instance Normalization), that disentangles the instance-wise feature heterogeneity arising from AugMax. Experiments show that AugMax-DuBIN leads to significantly improved out-of-distribution robustness, outperforming prior arts by 3.03%, 3.49%, 1.82% and 0.71% on CIFAR10-C, CIFAR100-C, Tiny ImageNet-C and ImageNet-C. Codes and pretrained models are available: https://github.com/VITA-Group/AugMax.
Federated Robustness Propagation: Sharing Adversarial Robustness in Federated Learning
Jun 18, 2021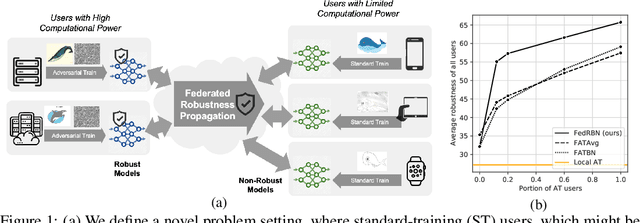
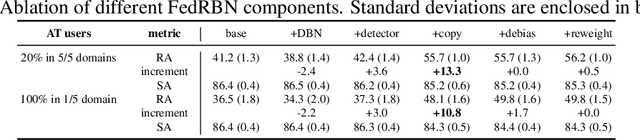
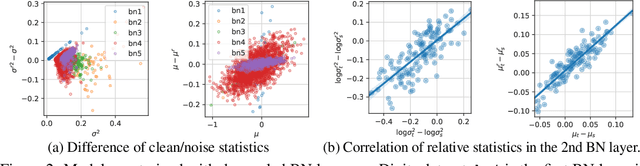
Federated learning (FL) emerges as a popular distributed learning schema that learns a model from a set of participating users without requiring raw data to be shared. One major challenge of FL comes from heterogeneity in users, which may have distributionally different (or non-iid) data and varying computation resources. Just like in centralized learning, FL users also desire model robustness against malicious attackers at test time. Whereas adversarial training (AT) provides a sound solution for centralized learning, extending its usage for FL users has imposed significant challenges, as many users may have very limited training data as well as tight computational budgets, to afford the data-hungry and costly AT. In this paper, we study a novel learning setting that propagates adversarial robustness from high-resource users that can afford AT, to those low-resource users that cannot afford it, during the FL process. We show that existing FL techniques cannot effectively propagate adversarial robustness among non-iid users, and propose a simple yet effective propagation approach that transfers robustness through carefully designed batch-normalization statistics. We demonstrate the rationality and effectiveness of our method through extensive experiments. Especially, the proposed method is shown to grant FL remarkable robustness even when only a small portion of users afford AT during learning. Codes will be published upon acceptance.
Practical Machine Learning Safety: A Survey and Primer
Jun 09, 2021
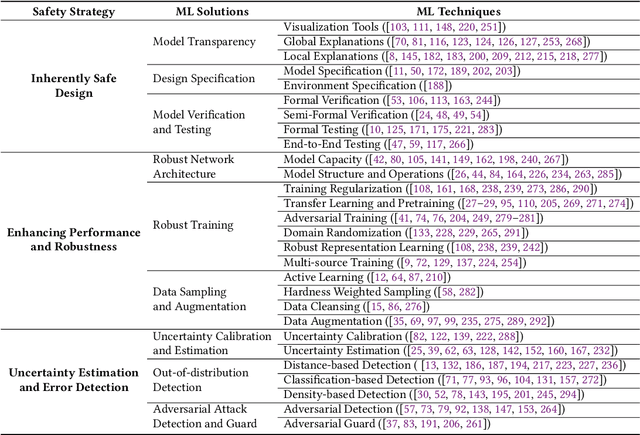

The open-world deployment of Machine Learning (ML) algorithms in safety-critical applications such as autonomous vehicles needs to address a variety of ML vulnerabilities such as interpretability, verifiability, and performance limitations. Research explores different approaches to improve ML dependability by proposing new models and training techniques to reduce generalization error, achieve domain adaptation, and detect outlier examples and adversarial attacks. In this paper, we review and organize practical ML techniques that can improve the safety and dependability of ML algorithms and therefore ML-based software. Our organization maps state-of-the-art ML techniques to safety strategies in order to enhance the dependability of the ML algorithm from different aspects, and discuss research gaps as well as promising solutions.