 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Lead Optimization via Agentic Tool Planning
May 21, 2026Drug discovery is a lengthy and resource-intensive process composed of multiple stages. Among these stages, lead optimization plays a critical role in transforming early hit compounds into viable drug candidates. This stage requires improving ADMET-related properties through subtle structural refinement while preserving key molecular substructures responsible for binding affinity to disease targets. Recent advances in artificial intelligence have shown promise in accelerating various aspects of drug discovery; however, most existing approaches to lead optimization rely on one-step molecular optimization, which fail to account for the long-term consequences of sequential design decisions. To address this limitation, we propose TRACE, a trajectory-aware, LLM-reasoning agent for molecular lead optimization that formulates tool selection as a sequential decision-making problem over action trajectories. Given a lead molecule and an optimization objective, TRACE makes trajectory-aware decisions over molecular optimization tools, enabling forward-looking refinement under structural constraints. Experiments on multiple ADMET optimization tasks show that our agent achieves higher optimization success, larger property improvements, and higher validity, while preserving molecular similarity compared to baseline models.
AttnDiff: Attention-based Differential Fingerprinting for Large Language Models
Apr 07, 2026Protecting the intellectual property of open-weight large language models (LLMs) requires verifying whether a suspect model is derived from a victim model despite common laundering operations such as fine-tuning (including PPO/DPO), pruning/compression, and model merging. We propose \textsc{AttnDiff}, a data-efficient white-box framework that extracts fingerprints from models via intrinsic information-routing behavior. \textsc{AttnDiff} probes minimally edited prompt pairs that induce controlled semantic conflicts, captures differential attention patterns, summarizes them with compact spectral descriptors, and compares models using CKA. Across Llama-2/3 and Qwen2.5 (3B--14B) and additional open-source families, it yields high similarity for related derivatives while separating unrelated model families (e.g., $>0.98$ vs.\ $<0.22$ with $M=60$ probes). With 5--60 multi-domain probes, it supports practical provenance verification and accountability.
RecThinker: An Agentic Framework for Tool-Augmented Reasoning in Recommendation
Mar 10, 2026Large Language Models (LLMs) have revolutionized recommendation agents by providing superior reasoning and flexible decision-making capabilities. However, existing methods mainly follow a passive information acquisition paradigm, where agents either rely on static pre-defined workflows or perform reasoning with constrained information. It limits the agent's ability to identify information sufficiency, often leading to suboptimal recommendations when faced with fragmented user profiles or sparse item metadata. To address these limitations, we propose RecThinker, an agentic framework for tool-augmented reasoning in recommendation, which shifts recommendation from passive processing to autonomous investigation by dynamically planning reasoning paths and proactively acquiring essential information via autonomous tool-use. Specifically, RecThinker adopts an Analyze-Plan-Act paradigm, which first analyzes the sufficiency of user-item information and autonomously invokes tool-calling sequences to bridge information gaps between available knowledge and reasoning requirements. We develop a suite of specialized tools for RecThinker, enabling the model to acquire user-side, item-side, and collaborative information for better reasoning and user-item matching. Furthermore, we introduce a self-augmented training pipeline, comprising a Supervised Fine-Tuning (SFT) stage to internalize high-quality reasoning trajectories and a Reinforcement Learning (RL) stage to optimize for decision accuracy and tool-use efficiency. Extensive experiments on multiple benchmark datasets demonstrate that RecThinker consistently outperforms strong baselines in the recommendation scenario.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
RIS-Aided Wireless Amodal Sensing for Single-View 3D Reconstruction
Feb 02, 2026Amodal sensing is critical for various real-world sensing applications because it can recover the complete shapes of partially occluded objects in complex environments. Among various amodal sensing paradigms, wireless amodal sensing is a potential solution due to its advantages of environmental robustness, privacy preservation, and low cost. However, the sensing data obtained by wireless system is sparse for shape reconstruction because of the low spatial resolution, and this issue is further intensified in complex environments with occlusion. To address this issue, we propose a Reconfigurable Intelligent Surface (RIS)-aided wireless amodal sensing scheme that leverages a large-scale RIS to enhance the spatial resolution and create reflection paths that can bypass the obstacles. A generative learning model is also employed to reconstruct the complete shape based on the sensing data captured from the viewpoint of the RIS. In such a system, it is challenging to optimize the RIS phase shifts because the relationship between RIS phase shifts and amodal sensing accuracy is complex and the closed-form expression is unknown. To tackle this challenge, we develop an error prediction model that learns the mapping from RIS phase shifts to amodal sensing accuracy, and optimizes RIS phase shifts based on this mapping. Experimental results on the benchmark dataset show that our method achieves at least a 56.73% reduction in reconstruction error compared to conventional schemes under the same number of RIS configurations.
ForgetMark: Stealthy Fingerprint Embedding via Targeted Unlearning in Language Models
Jan 13, 2026Existing invasive (backdoor) fingerprints suffer from high-perplexity triggers that are easily filtered, fixed response patterns exposed by heuristic detectors, and spurious activations on benign inputs. We introduce \textsc{ForgetMark}, a stealthy fingerprinting framework that encodes provenance via targeted unlearning. It builds a compact, human-readable key--value set with an assistant model and predictive-entropy ranking, then trains lightweight LoRA adapters to suppress the original values on their keys while preserving general capabilities. Ownership is verified under black/gray-box access by aggregating likelihood and semantic evidence into a fingerprint success rate. By relying on probabilistic forgetting traces rather than fixed trigger--response patterns, \textsc{ForgetMark} avoids high-perplexity triggers, reduces detectability, and lowers false triggers. Across diverse architectures and settings, it achieves 100\% ownership verification on fingerprinted models while maintaining standard performance, surpasses backdoor baselines in stealthiness and robustness to model merging, and remains effective under moderate incremental fine-tuning. Our code and data are available at \href{https://github.com/Xuzhenhua55/ForgetMark}{https://github.com/Xuzhenhua55/ForgetMark}.
Chain-of-Generation: Progressive Latent Diffusion for Text-Guided Molecular Design
Nov 14, 2025


Text-conditioned molecular generation aims to translate natural-language descriptions into chemical structures, enabling scientists to specify functional groups, scaffolds, and physicochemical constraints without handcrafted rules. Diffusion-based models, particularly latent diffusion models (LDMs), have recently shown promise by performing stochastic search in a continuous latent space that compactly captures molecular semantics. Yet existing methods rely on one-shot conditioning, where the entire prompt is encoded once and applied throughout diffusion, making it hard to satisfy all the requirements in the prompt. We discuss three outstanding challenges of one-shot conditioning generation, including the poor interpretability of the generated components, the failure to generate all substructures, and the overambition in considering all requirements simultaneously. We then propose three principles to address those challenges, motivated by which we propose Chain-of-Generation (CoG), a training-free multi-stage latent diffusion framework. CoG decomposes each prompt into curriculum-ordered semantic segments and progressively incorporates them as intermediate goals, guiding the denoising trajectory toward molecules that satisfy increasingly rich linguistic constraints. To reinforce semantic guidance, we further introduce a post-alignment learning phase that strengthens the correspondence between textual and molecular latent spaces. Extensive experiments on benchmark and real-world tasks demonstrate that CoG yields higher semantic alignment, diversity, and controllability than one-shot baselines, producing molecules that more faithfully reflect complex, compositional prompts while offering transparent insight into the generation process.
The FM Agent
Oct 30, 2025Large language models (LLMs) are catalyzing the development of autonomous AI research agents for scientific and engineering discovery. We present FM Agent, a novel and general-purpose multi-agent framework that leverages a synergistic combination of LLM-based reasoning and large-scale evolutionary search to address complex real-world challenges. The core of FM Agent integrates several key innovations: 1) a cold-start initialization phase incorporating expert guidance, 2) a novel evolutionary sampling strategy for iterative optimization, 3) domain-specific evaluators that combine correctness, effectiveness, and LLM-supervised feedback, and 4) a distributed, asynchronous execution infrastructure built on Ray. Demonstrating broad applicability, our system has been evaluated across diverse domains, including operations research, machine learning, GPU kernel optimization, and classical mathematical problems. FM Agent reaches state-of-the-art results autonomously, without human interpretation or tuning -- 1976.3 on ALE-Bench (+5.2\%), 43.56\% on MLE-Bench (+4.0pp), up to 20x speedups on KernelBench, and establishes new state-of-the-art(SOTA) results on several classical mathematical problems. Beyond academic benchmarks, FM Agent shows considerable promise for both large-scale enterprise R\&D workflows and fundamental scientific research, where it can accelerate innovation, automate complex discovery processes, and deliver substantial engineering and scientific advances with broader societal impact.
Unraveling LoRA Interference: Orthogonal Subspaces for Robust Model Merging
May 28, 2025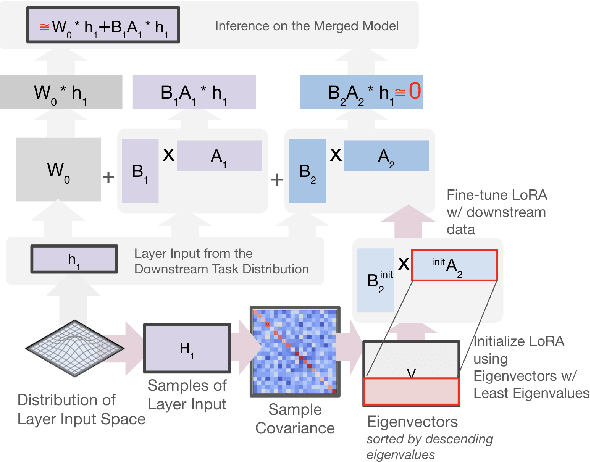
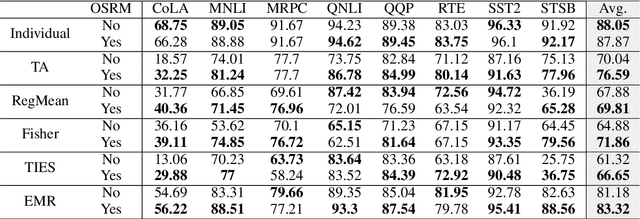
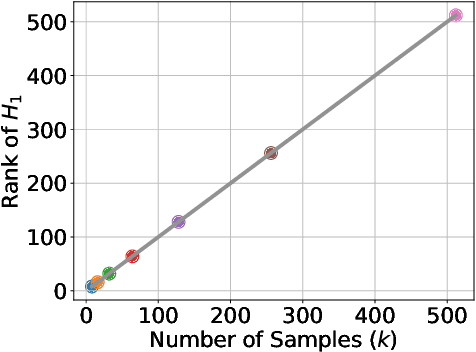
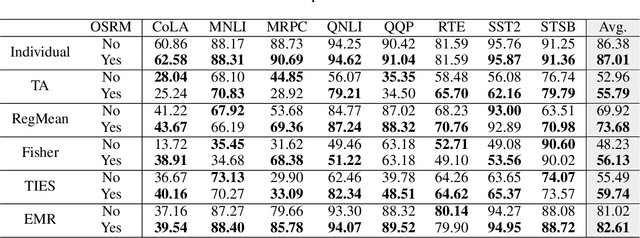
Fine-tuning large language models (LMs) for individual tasks yields strong performance but is expensive for deployment and storage. Recent works explore model merging to combine multiple task-specific models into a single multi-task model without additional training. However, existing merging methods often fail for models fine-tuned with low-rank adaptation (LoRA), due to significant performance degradation. In this paper, we show that this issue arises from a previously overlooked interplay between model parameters and data distributions. We propose Orthogonal Subspaces for Robust model Merging (OSRM) to constrain the LoRA subspace *prior* to fine-tuning, ensuring that updates relevant to one task do not adversely shift outputs for others. Our approach can seamlessly integrate with most existing merging algorithms, reducing the unintended interference among tasks. Extensive experiments on eight datasets, tested with three widely used LMs and two large LMs, demonstrate that our method not only boosts merging performance but also preserves single-task accuracy. Furthermore, our approach exhibits greater robustness to the hyperparameters of merging. These results highlight the importance of data-parameter interaction in model merging and offer a plug-and-play solution for merging LoRA models.
Towards a Statistical Understanding of Neural Networks: Beyond the Neural Tangent Kernel Theories
Dec 25, 2024A primary advantage of neural networks lies in their feature learning characteristics, which is challenging to theoretically analyze due to the complexity of their training dynamics. We propose a new paradigm for studying feature learning and the resulting benefits in generalizability. After reviewing the neural tangent kernel (NTK) theory and recent results in kernel regression, which address the generalization issue of sufficiently wide neural networks, we examine limitations and implications of the fixed kernel theory (as the NTK theory) and review recent theoretical advancements in feature learning. Moving beyond the fixed kernel/feature theory, we consider neural networks as adaptive feature models. Finally, we propose an over-parameterized Gaussian sequence model as a prototype model to study the feature learning characteristics of neural networks.