 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Mixture of Experts: Learning on Large-Scale Graphs with Explicit Diversity Modeling
Paper and Code
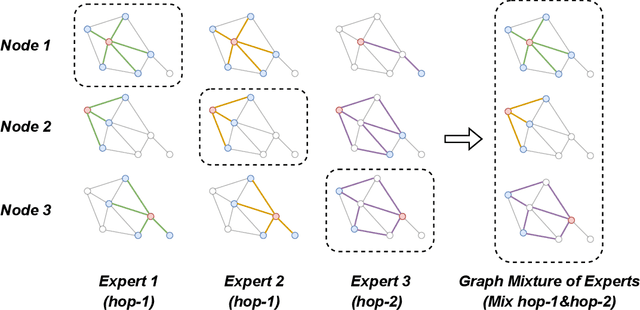

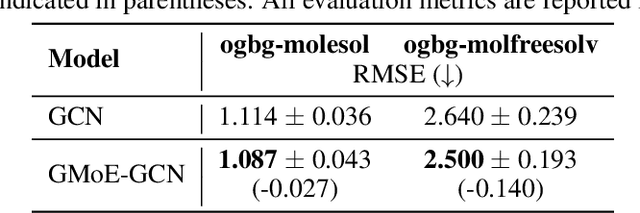
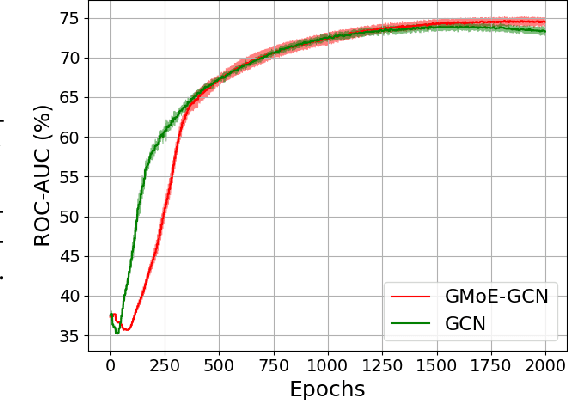
Graph neural networks (GNNs) have been widely applied to learning over graph data. Yet, real-world graphs commonly exhibit diverse graph structures and contain heterogeneous nodes and edges. Moreover, to enhance the generalization ability of GNNs, it has become common practice to further increase the diversity of training graph structures by incorporating graph augmentations and/or performing large-scale pre-training on more graphs. Therefore, it becomes essential for a GNN to simultaneously model diverse graph structures. Yet, naively increasing the GNN model capacity will suffer from both higher inference costs and the notorious trainability issue of GNNs. This paper introduces the Mixture-of-Expert (MoE) idea to GNNs, aiming to enhance their ability to accommodate the diversity of training graph structures, without incurring computational overheads. Our new Graph Mixture of Expert (GMoE) model enables each node in the graph to dynamically select its own optimal \textit{information aggregation experts}. These experts are trained to model different subgroups of graph structures in the training set. Additionally, GMoE includes information aggregation experts with varying aggregation hop sizes, where the experts with larger hop sizes are specialized in capturing information over longer ranges. The effectiveness of GMoE is verified through experimental results on a large variety of graph, node, and link prediction tasks in the OGB benchmark. For instance, it enhances ROC-AUC by $1.81\%$ in ogbg-molhiv and by $1.40\%$ in ogbg-molbbbp, as compared to the non-MoE baselines. Our code is available at https://github.com/VITA-Group/Graph-Mixture-of-Experts.