 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Human-Written Paper: Agent-Native Research Artifacts
Apr 27, 2026Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
CATNIP: LLM Unlearning via Calibrated and Tokenized Negative Preference Alignment
Feb 02, 2026Pretrained knowledge memorized in LLMs raises critical concerns over safety and privacy, which has motivated LLM Unlearning as a technique for selectively removing the influences of undesirable knowledge. Existing approaches, rooted in Gradient Ascent (GA), often degrade general domain knowledge while relying on retention data or curated contrastive pairs, which can be either impractical or data and computationally prohibitive. Negative Preference Alignment has been explored for unlearning to tackle the limitations of GA, which, however, remains confined by its choice of reference model and shows undermined performance in realistic data settings. These limitations raise two key questions: i) Can we achieve effective unlearning that quantifies model confidence in undesirable knowledge and uses it to calibrate gradient updates more precisely, thus reducing catastrophic forgetting? ii) Can we make unlearning robust to data scarcity and length variation? We answer both questions affirmatively with CATNIP (Calibrated and Tokenized Negative Preference Alignment), a principled method that rescales unlearning effects in proportion to the model's token-level confidence, thus ensuring fine-grained control over forgetting. Extensive evaluations on MUSE and WMDP benchmarks demonstrated that our work enables effective unlearning without requiring retention data or contrastive unlearning response pairs, with stronger knowledge forgetting and preservation tradeoffs than state-of-the-art methods.
LoX: Low-Rank Extrapolation Robustifies LLM Safety Against Fine-tuning
Jun 18, 2025Large Language Models (LLMs) have become indispensable in real-world applications. However, their widespread adoption raises significant safety concerns, particularly in responding to socially harmful questions. Despite substantial efforts to improve model safety through alignment, aligned models can still have their safety protections undermined by subsequent fine-tuning - even when the additional training data appears benign. In this paper, we empirically demonstrate that this vulnerability stems from the sensitivity of safety-critical low-rank subspaces in LLM parameters to fine-tuning. Building on this insight, we propose a novel training-free method, termed Low-Rank Extrapolation (LoX), to enhance safety robustness by extrapolating the safety subspace of an aligned LLM. Our experimental results confirm the effectiveness of LoX, demonstrating significant improvements in robustness against both benign and malicious fine-tuning attacks while preserving the model's adaptability to new tasks. For instance, LoX leads to 11% to 54% absolute reductions in attack success rates (ASR) facing benign or malicious fine-tuning attacks. By investigating the ASR landscape of parameters, we attribute the success of LoX to that the extrapolation moves LLM parameters to a flatter zone, thereby less sensitive to perturbations. The code is available at github.com/VITA-Group/LoX.
More is Less: The Pitfalls of Multi-Model Synthetic Preference Data in DPO Safety Alignment
Apr 03, 2025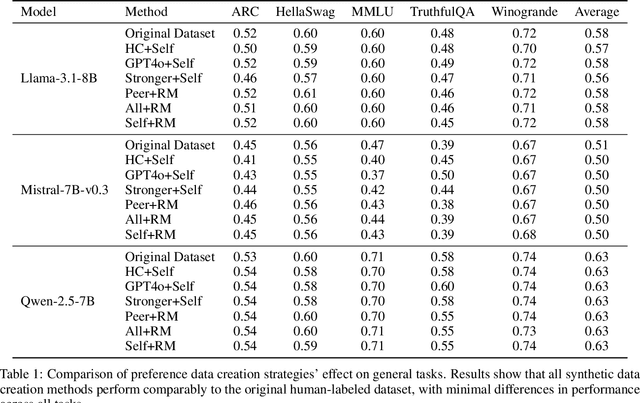
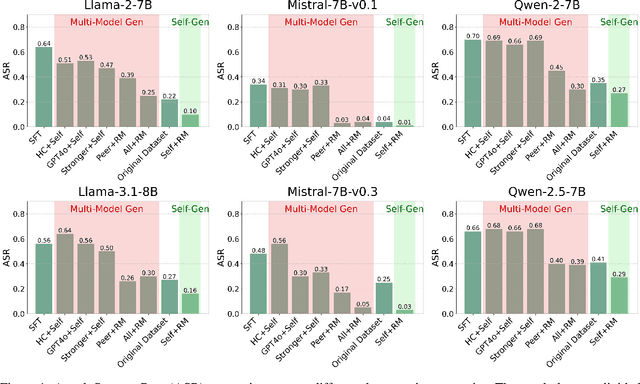
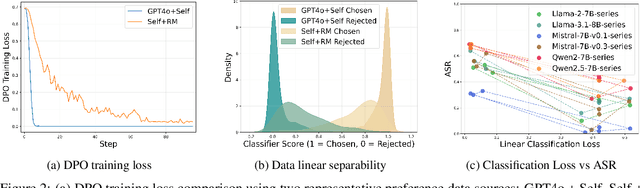

Aligning large language models (LLMs) with human values is an increasingly critical step in post-training. Direct Preference Optimization (DPO) has emerged as a simple, yet effective alternative to reinforcement learning from human feedback (RLHF). Synthetic preference data with its low cost and high quality enable effective alignment through single- or multi-model generated preference data. Our study reveals a striking, safety-specific phenomenon associated with DPO alignment: Although multi-model generated data enhances performance on general tasks (ARC, Hellaswag, MMLU, TruthfulQA, Winogrande) by providing diverse responses, it also tends to facilitate reward hacking during training. This can lead to a high attack success rate (ASR) when models encounter jailbreaking prompts. The issue is particularly pronounced when employing stronger models like GPT-4o or larger models in the same family to generate chosen responses paired with target model self-generated rejected responses, resulting in dramatically poorer safety outcomes. Furthermore, with respect to safety, using solely self-generated responses (single-model generation) for both chosen and rejected pairs significantly outperforms configurations that incorporate responses from stronger models, whether used directly as chosen data or as part of a multi-model response pool. We demonstrate that multi-model preference data exhibits high linear separability between chosen and rejected responses, which allows models to exploit superficial cues rather than internalizing robust safety constraints. Our experiments, conducted on models from the Llama, Mistral, and Qwen families, consistently validate these findings.
MedHallu: A Comprehensive Benchmark for Detecting Medical Hallucinations in Large Language Models
Feb 20, 2025



Advancements in Large Language Models (LLMs) and their increasing use in medical question-answering necessitate rigorous evaluation of their reliability. A critical challenge lies in hallucination, where models generate plausible yet factually incorrect outputs. In the medical domain, this poses serious risks to patient safety and clinical decision-making. To address this, we introduce MedHallu, the first benchmark specifically designed for medical hallucination detection. MedHallu comprises 10,000 high-quality question-answer pairs derived from PubMedQA, with hallucinated answers systematically generated through a controlled pipeline. Our experiments show that state-of-the-art LLMs, including GPT-4o, Llama-3.1, and the medically fine-tuned UltraMedical, struggle with this binary hallucination detection task, with the best model achieving an F1 score as low as 0.625 for detecting "hard" category hallucinations. Using bidirectional entailment clustering, we show that harder-to-detect hallucinations are semantically closer to ground truth. Through experiments, we also show incorporating domain-specific knowledge and introducing a "not sure" category as one of the answer categories improves the precision and F1 scores by up to 38% relative to baselines.
GuideLLM: Exploring LLM-Guided Conversation with Applications in Autobiography Interviewing
Feb 10, 2025



Although Large Language Models (LLMs) succeed in human-guided conversations such as instruction following and question answering, the potential of LLM-guided conversations-where LLMs direct the discourse and steer the conversation's objectives-remains under-explored. In this study, we first characterize LLM-guided conversation into three fundamental components: (i) Goal Navigation; (ii) Context Management; (iii) Empathetic Engagement, and propose GuideLLM as an installation. We then implement an interviewing environment for the evaluation of LLM-guided conversation. Specifically, various topics are involved in this environment for comprehensive interviewing evaluation, resulting in around 1.4k turns of utterances, 184k tokens, and over 200 events mentioned during the interviewing for each chatbot evaluation. We compare GuideLLM with 6 state-of-the-art LLMs such as GPT-4o and Llama-3-70b-Instruct, from the perspective of interviewing quality, and autobiography generation quality. For automatic evaluation, we derive user proxies from multiple autobiographies and employ LLM-as-a-judge to score LLM behaviors. We further conduct a human-involved experiment by employing 45 human participants to chat with GuideLLM and baselines. We then collect human feedback, preferences, and ratings regarding the qualities of conversation and autobiography. Experimental results indicate that GuideLLM significantly outperforms baseline LLMs in automatic evaluation and achieves consistent leading performances in human ratings.
Extracting and Understanding the Superficial Knowledge in Alignment
Feb 07, 2025



Alignment of large language models (LLMs) with human values and preferences, often achieved through fine-tuning based on human feedback, is essential for ensuring safe and responsible AI behaviors. However, the process typically requires substantial data and computation resources. Recent studies have revealed that alignment might be attainable at lower costs through simpler methods, such as in-context learning. This leads to the question: Is alignment predominantly superficial? In this paper, we delve into this question and provide a quantitative analysis. We formalize the concept of superficial knowledge, defining it as knowledge that can be acquired through easily token restyling, without affecting the model's ability to capture underlying causal relationships between tokens. We propose a method to extract and isolate superficial knowledge from aligned models, focusing on the shallow modifications to the final token selection process. By comparing models augmented only with superficial knowledge to fully aligned models, we quantify the superficial portion of alignment. Our findings reveal that while superficial knowledge constitutes a significant portion of alignment, particularly in safety and detoxification tasks, it is not the whole story. Tasks requiring reasoning and contextual understanding still rely on deeper knowledge. Additionally, we demonstrate two practical advantages of isolated superficial knowledge: (1) it can be transferred between models, enabling efficient offsite alignment of larger models using extracted superficial knowledge from smaller models, and (2) it is recoverable, allowing for the restoration of alignment in compromised models without sacrificing performance.
DeepOSets: Non-Autoregressive In-Context Learning of Supervised Learning Operators
Oct 11, 2024



We introduce DeepSets Operator Networks (DeepOSets), an efficient, non-autoregressive neural network architecture for in-context operator learning. In-context learning allows a trained machine learning model to learn from a user prompt without further training. DeepOSets adds in-context learning capabilities to Deep Operator Networks (DeepONets) by combining it with the DeepSets architecture. As the first non-autoregressive model for in-context operator learning, DeepOSets allow the user prompt to be processed in parallel, leading to significant computational savings. Here, we present the application of DeepOSets in the problem of learning supervised learning algorithms, which are operators mapping a finite-dimensional space of labeled data into an infinite-dimensional hypothesis space of prediction functions. In an empirical comparison with a popular autoregressive (transformer-based) model for in-context learning of the least-squares linear regression algorithm, DeepOSets reduced the number of model weights by several orders of magnitude and required a fraction of training and inference time. Furthermore, DeepOSets proved to be less sensitive to noise, outperforming the transformer model in noisy settings.
LLM-PBE: Assessing Data Privacy in Large Language Models
Aug 23, 2024



Large Language Models (LLMs) have become integral to numerous domains, significantly advancing applications in data management, mining, and analysis. Their profound capabilities in processing and interpreting complex language data, however, bring to light pressing concerns regarding data privacy, especially the risk of unintentional training data leakage. Despite the critical nature of this issue, there has been no existing literature to offer a comprehensive assessment of data privacy risks in LLMs. Addressing this gap, our paper introduces LLM-PBE, a toolkit crafted specifically for the systematic evaluation of data privacy risks in LLMs. LLM-PBE is designed to analyze privacy across the entire lifecycle of LLMs, incorporating diverse attack and defense strategies, and handling various data types and metrics. Through detailed experimentation with multiple LLMs, LLM-PBE facilitates an in-depth exploration of data privacy concerns, shedding light on influential factors such as model size, data characteristics, and evolving temporal dimensions. This study not only enriches the understanding of privacy issues in LLMs but also serves as a vital resource for future research in the field. Aimed at enhancing the breadth of knowledge in this area, the findings, resources, and our full technical report are made available at https://llm-pbe.github.io/, providing an open platform for academic and practical advancements in LLM privacy assessment.
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Jun 13, 2024



The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately "translate" them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.