 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGIC: Multi-Agent Argumentation and Grammar Integrated Critiquer
Jun 16, 2025Automated Essay Scoring (AES) and Automatic Essay Feedback (AEF) systems aim to reduce the workload of human raters in educational assessment. However, most existing systems prioritize numeric scoring accuracy over the quality of feedback. This paper presents Multi-Agent Argumentation and Grammar Integrated Critiquer (MAGIC), a framework that uses multiple specialized agents to evaluate distinct writing aspects to both predict holistic scores and produce detailed, rubric-aligned feedback. To support evaluation, we curated a novel dataset of past GRE practice test essays with expert-evaluated scores and feedback. MAGIC outperforms baseline models in both essay scoring , as measured by Quadratic Weighted Kappa (QWK). We find that despite the improvement in QWK, there are opportunities for future work in aligning LLM-generated feedback to human preferences.
LLM-PBE: Assessing Data Privacy in Large Language Models
Aug 23, 2024



Large Language Models (LLMs) have become integral to numerous domains, significantly advancing applications in data management, mining, and analysis. Their profound capabilities in processing and interpreting complex language data, however, bring to light pressing concerns regarding data privacy, especially the risk of unintentional training data leakage. Despite the critical nature of this issue, there has been no existing literature to offer a comprehensive assessment of data privacy risks in LLMs. Addressing this gap, our paper introduces LLM-PBE, a toolkit crafted specifically for the systematic evaluation of data privacy risks in LLMs. LLM-PBE is designed to analyze privacy across the entire lifecycle of LLMs, incorporating diverse attack and defense strategies, and handling various data types and metrics. Through detailed experimentation with multiple LLMs, LLM-PBE facilitates an in-depth exploration of data privacy concerns, shedding light on influential factors such as model size, data characteristics, and evolving temporal dimensions. This study not only enriches the understanding of privacy issues in LLMs but also serves as a vital resource for future research in the field. Aimed at enhancing the breadth of knowledge in this area, the findings, resources, and our full technical report are made available at https://llm-pbe.github.io/, providing an open platform for academic and practical advancements in LLM privacy assessment.
Standard Language Ideology in AI-Generated Language
Jun 13, 2024
In this position paper, we explore standard language ideology in language generated by large language models (LLMs). First, we outline how standard language ideology is reflected and reinforced in LLMs. We then present a taxonomy of open problems regarding standard language ideology in AI-generated language with implications for minoritized language communities. We introduce the concept of standard AI-generated language ideology, the process by which AI-generated language regards Standard American English (SAE) as a linguistic default and reinforces a linguistic bias that SAE is the most "appropriate" language. Finally, we discuss tensions that remain, including reflecting on what desirable system behavior looks like, as well as advantages and drawbacks of generative AI tools imitating--or often not--different English language varieties. Throughout, we discuss standard language ideology as a manifestation of existing global power structures in and through AI-generated language before ending with questions to move towards alternative, more emancipatory digital futures.
Linguistic Bias in ChatGPT: Language Models Reinforce Dialect Discrimination
Jun 13, 2024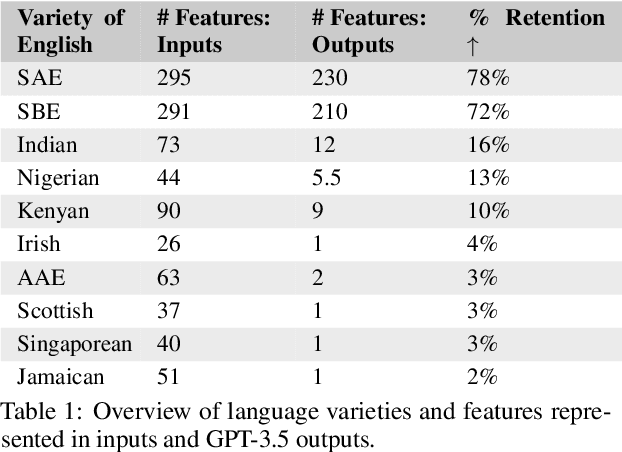
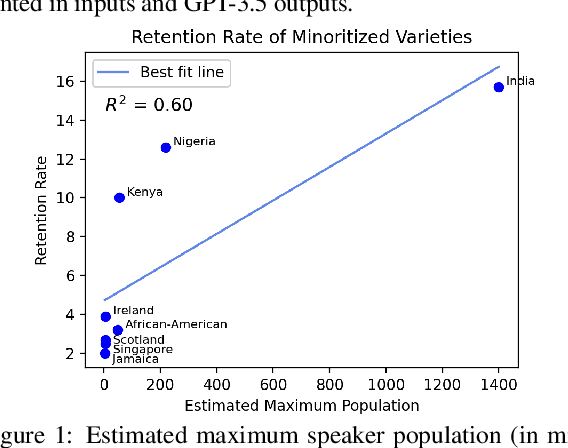
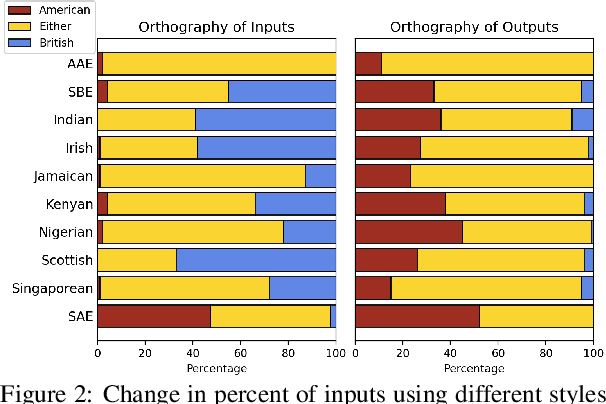
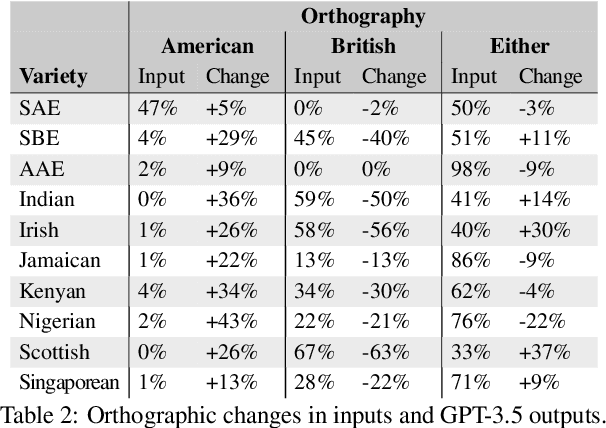
We present a large-scale study of linguistic bias exhibited by ChatGPT covering ten dialects of English (Standard American English, Standard British English, and eight widely spoken non-"standard" varieties from around the world). We prompted GPT-3.5 Turbo and GPT-4 with text by native speakers of each variety and analyzed the responses via detailed linguistic feature annotation and native speaker evaluation. We find that the models default to "standard" varieties of English; based on evaluation by native speakers, we also find that model responses to non-"standard" varieties consistently exhibit a range of issues: lack of comprehension (10% worse compared to "standard" varieties), stereotyping (16% worse), demeaning content (22% worse), and condescending responses (12% worse). We also find that if these models are asked to imitate the writing style of prompts in non-"standard" varieties, they produce text that exhibits lower comprehension of the input and is especially prone to stereotyping. GPT-4 improves on GPT-3.5 in terms of comprehension, warmth, and friendliness, but it also results in a marked increase in stereotyping (+17%). The results suggest that GPT-3.5 Turbo and GPT-4 exhibit linguistic discrimination in ways that can exacerbate harms for speakers of non-"standard" varieties.