 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeanTutor: Towards a Verified AI Mathematical Proof Tutor
Jan 24, 2026This paper considers the development of an AI-based provably-correct mathematical proof tutor. While Large Language Models (LLMs) allow seamless communication in natural language, they are error prone. Theorem provers such as Lean allow for provable-correctness, but these are hard for students to learn. We present a proof-of-concept system (LeanTutor) by combining the complementary strengths of LLMs and theorem provers. LeanTutor is composed of three modules: (i) an autoformalizer/proof-checker, (ii) a next-step generator, and (iii) a natural language feedback generator. To evaluate the system, we introduce PeanoBench, a dataset of 371 Peano Arithmetic proofs in human-written natural language and formal language, derived from the Natural Numbers Game.
Decomposing Prediction Mechanisms for In-Context Recall
Jul 02, 2025We introduce a new family of toy problems that combine features of linear-regression-style continuous in-context learning (ICL) with discrete associative recall. We pretrain transformer models on sample traces from this toy, specifically symbolically-labeled interleaved state observations from randomly drawn linear deterministic dynamical systems. We study if the transformer models can recall the state of a sequence previously seen in its context when prompted to do so with the corresponding in-context label. Taking a closer look at this task, it becomes clear that the model must perform two functions: (1) identify which system's state should be recalled and apply that system to its last seen state, and (2) continuing to apply the correct system to predict the subsequent states. Training dynamics reveal that the first capability emerges well into a model's training. Surprisingly, the second capability, of continuing the prediction of a resumed sequence, develops much earlier. Via out-of-distribution experiments, and a mechanistic analysis on model weights via edge pruning, we find that next-token prediction for this toy problem involves at least two separate mechanisms. One mechanism uses the discrete symbolic labels to do the associative recall required to predict the start of a resumption of a previously seen sequence. The second mechanism, which is largely agnostic to the discrete symbolic labels, performs a "Bayesian-style" prediction based on the previous token and the context. These two mechanisms have different learning dynamics. To confirm that this multi-mechanism (manifesting as separate phase transitions) phenomenon is not just an artifact of our toy setting, we used OLMo training checkpoints on an ICL translation task to see a similar phenomenon: a decisive gap in the emergence of first-task-token performance vs second-task-token performance.
MAGIC: Multi-Agent Argumentation and Grammar Integrated Critiquer
Jun 16, 2025Automated Essay Scoring (AES) and Automatic Essay Feedback (AEF) systems aim to reduce the workload of human raters in educational assessment. However, most existing systems prioritize numeric scoring accuracy over the quality of feedback. This paper presents Multi-Agent Argumentation and Grammar Integrated Critiquer (MAGIC), a framework that uses multiple specialized agents to evaluate distinct writing aspects to both predict holistic scores and produce detailed, rubric-aligned feedback. To support evaluation, we curated a novel dataset of past GRE practice test essays with expert-evaluated scores and feedback. MAGIC outperforms baseline models in both essay scoring , as measured by Quadratic Weighted Kappa (QWK). We find that despite the improvement in QWK, there are opportunities for future work in aligning LLM-generated feedback to human preferences.
LeanTutor: A Formally-Verified AI Tutor for Mathematical Proofs
Jun 10, 2025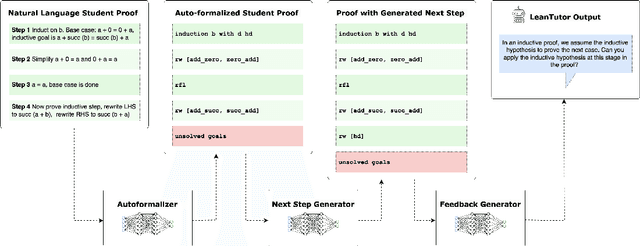

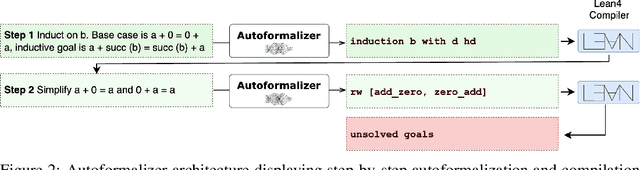
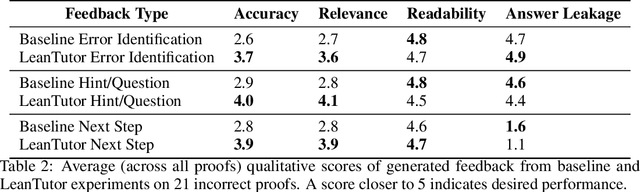
We present LeanTutor, a Large Language Model (LLM)-based tutoring system for math proofs. LeanTutor interacts with the student in natural language, formally verifies student-written math proofs in Lean, generates correct next steps, and provides the appropriate instructional guidance. LeanTutor is composed of three modules: (i) an autoformalizer/proof-checker, (ii) a next-step generator, and (iii) a natural language feedback generator. The first module faithfully autoformalizes student proofs into Lean and verifies proof accuracy via successful code compilation. If the proof has an error, the incorrect step is identified. The next-step generator module outputs a valid next Lean tactic for incorrect proofs via LLM-based candidate generation and proof search. The feedback generator module leverages Lean data to produce a pedagogically-motivated natural language hint for the student user. To evaluate our system, we introduce PeanoBench, a human-written dataset derived from the Natural Numbers Game, consisting of 371 Peano Arithmetic proofs, where each natural language proof step is paired with the corresponding logically equivalent tactic in Lean. The Autoformalizer correctly formalizes 57% of tactics in correct proofs and accurately identifies the incorrect step in 30% of incorrect proofs. In generating natural language hints for erroneous proofs, LeanTutor outperforms a simple baseline on accuracy and relevance metrics.
Verifying Controllers Against Adversarial Examples with Bayesian Optimization
Feb 26, 2018
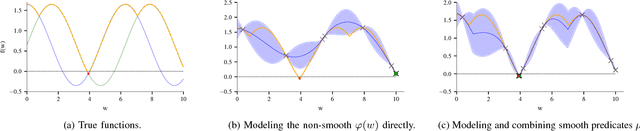
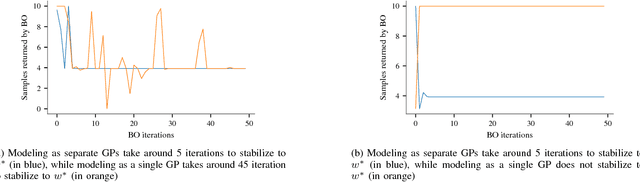
Recent successes in reinforcement learning have lead to the development of complex controllers for real-world robots. As these robots are deployed in safety-critical applications and interact with humans, it becomes critical to ensure safety in order to avoid causing harm. A first step in this direction is to test the controllers in simulation. To be able to do this, we need to capture what we mean by safety and then efficiently search the space of all behaviors to see if they are safe. In this paper, we present an active-testing framework based on Bayesian Optimization. We specify safety constraints using logic and exploit structure in the problem in order to test the system for adversarial counter examples that violate the safety specifications. These specifications are defined as complex boolean combinations of smooth functions on the trajectories and, unlike reward functions in reinforcement learning, are expressive and impose hard constraints on the system. In our framework, we exploit regularity assumptions on individual functions in form of a Gaussian Process (GP) prior. We combine these into a coherent optimization framework using problem structure. The resulting algorithm is able to provably verify complex safety specifications or alternatively find counter examples. Experimental results show that the proposed method is able to find adversarial examples quickly.
Data-driven Planning via Imitation Learning
Nov 17, 2017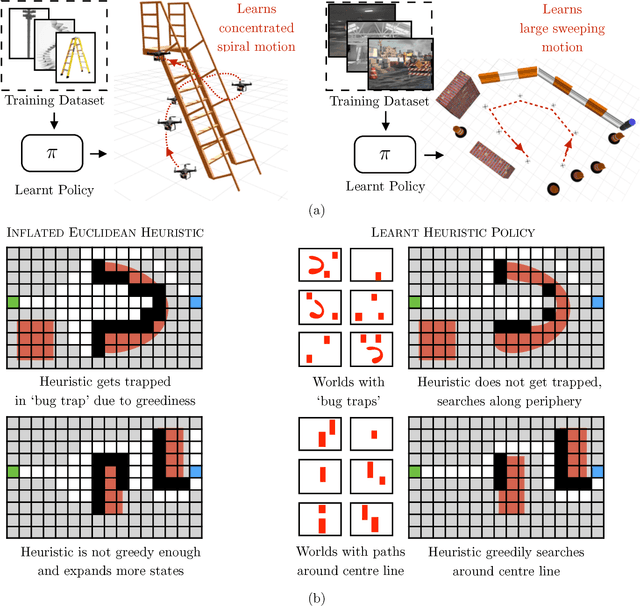
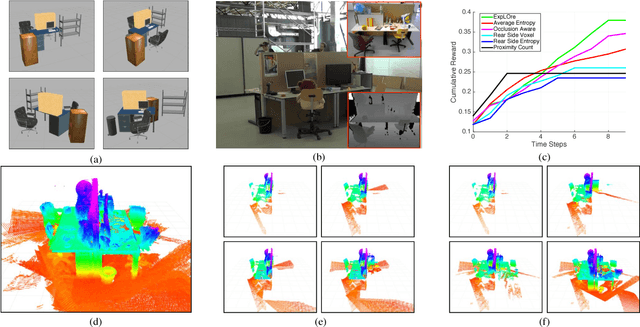
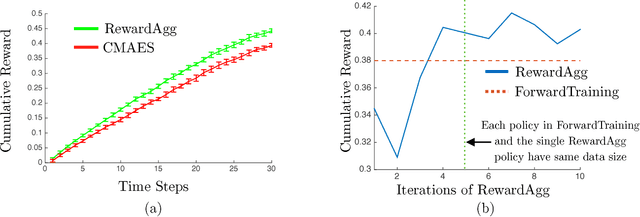
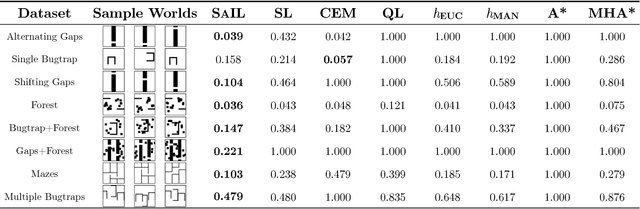
Robot planning is the process of selecting a sequence of actions that optimize for a task specific objective. The optimal solutions to such tasks are heavily influenced by the implicit structure in the environment, i.e. the configuration of objects in the world. State-of-the-art planning approaches, however, do not exploit this structure, thereby expending valuable effort searching the action space instead of focusing on potentially good actions. In this paper, we address the problem of enabling planners to adapt their search strategies by inferring such good actions in an efficient manner using only the information uncovered by the search up until that time. We formulate this as a problem of sequential decision making under uncertainty where at a given iteration a planning policy must map the state of the search to a planning action. Unfortunately, the training process for such partial information based policies is slow to converge and susceptible to poor local minima. Our key insight is that if we could fully observe the underlying world map, we would easily be able to disambiguate between good and bad actions. We hence present a novel data-driven imitation learning framework to efficiently train planning policies by imitating a clairvoyant oracle - an oracle that at train time has full knowledge about the world map and can compute optimal decisions. We leverage the fact that for planning problems, such oracles can be efficiently computed and derive performance guarantees for the learnt policy. We examine two important domains that rely on partial information based policies - informative path planning and search based motion planning. We validate the approach on a spectrum of environments for both problem domains, including experiments on a real UAV, and show that the learnt policy consistently outperforms state-of-the-art algorithms.
Adaptive Information Gathering via Imitation Learning
May 22, 2017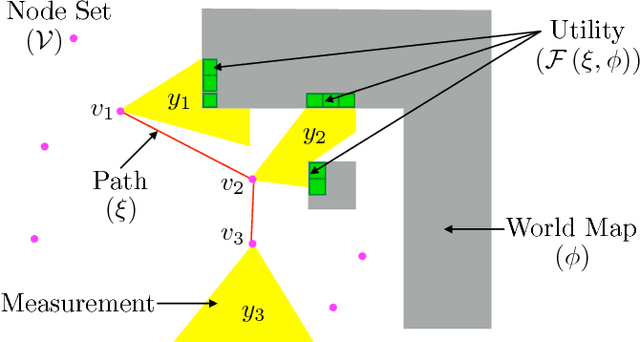

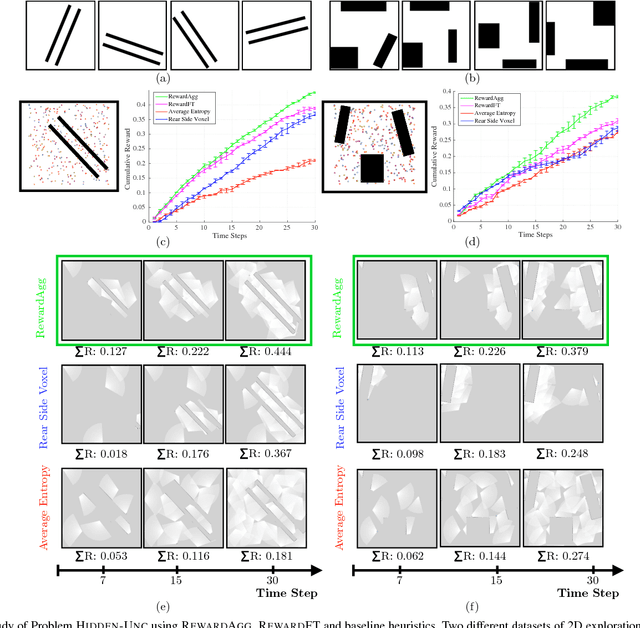

In the adaptive information gathering problem, a policy is required to select an informative sensing location using the history of measurements acquired thus far. While there is an extensive amount of prior work investigating effective practical approximations using variants of Shannon's entropy, the efficacy of such policies heavily depends on the geometric distribution of objects in the world. On the other hand, the principled approach of employing online POMDP solvers is rendered impractical by the need to explicitly sample online from a posterior distribution of world maps. We present a novel data-driven imitation learning framework to efficiently train information gathering policies. The policy imitates a clairvoyant oracle - an oracle that at train time has full knowledge about the world map and can compute maximally informative sensing locations. We analyze the learnt policy by showing that offline imitation of a clairvoyant oracle is implicitly equivalent to online oracle execution in conjunction with posterior sampling. This observation allows us to obtain powerful near-optimality guarantees for information gathering problems possessing an adaptive sub-modularity property. As demonstrated on a spectrum of 2D and 3D exploration problems, the trained policies enjoy the best of both worlds - they adapt to different world map distributions while being computationally inexpensive to evaluate.
Learning to Gather Information via Imitation
Nov 13, 2016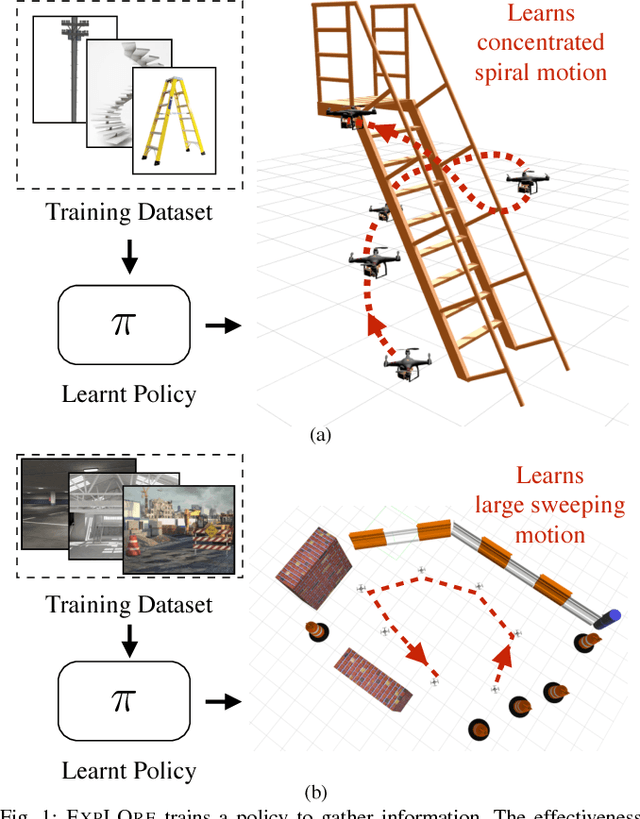
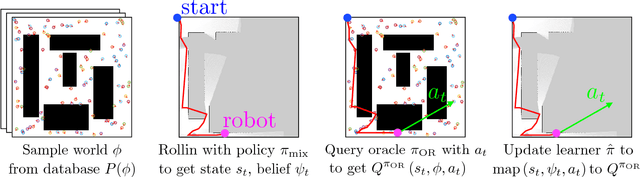
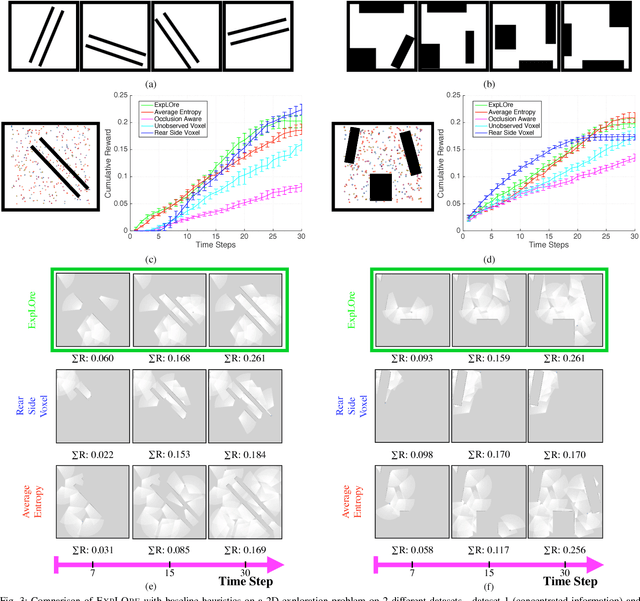
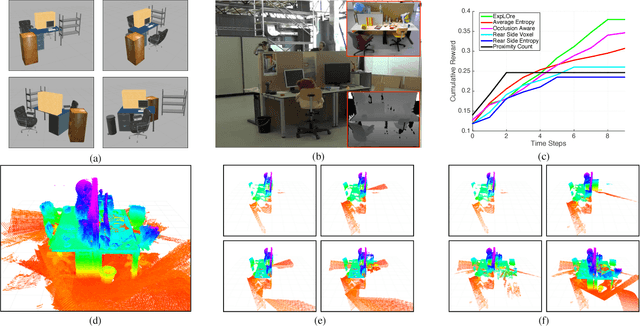
The budgeted information gathering problem - where a robot with a fixed fuel budget is required to maximize the amount of information gathered from the world - appears in practice across a wide range of applications in autonomous exploration and inspection with mobile robots. Although there is an extensive amount of prior work investigating effective approximations of the problem, these methods do not address the fact that their performance is heavily dependent on distribution of objects in the world. In this paper, we attempt to address this issue by proposing a novel data-driven imitation learning framework. We present an efficient algorithm, EXPLORE, that trains a policy on the target distribution to imitate a clairvoyant oracle - an oracle that has full information about the world and computes non-myopic solutions to maximize information gathered. We validate the approach on a spectrum of results on a number of 2D and 3D exploration problems that demonstrates the ability of EXPLORE to adapt to different object distributions. Additionally, our analysis provides theoretical insight into the behavior of EXPLORE. Our approach paves the way forward for efficiently applying data-driven methods to the domain of information gathering.
No-Regret Replanning under Uncertainty
Sep 16, 2016

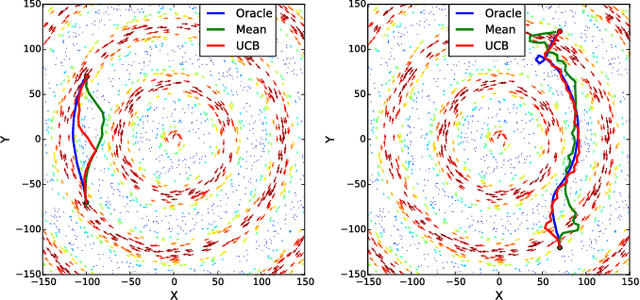
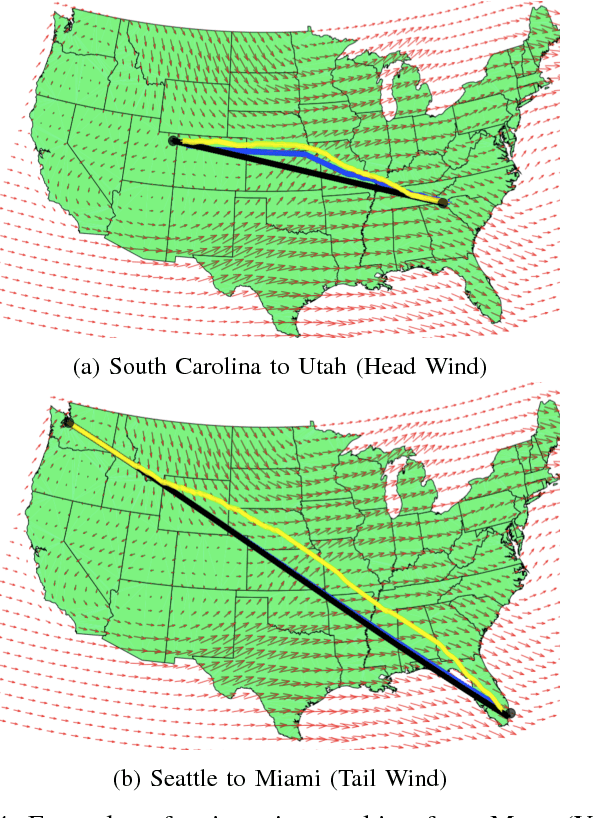
This paper explores the problem of path planning under uncertainty. Specifically, we consider online receding horizon based planners that need to operate in a latent environment where the latent information can be modeled via Gaussian Processes. Online path planning in latent environments is challenging since the robot needs to explore the environment to get a more accurate model of latent information for better planning later and also achieves the task as quick as possible. We propose UCB style algorithms that are popular in the bandit settings and show how those analyses can be adapted to the online robotic path planning problems. The proposed algorithm trades-off exploration and exploitation in near-optimal manner and has appealing no-regret properties. We demonstrate the efficacy of the framework on the application of aircraft flight path planning when the winds are partially observed.