 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHindsight is Only 50/50: Unsuitability of MDP based Approximate POMDP Solvers for Multi-resolution Information Gathering
Apr 07, 2018
Partially Observable Markov Decision Processes (POMDPs) offer an elegant framework to model sequential decision making in uncertain environments. Solving POMDPs online is an active area of research and given the size of real-world problems approximate solvers are used. Recently, a few approaches have been suggested for solving POMDPs by using MDP solvers in conjunction with imitation learning. MDP based POMDP solvers work well for some cases, while catastrophically failing for others. The main failure point of such solvers is the lack of motivation for MDP solvers to gain information, since under their assumption the environment is either already known as much as it can be or the uncertainty will disappear after the next step. However for solving POMDP problems gaining information can lead to efficient solutions. In this paper we derive a set of conditions where MDP based POMDP solvers are provably sub-optimal. We then use the well-known tiger problem to demonstrate such sub-optimality. We show that multi-resolution, budgeted information gathering cannot be addressed using MDP based POMDP solvers. The contribution of the paper helps identify the properties of a POMDP problem for which the use of MDP based POMDP solvers is inappropriate, enabling better design choices.
Data-driven Planning via Imitation Learning
Nov 17, 2017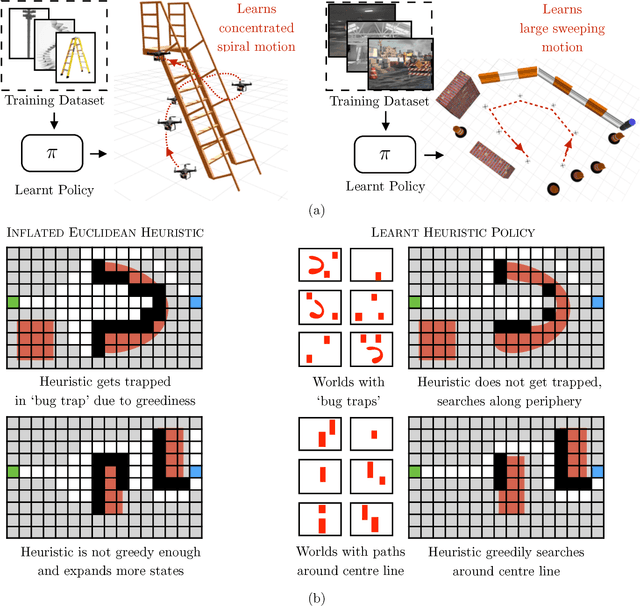
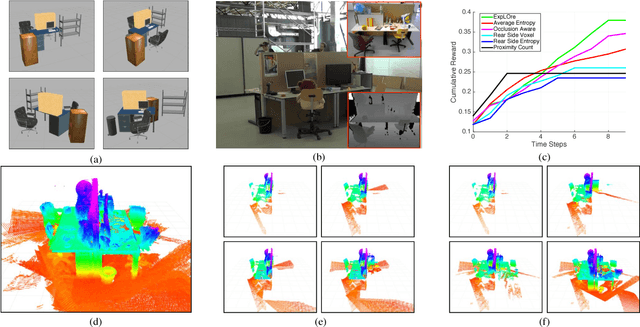
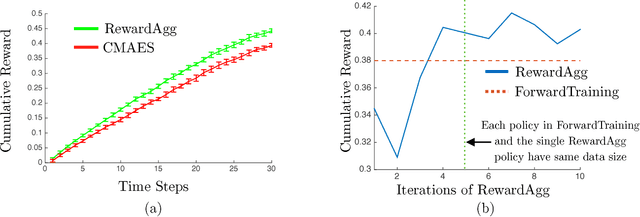
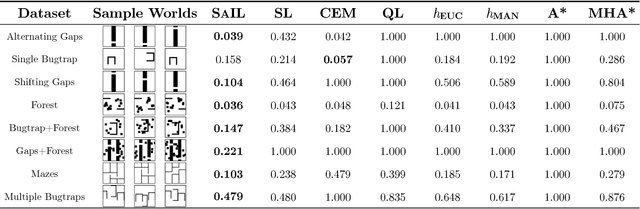
Robot planning is the process of selecting a sequence of actions that optimize for a task specific objective. The optimal solutions to such tasks are heavily influenced by the implicit structure in the environment, i.e. the configuration of objects in the world. State-of-the-art planning approaches, however, do not exploit this structure, thereby expending valuable effort searching the action space instead of focusing on potentially good actions. In this paper, we address the problem of enabling planners to adapt their search strategies by inferring such good actions in an efficient manner using only the information uncovered by the search up until that time. We formulate this as a problem of sequential decision making under uncertainty where at a given iteration a planning policy must map the state of the search to a planning action. Unfortunately, the training process for such partial information based policies is slow to converge and susceptible to poor local minima. Our key insight is that if we could fully observe the underlying world map, we would easily be able to disambiguate between good and bad actions. We hence present a novel data-driven imitation learning framework to efficiently train planning policies by imitating a clairvoyant oracle - an oracle that at train time has full knowledge about the world map and can compute optimal decisions. We leverage the fact that for planning problems, such oracles can be efficiently computed and derive performance guarantees for the learnt policy. We examine two important domains that rely on partial information based policies - informative path planning and search based motion planning. We validate the approach on a spectrum of environments for both problem domains, including experiments on a real UAV, and show that the learnt policy consistently outperforms state-of-the-art algorithms.