 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control
Jan 30, 2026Achieving robust, human-like whole-body control on humanoid robots for agile, contact-rich behaviors remains a central challenge, demanding heavy per-skill engineering and a brittle process of tuning controllers. We introduce ZEST (Zero-shot Embodied Skill Transfer), a streamlined motion-imitation framework that trains policies via reinforcement learning from diverse sources -- high-fidelity motion capture, noisy monocular video, and non-physics-constrained animation -- and deploys them to hardware zero-shot. ZEST generalizes across behaviors and platforms while avoiding contact labels, reference or observation windows, state estimators, and extensive reward shaping. Its training pipeline combines adaptive sampling, which focuses training on difficult motion segments, and an automatic curriculum using a model-based assistive wrench, together enabling dynamic, long-horizon maneuvers. We further provide a procedure for selecting joint-level gains from approximate analytical armature values for closed-chain actuators, along with a refined model of actuators. Trained entirely in simulation with moderate domain randomization, ZEST demonstrates remarkable generality. On Boston Dynamics' Atlas humanoid, ZEST learns dynamic, multi-contact skills (e.g., army crawl, breakdancing) from motion capture. It transfers expressive dance and scene-interaction skills, such as box-climbing, directly from videos to Atlas and the Unitree G1. Furthermore, it extends across morphologies to the Spot quadruped, enabling acrobatics, such as a continuous backflip, through animation. Together, these results demonstrate robust zero-shot deployment across heterogeneous data sources and embodiments, establishing ZEST as a scalable interface between biological movements and their robotic counterparts.
Dynamic Non-Prehensile Object Transport via Model-Predictive Reinforcement Learning
Nov 27, 2024



We investigate the problem of teaching a robot manipulator to perform dynamic non-prehensile object transport, also known as the `robot waiter' task, from a limited set of real-world demonstrations. We propose an approach that combines batch reinforcement learning (RL) with model-predictive control (MPC) by pretraining an ensemble of value functions from demonstration data, and utilizing them online within an uncertainty-aware MPC scheme to ensure robustness to limited data coverage. Our approach is straightforward to integrate with off-the-shelf MPC frameworks and enables learning solely from task space demonstrations with sparsely labeled transitions, while leveraging MPC to ensure smooth joint space motions and constraint satisfaction. We validate the proposed approach through extensive simulated and real-world experiments on a Franka Panda robot performing the robot waiter task and demonstrate robust deployment of value functions learned from 50-100 demonstrations. Furthermore, our approach enables generalization to novel objects not seen during training and can improve upon suboptimal demonstrations. We believe that such a framework can reduce the burden of providing extensive demonstrations and facilitate rapid training of robot manipulators to perform non-prehensile manipulation tasks. Project videos and supplementary material can be found at: https://sites.google.com/view/cvmpc.
Real-World Fluid Directed Rigid Body Control via Deep Reinforcement Learning
Feb 08, 2024

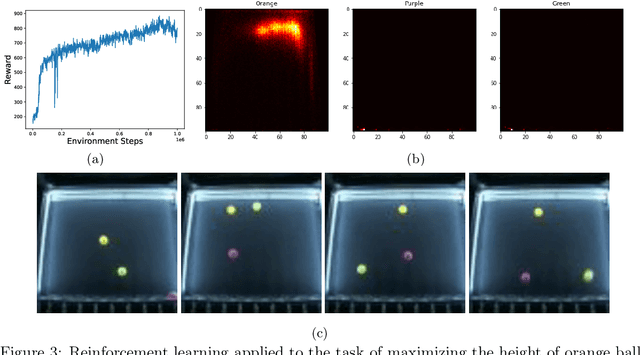
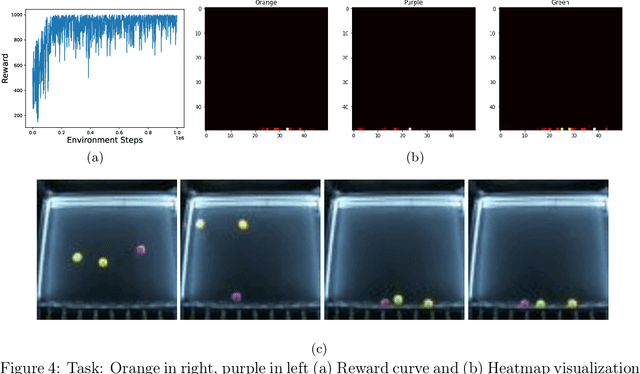
Recent advances in real-world applications of reinforcement learning (RL) have relied on the ability to accurately simulate systems at scale. However, domains such as fluid dynamical systems exhibit complex dynamic phenomena that are hard to simulate at high integration rates, limiting the direct application of modern deep RL algorithms to often expensive or safety critical hardware. In this work, we introduce "Box o Flows", a novel benchtop experimental control system for systematically evaluating RL algorithms in dynamic real-world scenarios. We describe the key components of the Box o Flows, and through a series of experiments demonstrate how state-of-the-art model-free RL algorithms can synthesize a variety of complex behaviors via simple reward specifications. Furthermore, we explore the role of offline RL in data-efficient hypothesis testing by reusing past experiences. We believe that the insights gained from this preliminary study and the availability of systems like the Box o Flows support the way forward for developing systematic RL algorithms that can be generally applied to complex, dynamical systems. Supplementary material and videos of experiments are available at https://sites.google.com/view/box-o-flows/home.
Adversarial Model for Offline Reinforcement Learning
Feb 21, 2023



We propose a novel model-based offline Reinforcement Learning (RL) framework, called Adversarial Model for Offline Reinforcement Learning (ARMOR), which can robustly learn policies to improve upon an arbitrary reference policy regardless of data coverage. ARMOR is designed to optimize policies for the worst-case performance relative to the reference policy through adversarially training a Markov decision process model. In theory, we prove that ARMOR, with a well-tuned hyperparameter, can compete with the best policy within data coverage when the reference policy is supported by the data. At the same time, ARMOR is robust to hyperparameter choices: the policy learned by ARMOR, with "any" admissible hyperparameter, would never degrade the performance of the reference policy, even when the reference policy is not covered by the dataset. To validate these properties in practice, we design a scalable implementation of ARMOR, which by adversarial training, can optimize policies without using model ensembles in contrast to typical model-based methods. We show that ARMOR achieves competent performance with both state-of-the-art offline model-free and model-based RL algorithms and can robustly improve the reference policy over various hyperparameter choices.
ARMOR: A Model-based Framework for Improving Arbitrary Baseline Policies with Offline Data
Nov 08, 2022We propose a new model-based offline RL framework, called Adversarial Models for Offline Reinforcement Learning (ARMOR), which can robustly learn policies to improve upon an arbitrary baseline policy regardless of data coverage. Based on the concept of relative pessimism, ARMOR is designed to optimize for the worst-case relative performance when facing uncertainty. In theory, we prove that the learned policy of ARMOR never degrades the performance of the baseline policy with any admissible hyperparameter, and can learn to compete with the best policy within data coverage when the hyperparameter is well tuned, and the baseline policy is supported by the data. Such a robust policy improvement property makes ARMOR especially suitable for building real-world learning systems, because in practice ensuring no performance degradation is imperative before considering any benefit learning can bring.
Leveraging Experience in Lazy Search
Oct 10, 2021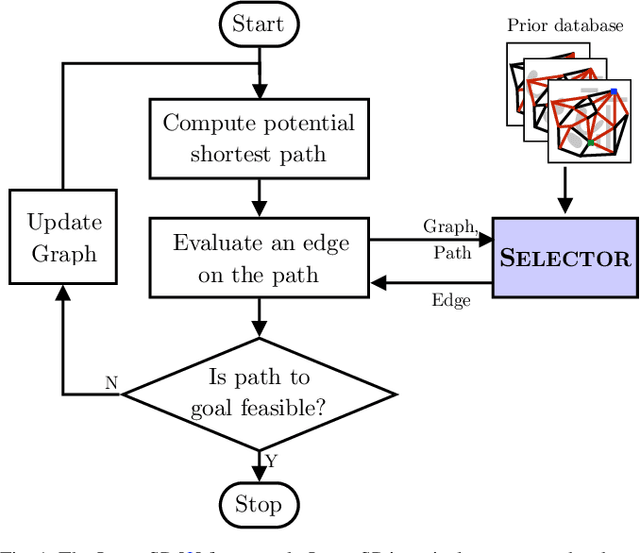
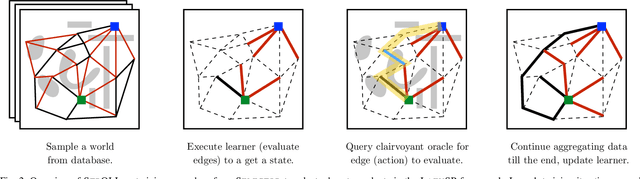
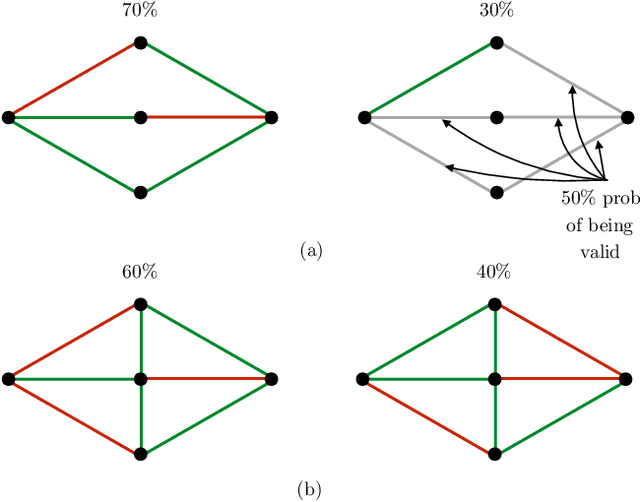
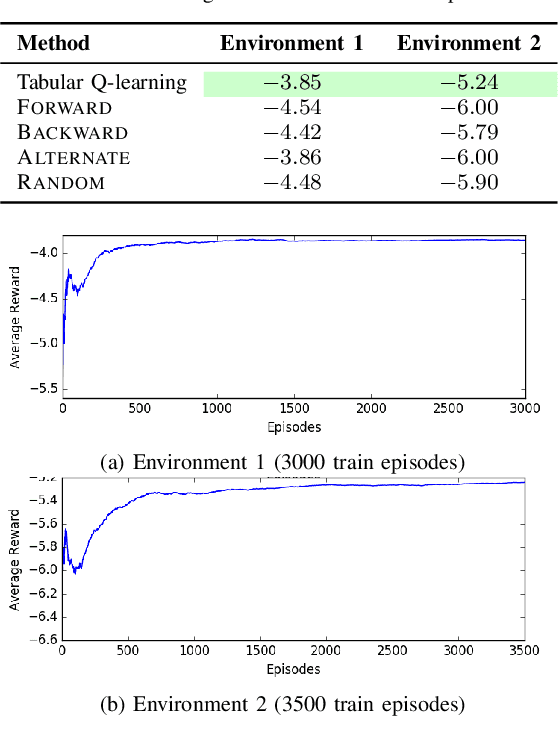
Lazy graph search algorithms are efficient at solving motion planning problems where edge evaluation is the computational bottleneck. These algorithms work by lazily computing the shortest potentially feasible path, evaluating edges along that path, and repeating until a feasible path is found. The order in which edges are selected is critical to minimizing the total number of edge evaluations: a good edge selector chooses edges that are not only likely to be invalid, but also eliminates future paths from consideration. We wish to learn such a selector by leveraging prior experience. We formulate this problem as a Markov Decision Process (MDP) on the state of the search problem. While solving this large MDP is generally intractable, we show that we can compute oracular selectors that can solve the MDP during training. With access to such oracles, we use imitation learning to find effective policies. If new search problems are sufficiently similar to problems solved during training, the learned policy will choose a good edge evaluation ordering and solve the motion planning problem quickly. We evaluate our algorithms on a wide range of 2D and 7D problems and show that the learned selector outperforms baseline commonly used heuristics. We further provide a novel theoretical analysis of lazy search in a Bayesian framework as well as regret guarantees on our imitation learning based approach to motion planning.
Fast Joint Space Model-Predictive Control for Reactive Manipulation
Apr 28, 2021
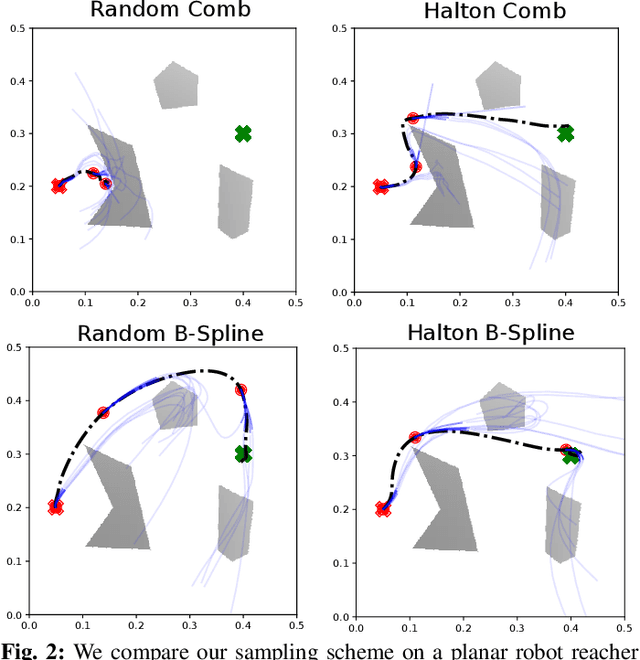
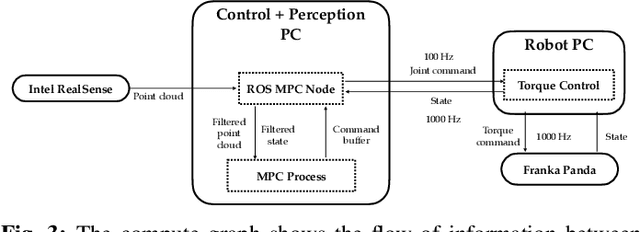
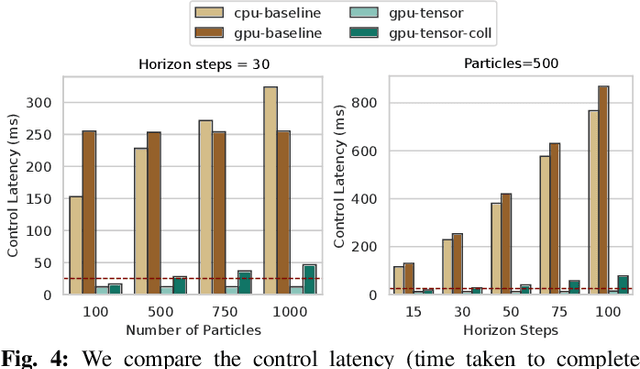
Sampling-based model predictive control (MPC) is a promising tool for feedback control of robots with complex and non-smooth dynamics and cost functions. The computationally demanding nature of sampling-based MPC algorithms is a key bottleneck in their application to high-dimensional robotic manipulation problems. Previous methods have addressed this issue by running MPC in the task space while relying on a low-level operational space controller for joint control. However, by not using the joint space of the robot in the MPC formulation, existing methods cannot directly account for non-task space related constraints such as avoiding joint limits, singular configurations, and link collisions. In this paper, we develop a joint space sampling-based MPC for manipulators that can be efficiently parallelized using GPUs. Our approach can handle task and joint space constraints while taking less than 0.02 seconds (50Hz) to compute the next control command. Further, our method can integrate perception into the control problem by utilizing learned cost functions from raw sensor data. We validate our approach by deploying it on a Franka Panda robot for a variety of common manipulation tasks. We study the effect of different cost formulations and MPC parameters on the synthesized behavior and provide key insights that pave the way for the application of sampling-based MPC for manipulators in a principled manner. Videos of experiments can be found at: https://sites.google.com/view/manipulation-mppi.
Blending MPC & Value Function Approximation for Efficient Reinforcement Learning
Dec 10, 2020
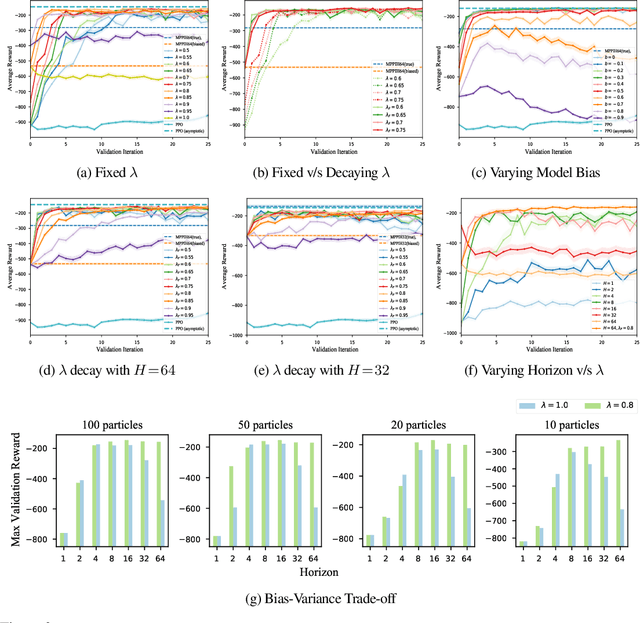
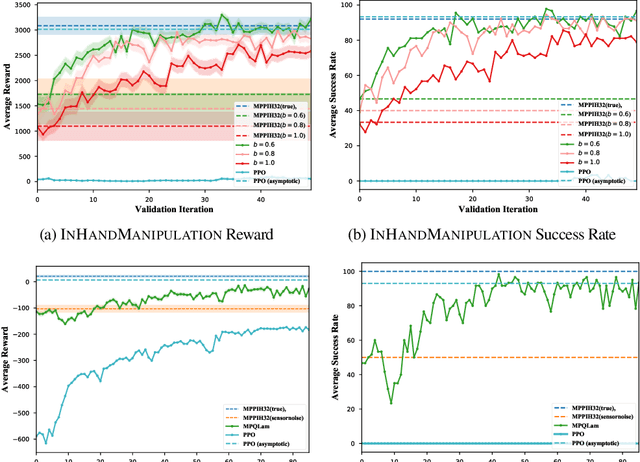
Model-Predictive Control (MPC) is a powerful tool for controlling complex, real-world systems that uses a model to make predictions about future behavior. For each state encountered, MPC solves an online optimization problem to choose a control action that will minimize future cost. This is a surprisingly effective strategy, but real-time performance requirements warrant the use of simple models. If the model is not sufficiently accurate, then the resulting controller can be biased, limiting performance. We present a framework for improving on MPC with model-free reinforcement learning (RL). The key insight is to view MPC as constructing a series of local Q-function approximations. We show that by using a parameter $\lambda$, similar to the trace decay parameter in TD($\lambda$), we can systematically trade-off learned value estimates against the local Q-function approximations. We present a theoretical analysis that shows how error from inaccurate models in MPC and value function estimation in RL can be balanced. We further propose an algorithm that changes $\lambda$ over time to reduce the dependence on MPC as our estimates of the value function improve, and test the efficacy our approach on challenging high-dimensional manipulation tasks with biased models in simulation. We demonstrate that our approach can obtain performance comparable with MPC with access to true dynamics even under severe model bias and is more sample efficient as compared to model-free RL.
Information Theoretic Model Predictive Q-Learning
Dec 31, 2019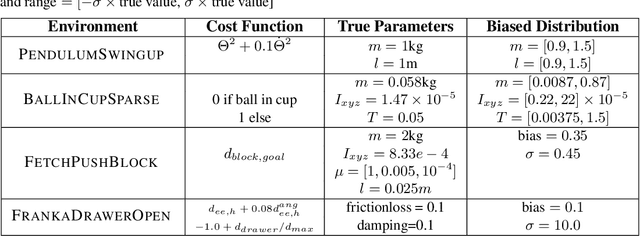
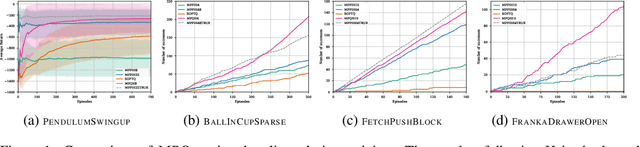
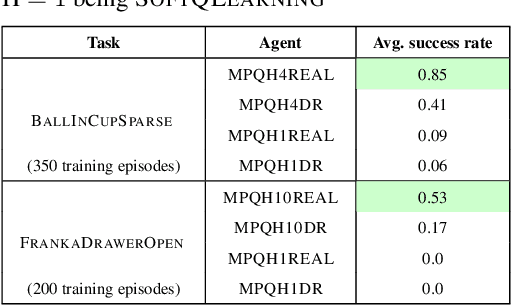
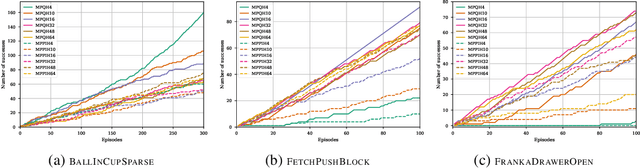
Model-free Reinforcement Learning (RL) algorithms work well in sequential decision-making problems when experience can be collected cheaply and model-based RL is effective when system dynamics can be modeled accurately. However, both of these assumptions can be violated in real world problems such as robotics, where querying the system can be prohibitively expensive and real-world dynamics can be difficult to model accurately. Although sim-to-real approaches such as domain randomization attempt to mitigate the effects of biased simulation,they can still suffer from optimization challenges such as local minima and hand-designed distributions for randomization, making it difficult to learn an accurate global value function or policy that directly transfers to the real world. In contrast to RL, Model Predictive Control (MPC) algorithms use a simulator to optimize a simple policy class online, constructing a closed-loop controller that can effectively contend with real-world dynamics. MPC performance is usually limited by factors such as model bias and the limited horizon of optimization. In this work, we present a novel theoretical connection between information theoretic MPC and entropy regularized RL and develop a Q-learning algorithm that can leverage biased models. We validate the proposed algorithm on sim-to-sim control tasks to demonstrate the improvements over optimal control and reinforcement learning from scratch. Our approach paves the way for deploying reinforcement learning algorithms on real-robots in a systematic manner.
Differentiable Gaussian Process Motion Planning
Jul 22, 2019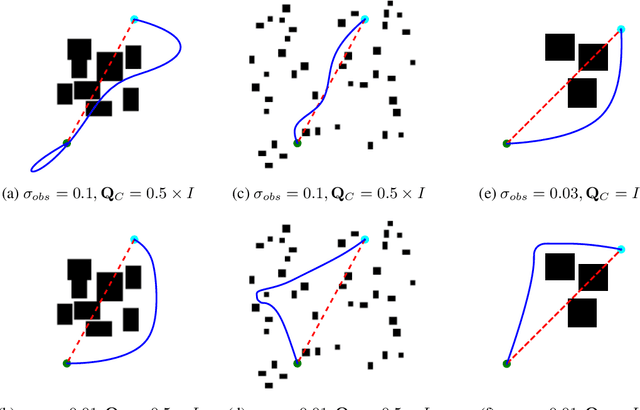
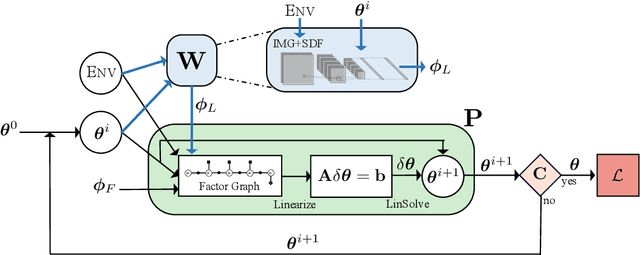
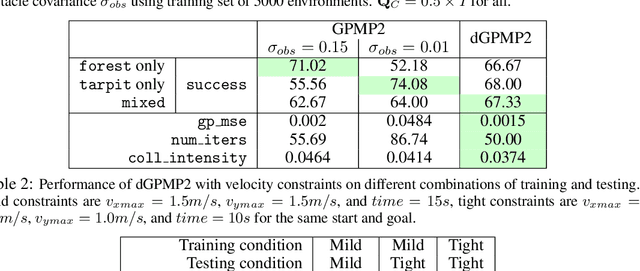
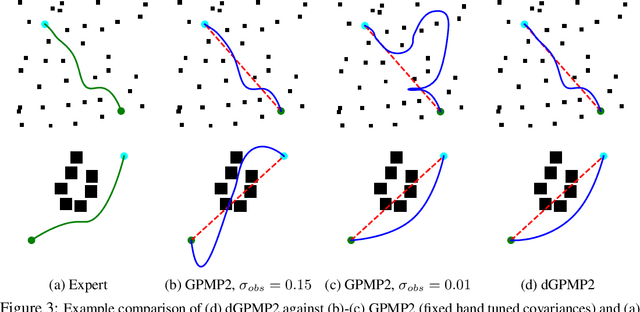
Modern trajectory optimization based approaches to motion planning are fast, easy to implement, and effective on a wide range of robotics tasks. However, trajectory optimization algorithms have parameters that are typically set in advance (and rarely discussed in detail). Setting these parameters properly can have a significant impact on the practical performance of the algorithm, sometimes making the difference between finding a feasible plan or failing at the task entirely. We propose a method for leveraging past experience to learn how to automatically adapt the parameters of Gaussian Process Motion Planning (GPMP) algorithms. Specifically, we propose a differentiable extension to the GPMP2 algorithm, so that it can be trained end-to-end from data. We perform several experiments that validate our algorithm and illustrate the benefits of our proposed learning-based approach to motion planning.