 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspGen-X: Cross-Embodiment 6-DOF Diffusion-based Grasping
May 31, 2026We study cross-embodiment 6-DOF robot grasping. Unlike prior works, we require the model not only to generalize to novel objects / scenes but also to novel gripper morphologies and physical grasping processes. Our method extends diffusion model based generative 6-DOF grasping models to condition on the additional gripper's representation. We propose a swept-volume heuristic for encoding the gripper. We train our cross-embodiment model with procedural grippers and a large-scale dataset of 2 Billion grasps. In simulation experiments, our model has the best zero-shot generalization to novel real-world grippers and objects over baseline methods. Our model also serves as a good initialization for fine-tuning to adapt to novel grippers. In ablations, we demonstrate the efficiency of our sweep-volume gripper representation and our procedural gripper training dataset. Last, we show zero-shot generalization to real-world novel grippers for 6-DOF grasping, surpassing baselines in cross-embodiment generalization.
cuRoboV2: Dynamics-Aware Motion Generation with Depth-Fused Distance Fields for High-DoF Robots
Mar 05, 2026Effective robot autonomy requires motion generation that is safe, feasible, and reactive. Current methods are fragmented: fast planners output physically unexecutable trajectories, reactive controllers struggle with high-fidelity perception, and existing solvers fail on high-DoF systems. We present cuRoboV2, a unified framework with three key innovations: (1) B-spline trajectory optimization that enforces smoothness and torque limits; (2) a GPU-native TSDF/ESDF perception pipeline that generates dense signed distance fields covering the full workspace, unlike existing methods that only provide distances within sparsely allocated blocks, up to 10x faster and in 8x less memory than the state-of-the-art at manipulation scale, with up to 99% collision recall; and (3) scalable GPU-native whole-body computation, namely topology-aware kinematics, differentiable inverse dynamics, and map-reduce self-collision, that achieves up to 61x speedup while also extending to high-DoF humanoids (where previous GPU implementations fail). On benchmarks, cuRoboV2 achieves 99.7% success under 3kg payload (where baselines achieve only 72--77%), 99.6% collision-free IK on a 48-DoF humanoid (where prior methods fail entirely), and 89.5% retargeting constraint satisfaction (vs. 61% for PyRoki); these collision-free motions yield locomotion policies with 21% lower tracking error than PyRoki and 12x lower cross-seed variance than mink. A ground-up codebase redesign for discoverability enabled LLM coding assistants to author up to 73% of new modules, including hand-optimized CUDA kernels, demonstrating that well-structured robotics code can unlock productive human--LLM collaboration. Together, these advances provide a unified, dynamics-aware motion generation stack that scales from single-arm manipulators to full humanoids.
GraspGen: A Diffusion-based Framework for 6-DOF Grasping with On-Generator Training
Jul 17, 2025Grasping is a fundamental robot skill, yet despite significant research advancements, learning-based 6-DOF grasping approaches are still not turnkey and struggle to generalize across different embodiments and in-the-wild settings. We build upon the recent success on modeling the object-centric grasp generation process as an iterative diffusion process. Our proposed framework, GraspGen, consists of a DiffusionTransformer architecture that enhances grasp generation, paired with an efficient discriminator to score and filter sampled grasps. We introduce a novel and performant on-generator training recipe for the discriminator. To scale GraspGen to both objects and grippers, we release a new simulated dataset consisting of over 53 million grasps. We demonstrate that GraspGen outperforms prior methods in simulations with singulated objects across different grippers, achieves state-of-the-art performance on the FetchBench grasping benchmark, and performs well on a real robot with noisy visual observations.
Dynamic Non-Prehensile Object Transport via Model-Predictive Reinforcement Learning
Nov 27, 2024



We investigate the problem of teaching a robot manipulator to perform dynamic non-prehensile object transport, also known as the `robot waiter' task, from a limited set of real-world demonstrations. We propose an approach that combines batch reinforcement learning (RL) with model-predictive control (MPC) by pretraining an ensemble of value functions from demonstration data, and utilizing them online within an uncertainty-aware MPC scheme to ensure robustness to limited data coverage. Our approach is straightforward to integrate with off-the-shelf MPC frameworks and enables learning solely from task space demonstrations with sparsely labeled transitions, while leveraging MPC to ensure smooth joint space motions and constraint satisfaction. We validate the proposed approach through extensive simulated and real-world experiments on a Franka Panda robot performing the robot waiter task and demonstrate robust deployment of value functions learned from 50-100 demonstrations. Furthermore, our approach enables generalization to novel objects not seen during training and can improve upon suboptimal demonstrations. We believe that such a framework can reduce the burden of providing extensive demonstrations and facilitate rapid training of robot manipulators to perform non-prehensile manipulation tasks. Project videos and supplementary material can be found at: https://sites.google.com/view/cvmpc.
Inference-Time Policy Steering through Human Interactions
Nov 25, 2024



Generative policies trained with human demonstrations can autonomously accomplish multimodal, long-horizon tasks. However, during inference, humans are often removed from the policy execution loop, limiting the ability to guide a pre-trained policy towards a specific sub-goal or trajectory shape among multiple predictions. Naive human intervention may inadvertently exacerbate distribution shift, leading to constraint violations or execution failures. To better align policy output with human intent without inducing out-of-distribution errors, we propose an Inference-Time Policy Steering (ITPS) framework that leverages human interactions to bias the generative sampling process, rather than fine-tuning the policy on interaction data. We evaluate ITPS across three simulated and real-world benchmarks, testing three forms of human interaction and associated alignment distance metrics. Among six sampling strategies, our proposed stochastic sampling with diffusion policy achieves the best trade-off between alignment and distribution shift. Videos are available at https://yanweiw.github.io/itps/.
DiffusionSeeder: Seeding Motion Optimization with Diffusion for Rapid Motion Planning
Oct 22, 2024Running optimization across many parallel seeds leveraging GPU compute have relaxed the need for a good initialization, but this can fail if the problem is highly non-convex as all seeds could get stuck in local minima. One such setting is collision-free motion optimization for robot manipulation, where optimization converges quickly on easy problems but struggle in obstacle dense environments (e.g., a cluttered cabinet or table). In these situations, graph-based planning algorithms are used to obtain seeds, resulting in significant slowdowns. We propose DiffusionSeeder, a diffusion based approach that generates trajectories to seed motion optimization for rapid robot motion planning. DiffusionSeeder takes the initial depth image observation of the scene and generates high quality, multi-modal trajectories that are then fine-tuned with a few iterations of motion optimization. We integrate DiffusionSeeder to generate the seed trajectories for cuRobo, a GPU-accelerated motion optimization method, which results in 12x speed up on average, and 36x speed up for more complicated problems, while achieving 10% higher success rate in partially observed simulation environments. Our results show the effectiveness of using diverse solutions from a learned diffusion model. Physical experiments on a Franka robot demonstrate the sim2real transfer of DiffusionSeeder to the real robot, with an average success rate of 86% and planning time of 26ms, improving on cuRobo by 51% higher success rate while also being 2.5x faster.
cuRobo: Parallelized Collision-Free Minimum-Jerk Robot Motion Generation
Nov 03, 2023
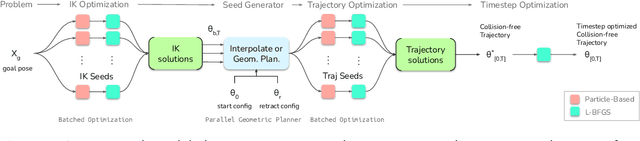
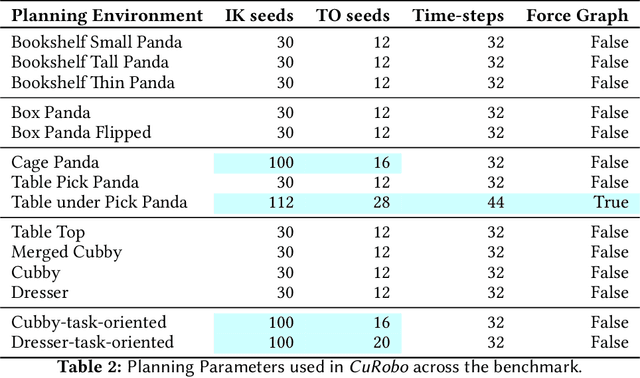
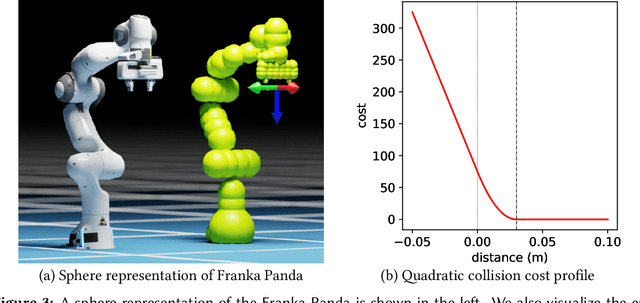
This paper explores the problem of collision-free motion generation for manipulators by formulating it as a global motion optimization problem. We develop a parallel optimization technique to solve this problem and demonstrate its effectiveness on massively parallel GPUs. We show that combining simple optimization techniques with many parallel seeds leads to solving difficult motion generation problems within 50ms on average, 60x faster than state-of-the-art (SOTA) trajectory optimization methods. We achieve SOTA performance by combining L-BFGS step direction estimation with a novel parallel noisy line search scheme and a particle-based optimization solver. To further aid trajectory optimization, we develop a parallel geometric planner that plans within 20ms and also introduce a collision-free IK solver that can solve over 7000 queries/s. We package our contributions into a state of the art GPU accelerated motion generation library, cuRobo and release it to enrich the robotics community. Additional details are available at https://curobo.org
VaPr: Variable-Precision Tensors to Accelerate Robot Motion Planning
Oct 11, 2023



High-dimensional motion generation requires numerical precision for smooth, collision-free solutions. Typically, double-precision or single-precision floating-point (FP) formats are utilized. Using these for big tensors imposes a strain on the memory bandwidth provided by the devices and alters the memory footprint, hence limiting their applicability to low-power edge devices needed for mobile robots. The uniform application of reduced precision can be advantageous but severely degrades solutions. Using decreased precision data types for important tensors, we propose to accelerate motion generation by removing memory bottlenecks. We propose variable-precision (VaPr) search optimization to determine the appropriate precision for large tensors from a vast search space of approximately 4 million unique combinations for FP data types across the tensors. To obtain the efficiency gains, we exploit existing platform support for an out-of-the-box GPU speedup and evaluate prospective precision converter units for GPU types that are not currently supported. Our experimental results on 800 planning problems for the Franka Panda robot on the MotionBenchmaker dataset across 8 environments show that a 4-bit FP format is sufficient for the largest set of tensors in the motion generation stack. With the software-only solution, VaPr achieves 6.3% and 6.3% speedups on average for a significant portion of motion generation over the SOTA solution (CuRobo) on Jetson Orin and RTX2080 Ti GPU, respectively, and 9.9%, 17.7% speedups with the FP converter.
Diff-DOPE: Differentiable Deep Object Pose Estimation
Sep 30, 2023
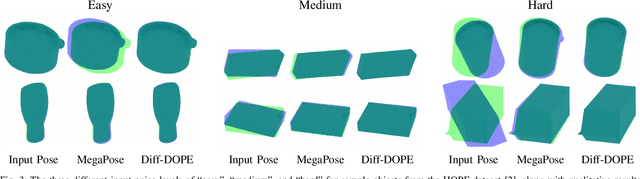
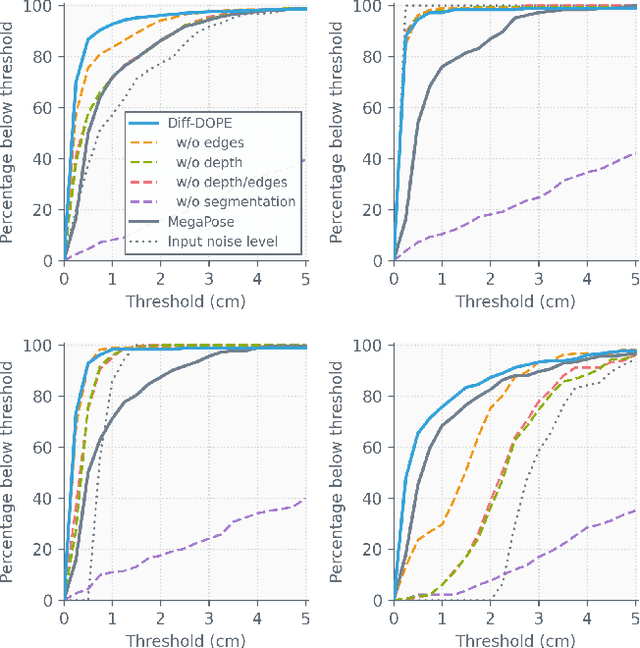

We introduce Diff-DOPE, a 6-DoF pose refiner that takes as input an image, a 3D textured model of an object, and an initial pose of the object. The method uses differentiable rendering to update the object pose to minimize the visual error between the image and the projection of the model. We show that this simple, yet effective, idea is able to achieve state-of-the-art results on pose estimation datasets. Our approach is a departure from recent methods in which the pose refiner is a deep neural network trained on a large synthetic dataset to map inputs to refinement steps. Rather, our use of differentiable rendering allows us to avoid training altogether. Our approach performs multiple gradient descent optimizations in parallel with different random learning rates to avoid local minima from symmetric objects, similar appearances, or wrong step size. Various modalities can be used, e.g., RGB, depth, intensity edges, and object segmentation masks. We present experiments examining the effect of various choices, showing that the best results are found when the RGB image is accompanied by an object mask and depth image to guide the optimization process.
Meta-Policy Learning over Plan Ensembles for Robust Articulated Object Manipulation
Jul 08, 2023



Recent work has shown that complex manipulation skills, such as pushing or pouring, can be learned through state-of-the-art learning based techniques, such as Reinforcement Learning (RL). However, these methods often have high sample-complexity, are susceptible to domain changes, and produce unsafe motions that a robot should not perform. On the other hand, purely geometric model-based planning can produce complex behaviors that satisfy all the geometric constraints of the robot but might not be dynamically feasible for a given environment. In this work, we leverage a geometric model-based planner to build a mixture of path-policies on which a task-specific meta-policy can be learned to complete the task. In our results, we demonstrate that a successful meta-policy can be learned to push a door, while requiring little data and being robust to model uncertainty of the environment. We tested our method on a 7-DOF Franka-Emika Robot pushing a cabinet door in simulation.