 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspGen-X: Cross-Embodiment 6-DOF Diffusion-based Grasping
May 31, 2026We study cross-embodiment 6-DOF robot grasping. Unlike prior works, we require the model not only to generalize to novel objects / scenes but also to novel gripper morphologies and physical grasping processes. Our method extends diffusion model based generative 6-DOF grasping models to condition on the additional gripper's representation. We propose a swept-volume heuristic for encoding the gripper. We train our cross-embodiment model with procedural grippers and a large-scale dataset of 2 Billion grasps. In simulation experiments, our model has the best zero-shot generalization to novel real-world grippers and objects over baseline methods. Our model also serves as a good initialization for fine-tuning to adapt to novel grippers. In ablations, we demonstrate the efficiency of our sweep-volume gripper representation and our procedural gripper training dataset. Last, we show zero-shot generalization to real-world novel grippers for 6-DOF grasping, surpassing baselines in cross-embodiment generalization.
cuRoboV2: Dynamics-Aware Motion Generation with Depth-Fused Distance Fields for High-DoF Robots
Mar 05, 2026Effective robot autonomy requires motion generation that is safe, feasible, and reactive. Current methods are fragmented: fast planners output physically unexecutable trajectories, reactive controllers struggle with high-fidelity perception, and existing solvers fail on high-DoF systems. We present cuRoboV2, a unified framework with three key innovations: (1) B-spline trajectory optimization that enforces smoothness and torque limits; (2) a GPU-native TSDF/ESDF perception pipeline that generates dense signed distance fields covering the full workspace, unlike existing methods that only provide distances within sparsely allocated blocks, up to 10x faster and in 8x less memory than the state-of-the-art at manipulation scale, with up to 99% collision recall; and (3) scalable GPU-native whole-body computation, namely topology-aware kinematics, differentiable inverse dynamics, and map-reduce self-collision, that achieves up to 61x speedup while also extending to high-DoF humanoids (where previous GPU implementations fail). On benchmarks, cuRoboV2 achieves 99.7% success under 3kg payload (where baselines achieve only 72--77%), 99.6% collision-free IK on a 48-DoF humanoid (where prior methods fail entirely), and 89.5% retargeting constraint satisfaction (vs. 61% for PyRoki); these collision-free motions yield locomotion policies with 21% lower tracking error than PyRoki and 12x lower cross-seed variance than mink. A ground-up codebase redesign for discoverability enabled LLM coding assistants to author up to 73% of new modules, including hand-optimized CUDA kernels, demonstrating that well-structured robotics code can unlock productive human--LLM collaboration. Together, these advances provide a unified, dynamics-aware motion generation stack that scales from single-arm manipulators to full humanoids.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
GraspGen: A Diffusion-based Framework for 6-DOF Grasping with On-Generator Training
Jul 17, 2025Grasping is a fundamental robot skill, yet despite significant research advancements, learning-based 6-DOF grasping approaches are still not turnkey and struggle to generalize across different embodiments and in-the-wild settings. We build upon the recent success on modeling the object-centric grasp generation process as an iterative diffusion process. Our proposed framework, GraspGen, consists of a DiffusionTransformer architecture that enhances grasp generation, paired with an efficient discriminator to score and filter sampled grasps. We introduce a novel and performant on-generator training recipe for the discriminator. To scale GraspGen to both objects and grippers, we release a new simulated dataset consisting of over 53 million grasps. We demonstrate that GraspGen outperforms prior methods in simulations with singulated objects across different grippers, achieves state-of-the-art performance on the FetchBench grasping benchmark, and performs well on a real robot with noisy visual observations.
DiffusionSeeder: Seeding Motion Optimization with Diffusion for Rapid Motion Planning
Oct 22, 2024Running optimization across many parallel seeds leveraging GPU compute have relaxed the need for a good initialization, but this can fail if the problem is highly non-convex as all seeds could get stuck in local minima. One such setting is collision-free motion optimization for robot manipulation, where optimization converges quickly on easy problems but struggle in obstacle dense environments (e.g., a cluttered cabinet or table). In these situations, graph-based planning algorithms are used to obtain seeds, resulting in significant slowdowns. We propose DiffusionSeeder, a diffusion based approach that generates trajectories to seed motion optimization for rapid robot motion planning. DiffusionSeeder takes the initial depth image observation of the scene and generates high quality, multi-modal trajectories that are then fine-tuned with a few iterations of motion optimization. We integrate DiffusionSeeder to generate the seed trajectories for cuRobo, a GPU-accelerated motion optimization method, which results in 12x speed up on average, and 36x speed up for more complicated problems, while achieving 10% higher success rate in partially observed simulation environments. Our results show the effectiveness of using diverse solutions from a learned diffusion model. Physical experiments on a Franka robot demonstrate the sim2real transfer of DiffusionSeeder to the real robot, with an average success rate of 86% and planning time of 26ms, improving on cuRobo by 51% higher success rate while also being 2.5x faster.
RoboPoint: A Vision-Language Model for Spatial Affordance Prediction for Robotics
Jun 15, 2024From rearranging objects on a table to putting groceries into shelves, robots must plan precise action points to perform tasks accurately and reliably. In spite of the recent adoption of vision language models (VLMs) to control robot behavior, VLMs struggle to precisely articulate robot actions using language. We introduce an automatic synthetic data generation pipeline that instruction-tunes VLMs to robotic domains and needs. Using the pipeline, we train RoboPoint, a VLM that predicts image keypoint affordances given language instructions. Compared to alternative approaches, our method requires no real-world data collection or human demonstration, making it much more scalable to diverse environments and viewpoints. In addition, RoboPoint is a general model that enables several downstream applications such as robot navigation, manipulation, and augmented reality (AR) assistance. Our experiments demonstrate that RoboPoint outperforms state-of-the-art VLMs (GPT-4o) and visual prompting techniques (PIVOT) by 21.8% in the accuracy of predicting spatial affordance and by 30.5% in the success rate of downstream tasks. Project website: https://robo-point.github.io.
M2T2: Multi-Task Masked Transformer for Object-centric Pick and Place
Nov 02, 2023With the advent of large language models and large-scale robotic datasets, there has been tremendous progress in high-level decision-making for object manipulation. These generic models are able to interpret complex tasks using language commands, but they often have difficulties generalizing to out-of-distribution objects due to the inability of low-level action primitives. In contrast, existing task-specific models excel in low-level manipulation of unknown objects, but only work for a single type of action. To bridge this gap, we present M2T2, a single model that supplies different types of low-level actions that work robustly on arbitrary objects in cluttered scenes. M2T2 is a transformer model which reasons about contact points and predicts valid gripper poses for different action modes given a raw point cloud of the scene. Trained on a large-scale synthetic dataset with 128K scenes, M2T2 achieves zero-shot sim2real transfer on the real robot, outperforming the baseline system with state-of-the-art task-specific models by about 19% in overall performance and 37.5% in challenging scenes where the object needs to be re-oriented for collision-free placement. M2T2 also achieves state-of-the-art results on a subset of language conditioned tasks in RLBench. Videos of robot experiments on unseen objects in both real world and simulation are available on our project website https://m2-t2.github.io.
CabiNet: Scaling Neural Collision Detection for Object Rearrangement with Procedural Scene Generation
Apr 18, 2023
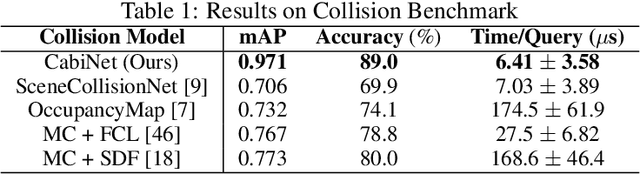
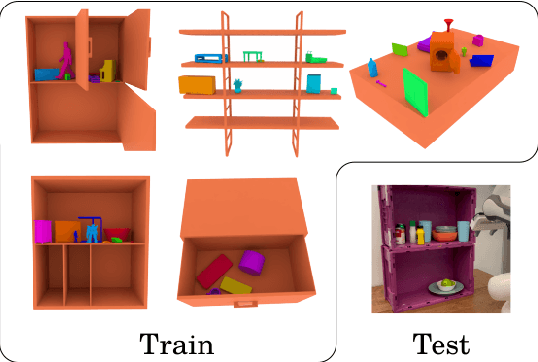
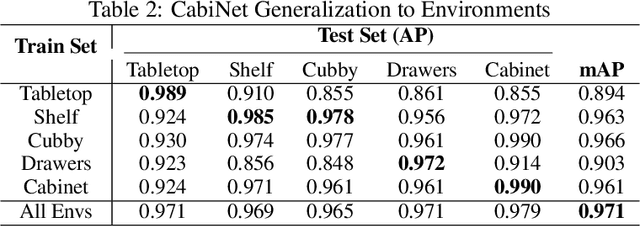
We address the important problem of generalizing robotic rearrangement to clutter without any explicit object models. We first generate over 650K cluttered scenes - orders of magnitude more than prior work - in diverse everyday environments, such as cabinets and shelves. We render synthetic partial point clouds from this data and use it to train our CabiNet model architecture. CabiNet is a collision model that accepts object and scene point clouds, captured from a single-view depth observation, and predicts collisions for SE(3) object poses in the scene. Our representation has a fast inference speed of 7 microseconds per query with nearly 20% higher performance than baseline approaches in challenging environments. We use this collision model in conjunction with a Model Predictive Path Integral (MPPI) planner to generate collision-free trajectories for picking and placing in clutter. CabiNet also predicts waypoints, computed from the scene's signed distance field (SDF), that allows the robot to navigate tight spaces during rearrangement. This improves rearrangement performance by nearly 35% compared to baselines. We systematically evaluate our approach, procedurally generate simulated experiments, and demonstrate that our approach directly transfers to the real world, despite training exclusively in simulation. Robot experiment demos in completely unknown scenes and objects can be found at this http https://cabinet-object-rearrangement.github.io
Neural Motion Fields: Encoding Grasp Trajectories as Implicit Value Functions
Jun 29, 2022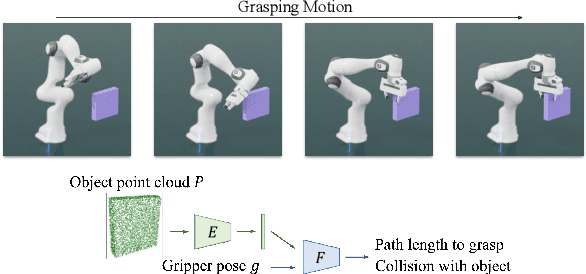



The pipeline of current robotic pick-and-place methods typically consists of several stages: grasp pose detection, finding inverse kinematic solutions for the detected poses, planning a collision-free trajectory, and then executing the open-loop trajectory to the grasp pose with a low-level tracking controller. While these grasping methods have shown good performance on grasping static objects on a table-top, the problem of grasping dynamic objects in constrained environments remains an open problem. We present Neural Motion Fields, a novel object representation which encodes both object point clouds and the relative task trajectories as an implicit value function parameterized by a neural network. This object-centric representation models a continuous distribution over the SE(3) space and allows us to perform grasping reactively by leveraging sampling-based MPC to optimize this value function.
HandoverSim: A Simulation Framework and Benchmark for Human-to-Robot Object Handovers
May 19, 2022

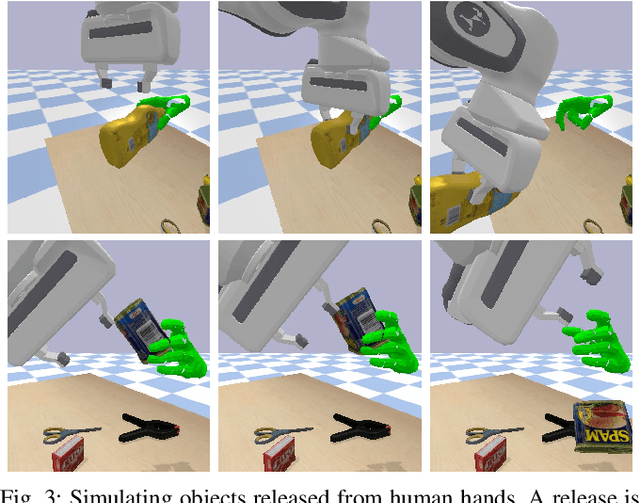

We introduce a new simulation benchmark "HandoverSim" for human-to-robot object handovers. To simulate the giver's motion, we leverage a recent motion capture dataset of hand grasping of objects. We create training and evaluation environments for the receiver with standardized protocols and metrics. We analyze the performance of a set of baselines and show a correlation with a real-world evaluation. Code is open sourced at https://handover-sim.github.io.