 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware Conditioned Policies for Multi-Robot Transfer Learning
Paper and Code

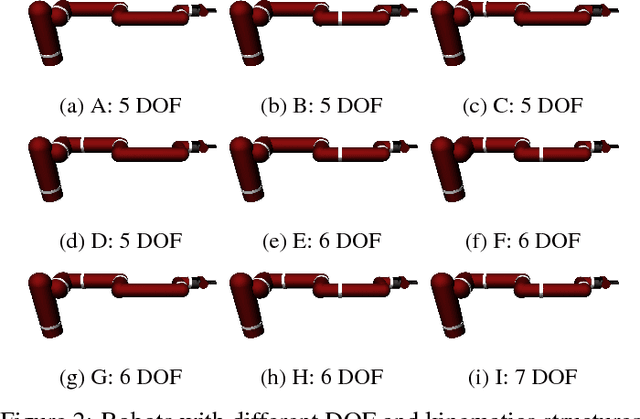


Deep reinforcement learning could be used to learn dexterous robotic policies but it is challenging to transfer them to new robots with vastly different hardware properties. It is also prohibitively expensive to learn a new policy from scratch for each robot hardware due to the high sample complexity of modern state-of-the-art algorithms. We propose a novel approach called \textit{Hardware Conditioned Policies} where we train a universal policy conditioned on a vector representation of robot hardware. We considered robots in simulation with varied dynamics, kinematic structure, kinematic lengths and degrees-of-freedom. First, we use the kinematic structure directly as the hardware encoding and show great zero-shot transfer to completely novel robots not seen during training. For robots with lower zero-shot success rate, we also demonstrate that fine-tuning the policy network is significantly more sample-efficient than training a model from scratch. In tasks where knowing the agent dynamics is important for success, we learn an embedding for robot hardware and show that policies conditioned on the encoding of hardware tend to generalize and transfer well. The code and videos are available on the project webpage: https://sites.google.com/view/robot-transfer-hcp.