 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDQ: Sparse Decomposed Quantization for LLM Inference
Jun 19, 2024



Recently, large language models (LLMs) have shown surprising performance in task-specific workloads as well as general tasks with the given prompts. However, to achieve unprecedented performance, recent LLMs use billions to trillions of parameters, which hinder the wide adaptation of those models due to their extremely large compute and memory requirements. To resolve the issue, various model compression methods are being actively investigated. In this work, we propose SDQ (Sparse Decomposed Quantization) to exploit both structured sparsity and quantization to achieve both high compute and memory efficiency. From our evaluations, we observe that SDQ can achieve 4x effective compute throughput with <1% quality drop.
Abstracting Sparse DNN Acceleration via Structured Sparse Tensor Decomposition
Mar 12, 2024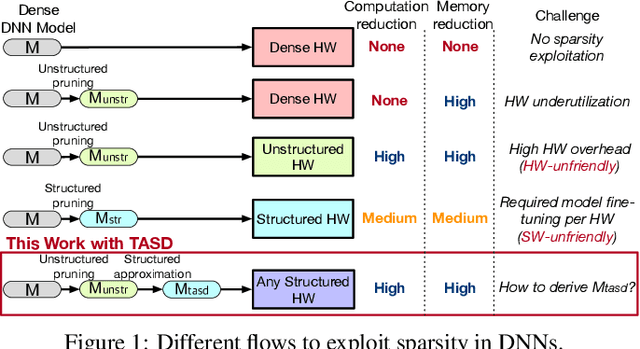
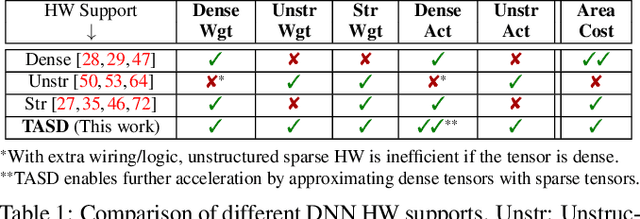
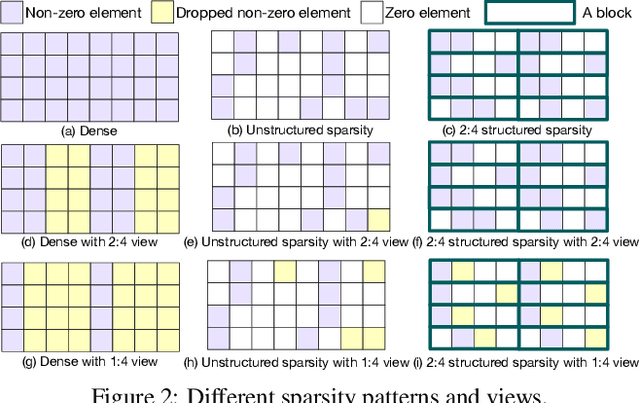
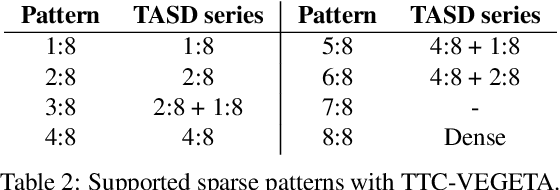
Exploiting sparsity in deep neural networks (DNNs) has been a promising area to meet the growing computation need of modern DNNs. However, in practice, sparse DNN acceleration still faces a key challenge. To minimize the overhead of sparse acceleration, hardware designers have proposed structured sparse hardware support recently, which provides limited flexibility and requires extra model fine-tuning. Moreover, any sparse model fine-tuned for certain structured sparse hardware cannot be accelerated by other structured hardware. To bridge the gap between sparse DNN models and hardware, this paper proposes tensor approximation via structured decomposition (TASD), which leverages the distributive property in linear algebra to turn any sparse tensor into a series of structured sparse tensors. Next, we develop a software framework, TASDER, to accelerate DNNs by searching layer-wise, high-quality structured decomposition for both weight and activation tensors so that they can be accelerated by any systems with structured sparse hardware support. Evaluation results show that, by exploiting prior structured sparse hardware baselines, our method can accelerate off-the-shelf dense and sparse DNNs without fine-tuning and improves energy-delay-product by up to 83% and 74% on average.
VaPr: Variable-Precision Tensors to Accelerate Robot Motion Planning
Oct 11, 2023



High-dimensional motion generation requires numerical precision for smooth, collision-free solutions. Typically, double-precision or single-precision floating-point (FP) formats are utilized. Using these for big tensors imposes a strain on the memory bandwidth provided by the devices and alters the memory footprint, hence limiting their applicability to low-power edge devices needed for mobile robots. The uniform application of reduced precision can be advantageous but severely degrades solutions. Using decreased precision data types for important tensors, we propose to accelerate motion generation by removing memory bottlenecks. We propose variable-precision (VaPr) search optimization to determine the appropriate precision for large tensors from a vast search space of approximately 4 million unique combinations for FP data types across the tensors. To obtain the efficiency gains, we exploit existing platform support for an out-of-the-box GPU speedup and evaluate prospective precision converter units for GPU types that are not currently supported. Our experimental results on 800 planning problems for the Franka Panda robot on the MotionBenchmaker dataset across 8 environments show that a 4-bit FP format is sufficient for the largest set of tensors in the motion generation stack. With the software-only solution, VaPr achieves 6.3% and 6.3% speedups on average for a significant portion of motion generation over the SOTA solution (CuRobo) on Jetson Orin and RTX2080 Ti GPU, respectively, and 9.9%, 17.7% speedups with the FP converter.
Enabling and Accelerating Dynamic Vision Transformer Inference for Real-Time Applications
Dec 06, 2022Many state-of-the-art deep learning models for computer vision tasks are based on the transformer architecture. Such models can be computationally expensive and are typically statically set to meet the deployment scenario. However, in real-time applications, the resources available for every inference can vary considerably and be smaller than what state-of-the-art models use. We can use dynamic models to adapt the model execution to meet real-time application resource constraints. While prior dynamic work has primarily minimized resource utilization for less complex input images while maintaining accuracy and focused on CNNs and early transformer models such as BERT, we adapt vision transformers to meet system dynamic resource constraints, independent of the input image. We find that unlike early transformer models, recent state-of-the-art vision transformers heavily rely on convolution layers. We show that pretrained models are fairly resilient to skipping computation in the convolution and self-attention layers, enabling us to create a low-overhead system for dynamic real-time inference without additional training. Finally, we create a optimized accelerator for these dynamic vision transformers in a 5nm technology. The PE array occupies 2.26mm$^2$ and is 17 times faster than a NVIDIA TITAN V GPU for state-of-the-art transformer-based models for semantic segmentation.
Zhuyi: Perception Processing Rate Estimation for Safety in Autonomous Vehicles
May 06, 2022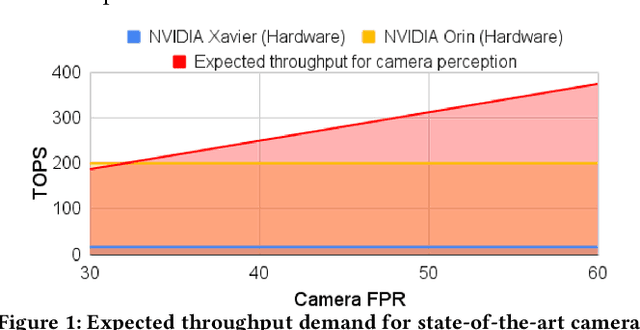
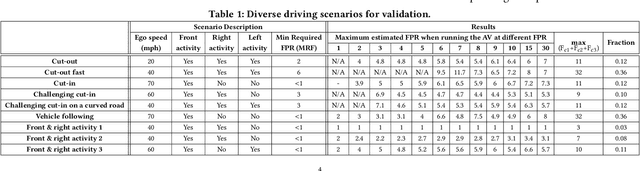
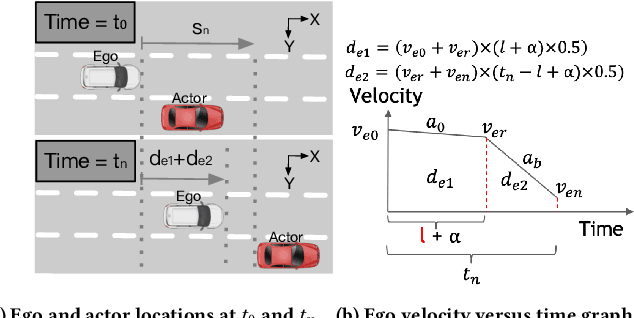
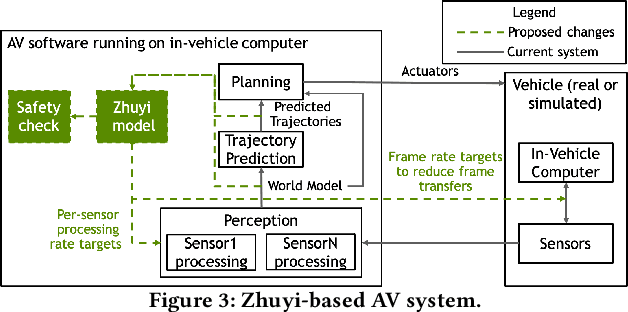
The processing requirement of autonomous vehicles (AVs) for high-accuracy perception in complex scenarios can exceed the resources offered by the in-vehicle computer, degrading safety and comfort. This paper proposes a sensor frame processing rate (FPR) estimation model, Zhuyi, that quantifies the minimum safe FPR continuously in a driving scenario. Zhuyi can be employed post-deployment as an online safety check and to prioritize work. Experiments conducted using a multi-camera state-of-the-art industry AV system show that Zhuyi's estimated FPRs are conservative, yet the system can maintain safety by processing only 36% or fewer frames compared to a default 30-FPR system in the tested scenarios.
GPU Domain Specialization via Composable On-Package Architecture
Apr 05, 2021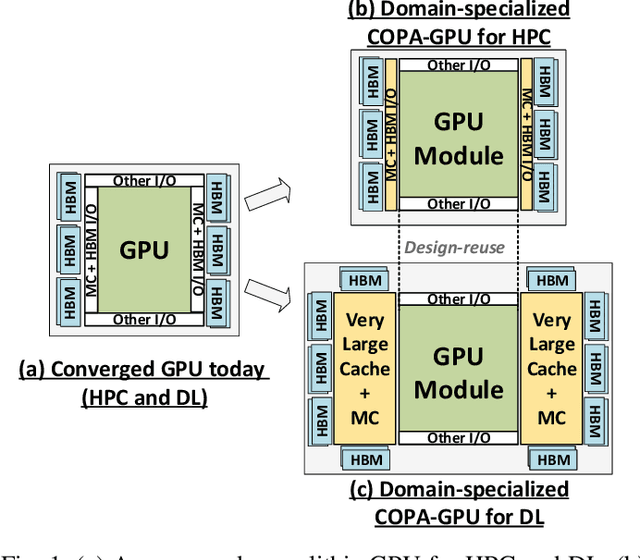
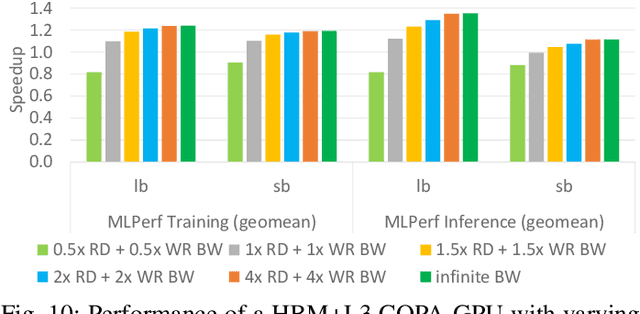
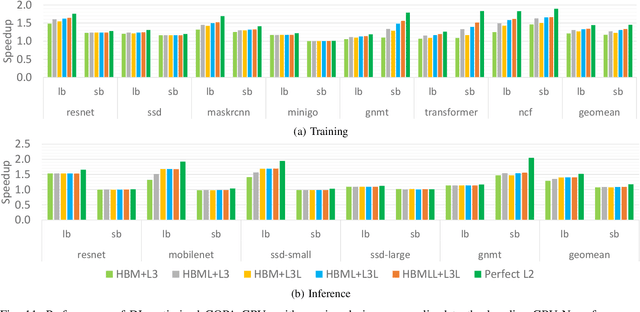
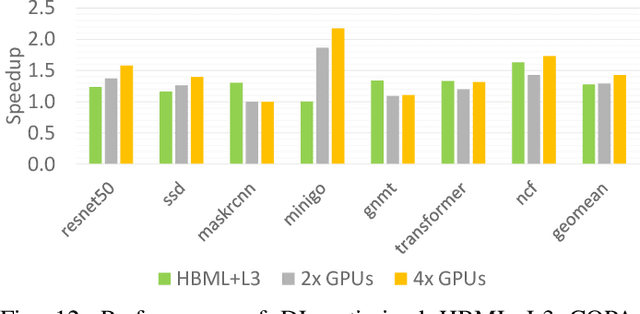
As GPUs scale their low precision matrix math throughput to boost deep learning (DL) performance, they upset the balance between math throughput and memory system capabilities. We demonstrate that converged GPU design trying to address diverging architectural requirements between FP32 (or larger) based HPC and FP16 (or smaller) based DL workloads results in sub-optimal configuration for either of the application domains. We argue that a Composable On-PAckage GPU (COPAGPU) architecture to provide domain-specialized GPU products is the most practical solution to these diverging requirements. A COPA-GPU leverages multi-chip-module disaggregation to support maximal design reuse, along with memory system specialization per application domain. We show how a COPA-GPU enables DL-specialized products by modular augmentation of the baseline GPU architecture with up to 4x higher off-die bandwidth, 32x larger on-package cache, 2.3x higher DRAM bandwidth and capacity, while conveniently supporting scaled-down HPC-oriented designs. This work explores the microarchitectural design necessary to enable composable GPUs and evaluates the benefits composability can provide to HPC, DL training, and DL inference. We show that when compared to a converged GPU design, a DL-optimized COPA-GPU featuring a combination of 16x larger cache capacity and 1.6x higher DRAM bandwidth scales per-GPU training and inference performance by 31% and 35% respectively and reduces the number of GPU instances by 50% in scale-out training scenarios.
Generating and Characterizing Scenarios for Safety Testing of Autonomous Vehicles
Mar 12, 2021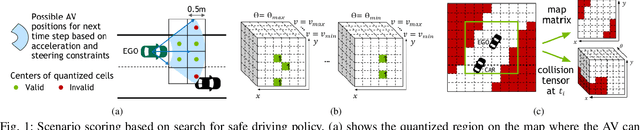
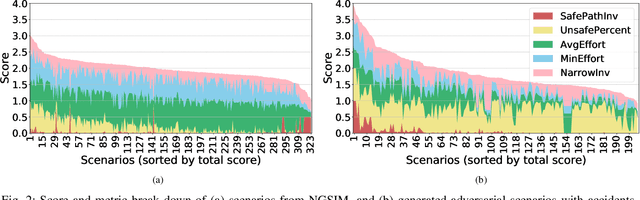
Extracting interesting scenarios from real-world data as well as generating failure cases is important for the development and testing of autonomous systems. We propose efficient mechanisms to both characterize and generate testing scenarios using a state-of-the-art driving simulator. For any scenario, our method generates a set of possible driving paths and identifies all the possible safe driving trajectories that can be taken starting at different times, to compute metrics that quantify the complexity of the scenario. We use our method to characterize real driving data from the Next Generation Simulation (NGSIM) project, as well as adversarial scenarios generated in simulation. We rank the scenarios by defining metrics based on the complexity of avoiding accidents and provide insights into how the AV could have minimized the probability of incurring an accident. We demonstrate a strong correlation between the proposed metrics and human intuition.
Making Convolutions Resilient via Algorithm-Based Error Detection Techniques
Jun 08, 2020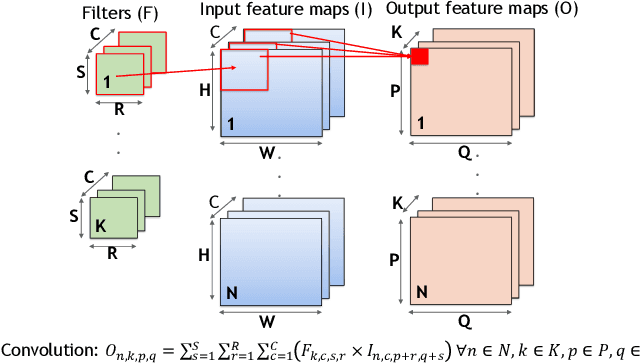
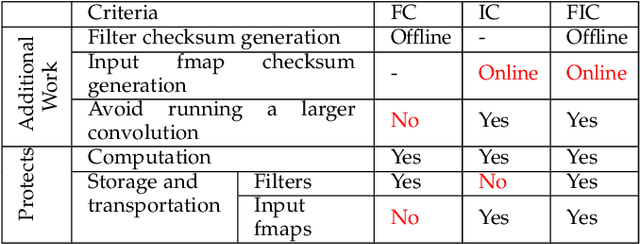
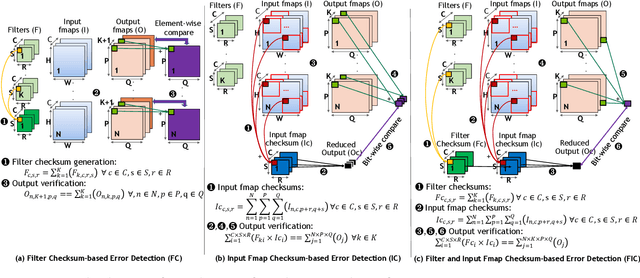

The ability of Convolutional Neural Networks (CNNs) to accurately process real-time telemetry has boosted their use in safety-critical and high-performance computing systems. As such systems require high levels of resilience to errors, CNNs must execute correctly in the presence of hardware faults. Full duplication provides the needed assurance but incurs a prohibitive 100% overhead. Algorithmic techniques are known to offer low-cost solutions, but the practical feasibility and performance of such techniques have never been studied for CNN deployment platforms (e.g., TensorFlow or TensorRT on GPUs). In this paper, we focus on algorithmically verifying Convolutions, which are the most resource-demanding operations in CNNs. We use checksums to verify convolutions, adding a small amount of redundancy, far less than full-duplication. We first identify the challenges that arise in employing Algorithm-Based Error Detection (ABED) for Convolutions in optimized inference platforms that fuse multiple network layers and use reduced-precision operations, and demonstrate how to overcome them. We propose and evaluate variations of ABED techniques that offer implementation complexity, runtime overhead, and coverage trade-offs. Results show that ABED can detect all transient hardware errors that might otherwise corrupt output and does so while incurring low runtime overheads (6-23%), offering at least 1.6X throughput to workloads compared to full duplication.
HarDNN: Feature Map Vulnerability Evaluation in CNNs
Feb 25, 2020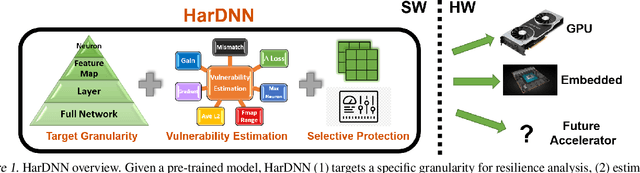
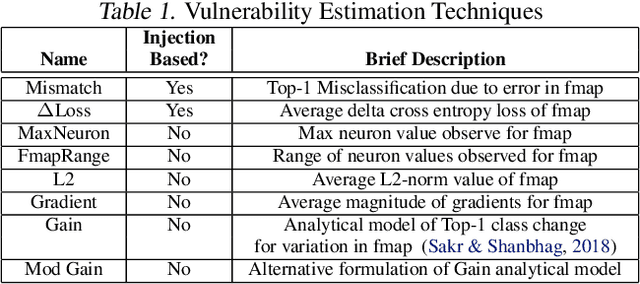
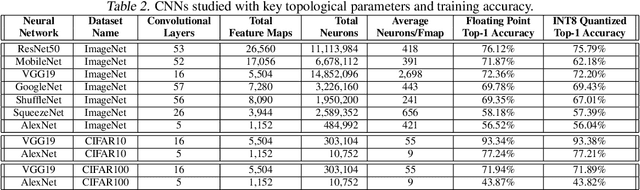
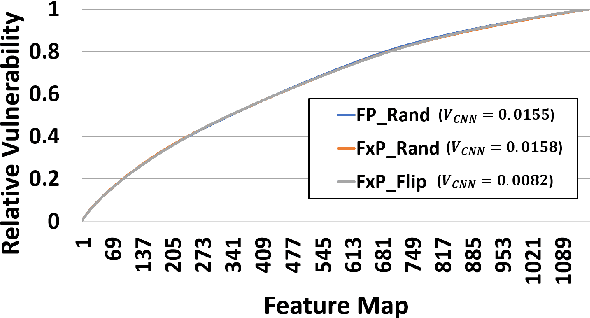
As Convolutional Neural Networks (CNNs) are increasingly being employed in safety-critical applications, it is important that they behave reliably in the face of hardware errors. Transient hardware errors may percolate undesirable state during execution, resulting in software-manifested errors which can adversely affect high-level decision making. This paper presents HarDNN, a software-directed approach to identify vulnerable computations during a CNN inference and selectively protect them based on their propensity towards corrupting the inference output in the presence of a hardware error. We show that HarDNN can accurately estimate relative vulnerability of a feature map (fmap) in CNNs using a statistical error injection campaign, and explore heuristics for fast vulnerability assessment. Based on these results, we analyze the tradeoff between error coverage and computational overhead that the system designers can use to employ selective protection. Results show that the improvement in resilience for the added computation is superlinear with HarDNN. For example, HarDNN improves SqueezeNet's resilience by 10x with just 30% additional computations.
ML-based Fault Injection for Autonomous Vehicles: A Case for Bayesian Fault Injection
Jul 01, 2019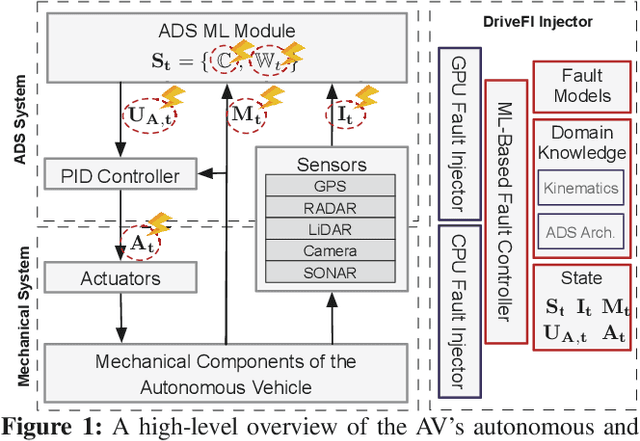
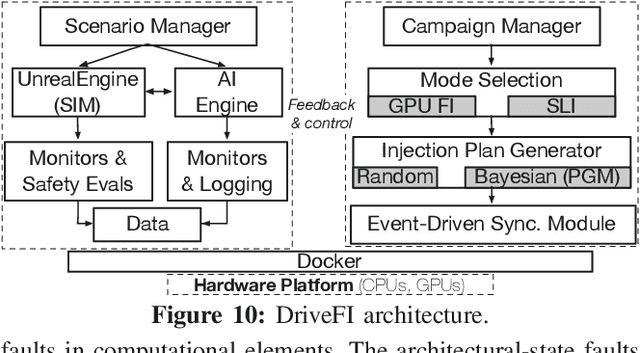
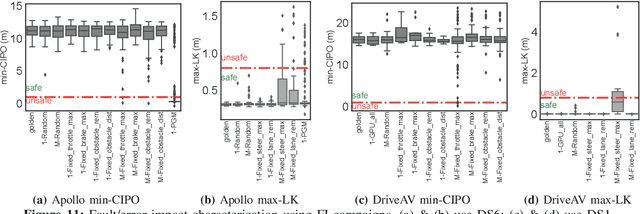
The safety and resilience of fully autonomous vehicles (AVs) are of significant concern, as exemplified by several headline-making accidents. While AV development today involves verification, validation, and testing, end-to-end assessment of AV systems under accidental faults in realistic driving scenarios has been largely unexplored. This paper presents DriveFI, a machine learning-based fault injection engine, which can mine situations and faults that maximally impact AV safety, as demonstrated on two industry-grade AV technology stacks (from NVIDIA and Baidu). For example, DriveFI found 561 safety-critical faults in less than 4 hours. In comparison, random injection experiments executed over several weeks could not find any safety-critical faults