 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU Domain Specialization via Composable On-Package Architecture
Apr 05, 2021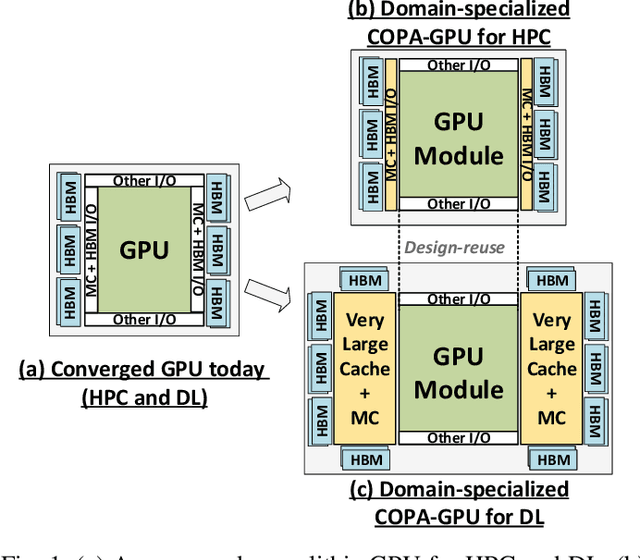
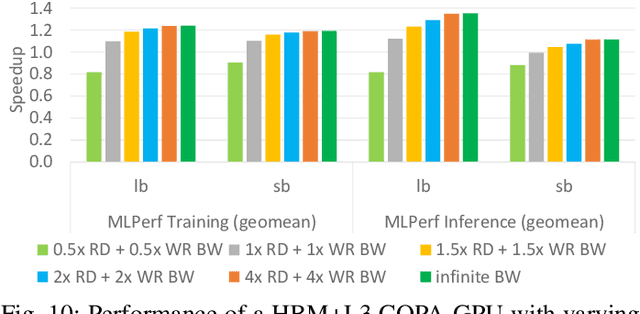
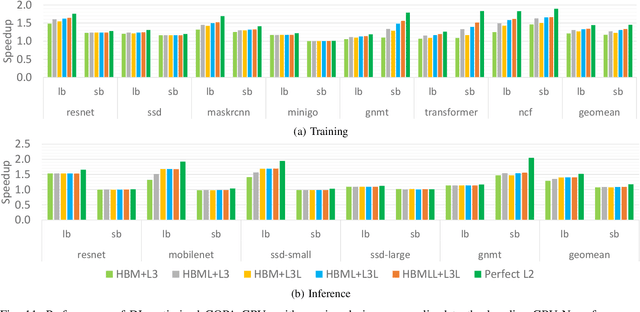
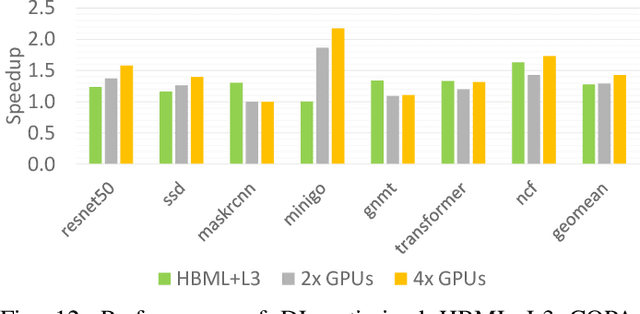
As GPUs scale their low precision matrix math throughput to boost deep learning (DL) performance, they upset the balance between math throughput and memory system capabilities. We demonstrate that converged GPU design trying to address diverging architectural requirements between FP32 (or larger) based HPC and FP16 (or smaller) based DL workloads results in sub-optimal configuration for either of the application domains. We argue that a Composable On-PAckage GPU (COPAGPU) architecture to provide domain-specialized GPU products is the most practical solution to these diverging requirements. A COPA-GPU leverages multi-chip-module disaggregation to support maximal design reuse, along with memory system specialization per application domain. We show how a COPA-GPU enables DL-specialized products by modular augmentation of the baseline GPU architecture with up to 4x higher off-die bandwidth, 32x larger on-package cache, 2.3x higher DRAM bandwidth and capacity, while conveniently supporting scaled-down HPC-oriented designs. This work explores the microarchitectural design necessary to enable composable GPUs and evaluates the benefits composability can provide to HPC, DL training, and DL inference. We show that when compared to a converged GPU design, a DL-optimized COPA-GPU featuring a combination of 16x larger cache capacity and 1.6x higher DRAM bandwidth scales per-GPU training and inference performance by 31% and 35% respectively and reduces the number of GPU instances by 50% in scale-out training scenarios.
The Architectural Implications of Distributed Reinforcement Learning on CPU-GPU Systems
Dec 08, 2020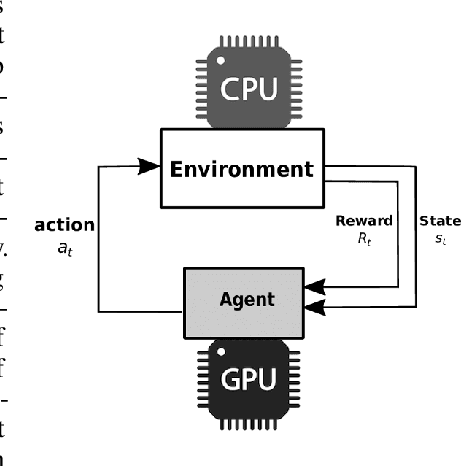
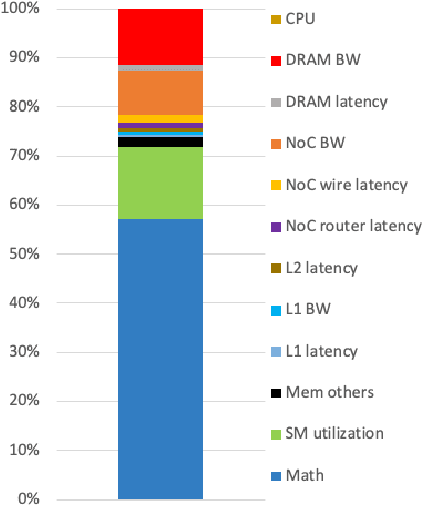
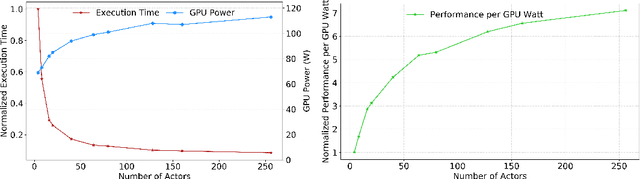
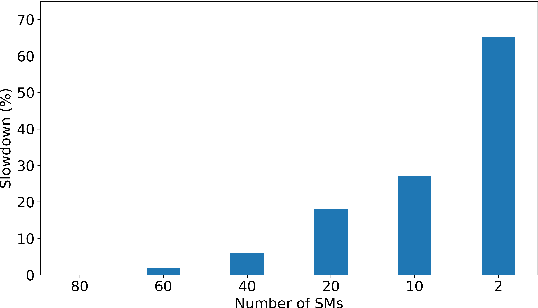
With deep reinforcement learning (RL) methods achieving results that exceed human capabilities in games, robotics, and simulated environments, continued scaling of RL training is crucial to its deployment in solving complex real-world problems. However, improving the performance scalability and power efficiency of RL training through understanding the architectural implications of CPU-GPU systems remains an open problem. In this work we investigate and improve the performance and power efficiency of distributed RL training on CPU-GPU systems by approaching the problem not solely from the GPU microarchitecture perspective but following a holistic system-level analysis approach. We quantify the overall hardware utilization on a state-of-the-art distributed RL training framework and empirically identify the bottlenecks caused by GPU microarchitectural, algorithmic, and system-level design choices. We show that the GPU microarchitecture itself is well-balanced for state-of-the-art RL frameworks, but further investigation reveals that the number of actors running the environment interactions and the amount of hardware resources available to them are the primary performance and power efficiency limiters. To this end, we introduce a new system design metric, CPU/GPU ratio, and show how to find the optimal balance between CPU and GPU resources when designing scalable and efficient CPU-GPU systems for RL training.
Optimizing Multi-GPU Parallelization Strategies for Deep Learning Training
Jul 30, 2019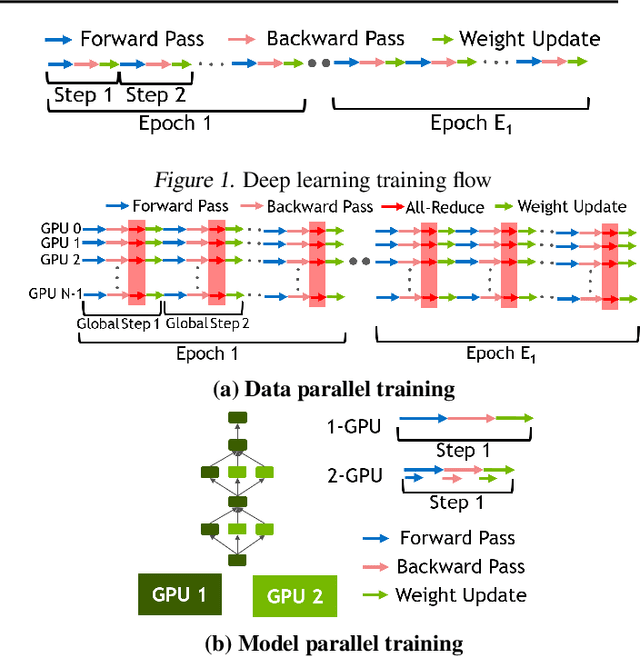

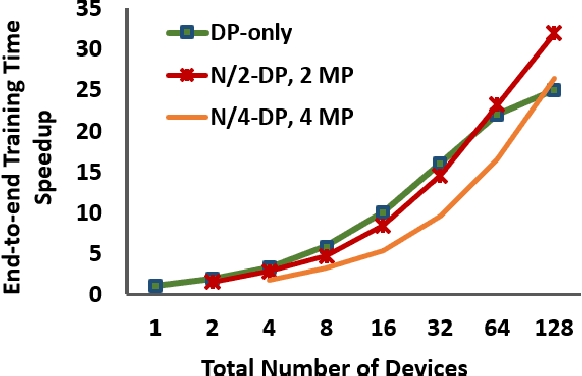
Deploying deep learning (DL) models across multiple compute devices to train large and complex models continues to grow in importance because of the demand for faster and more frequent training. Data parallelism (DP) is the most widely used parallelization strategy, but as the number of devices in data parallel training grows, so does the communication overhead between devices. Additionally, a larger aggregate batch size per step leads to statistical efficiency loss, i.e., a larger number of epochs are required to converge to a desired accuracy. These factors affect overall training time and beyond a certain number of devices, the speedup from leveraging DP begins to scale poorly. In addition to DP, each training step can be accelerated by exploiting model parallelism (MP). This work explores hybrid parallelization, where each data parallel worker is comprised of more than one device, across which the model dataflow graph (DFG) is split using MP. We show that at scale, hybrid training will be more effective at minimizing end-to-end training time than exploiting DP alone. We project that for Inception-V3, GNMT, and BigLSTM, the hybrid strategy provides an end-to-end training speedup of at least 26.5%, 8%, and 22% respectively compared to what DP alone can achieve at scale.