 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Tiered Pruning for Efficient Differentialble Inference-Aware Neural Architecture Search
Oct 03, 2022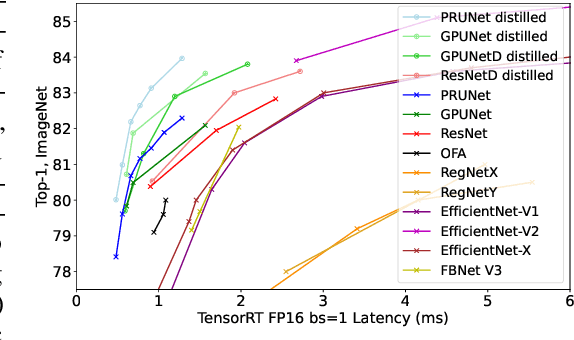
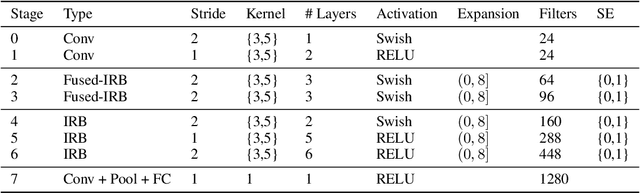
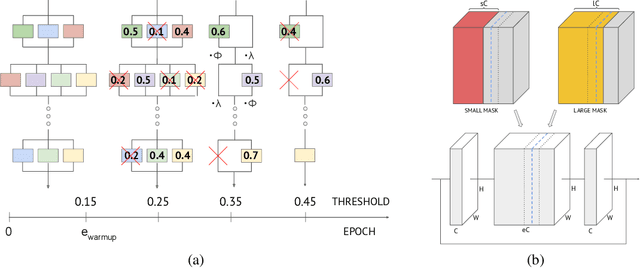
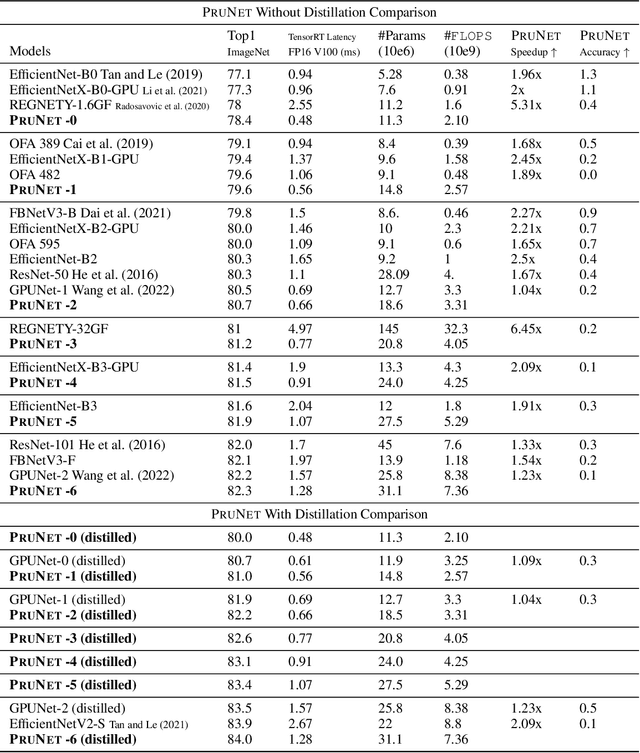
We propose three novel pruning techniques to improve the cost and results of inference-aware Differentiable Neural Architecture Search (DNAS). First, we introduce , a stochastic bi-path building block for DNAS, which can search over inner hidden dimensions with memory and compute complexity. Second, we present an algorithm for pruning blocks within a stochastic layer of the SuperNet during the search. Third, we describe a novel technique for pruning unnecessary stochastic layers during the search. The optimized models resulting from the search are called PruNet and establishes a new state-of-the-art Pareto frontier for NVIDIA V100 in terms of inference latency for ImageNet Top-1 image classification accuracy. PruNet as a backbone also outperforms GPUNet and EfficientNet on the COCO object detection task on inference latency relative to mean Average Precision (mAP).
GPUNet: Searching the Deployable Convolution Neural Networks for GPUs
Apr 26, 2022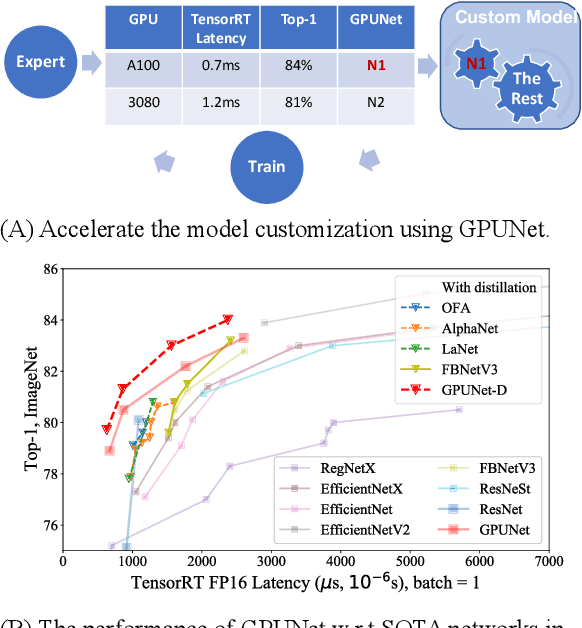
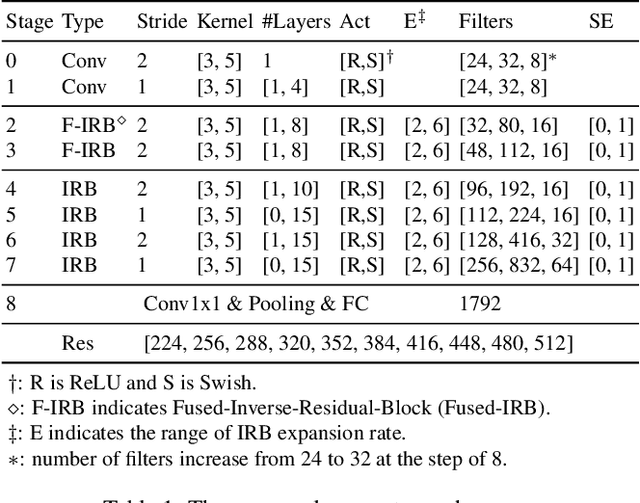
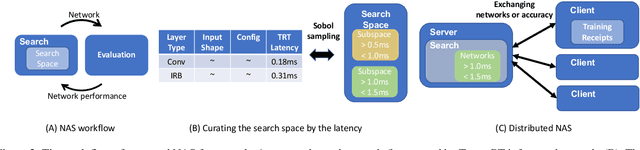

Customizing Convolution Neural Networks (CNN) for production use has been a challenging task for DL practitioners. This paper intends to expedite the model customization with a model hub that contains the optimized models tiered by their inference latency using Neural Architecture Search (NAS). To achieve this goal, we build a distributed NAS system to search on a novel search space that consists of prominent factors to impact latency and accuracy. Since we target GPU, we name the NAS optimized models as GPUNet, which establishes a new SOTA Pareto frontier in inference latency and accuracy. Within 1$ms$, GPUNet is 2x faster than EfficientNet-X and FBNetV3 with even better accuracy. We also validate GPUNet on detection tasks, and GPUNet consistently outperforms EfficientNet-X and FBNetV3 on COCO detection tasks in both latency and accuracy. All of these data validate that our NAS system is effective and generic to handle different design tasks. With this NAS system, we expand GPUNet to cover a wide range of latency targets such that DL practitioners can deploy our models directly in different scenarios.
Pay Attention when Required
Sep 09, 2020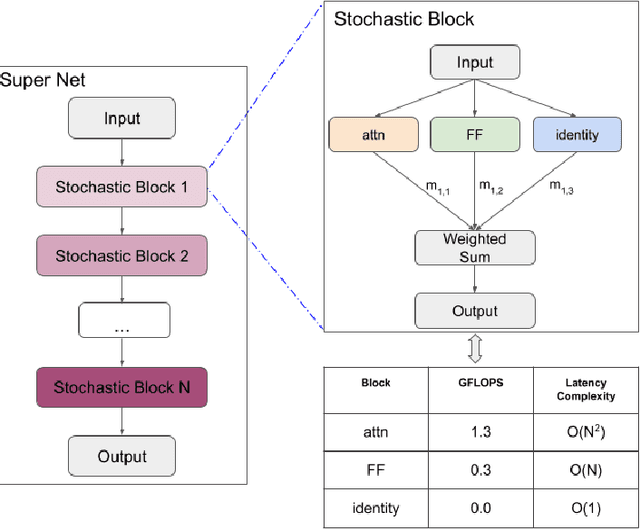
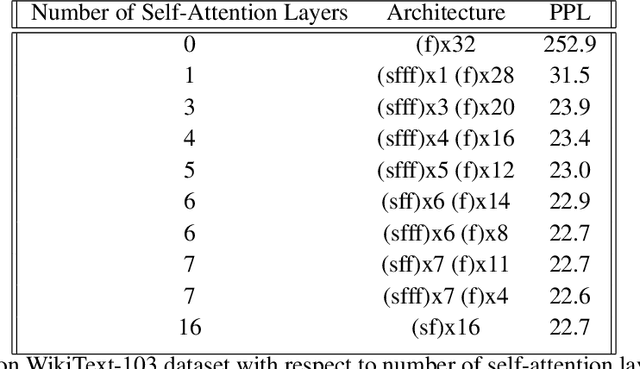


Transformer-based models consist of interleaved feed-forward blocks - that capture content meaning, and relatively more expensive self-attention blocks - that capture context meaning. In this paper, we explored trade-offs and ordering of the blocks to improve upon the current Transformer architecture and proposed PAR Transformer. It needs 35% lower compute time than Transformer-XL achieved by replacing ~63% of the self-attention blocks with feed-forward blocks, and retains the perplexity on WikiText-103 language modelling benchmark. We further validated our results on text8 and enwiki8 datasets, as well as on the BERT model.
Optimizing Multi-GPU Parallelization Strategies for Deep Learning Training
Jul 30, 2019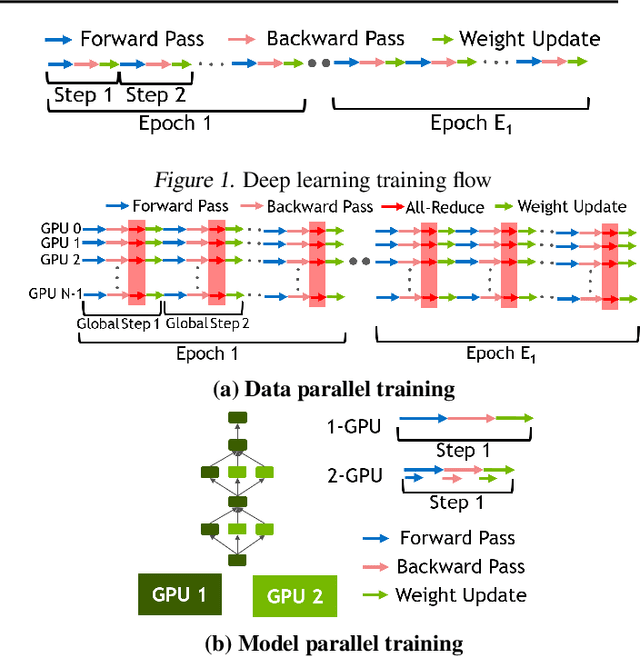

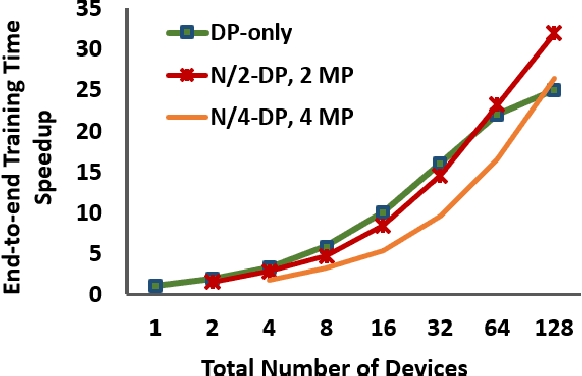
Deploying deep learning (DL) models across multiple compute devices to train large and complex models continues to grow in importance because of the demand for faster and more frequent training. Data parallelism (DP) is the most widely used parallelization strategy, but as the number of devices in data parallel training grows, so does the communication overhead between devices. Additionally, a larger aggregate batch size per step leads to statistical efficiency loss, i.e., a larger number of epochs are required to converge to a desired accuracy. These factors affect overall training time and beyond a certain number of devices, the speedup from leveraging DP begins to scale poorly. In addition to DP, each training step can be accelerated by exploiting model parallelism (MP). This work explores hybrid parallelization, where each data parallel worker is comprised of more than one device, across which the model dataflow graph (DFG) is split using MP. We show that at scale, hybrid training will be more effective at minimizing end-to-end training time than exploiting DP alone. We project that for Inception-V3, GNMT, and BigLSTM, the hybrid strategy provides an end-to-end training speedup of at least 26.5%, 8%, and 22% respectively compared to what DP alone can achieve at scale.
MDFS - MultiDimensional Feature Selection
Oct 31, 2018

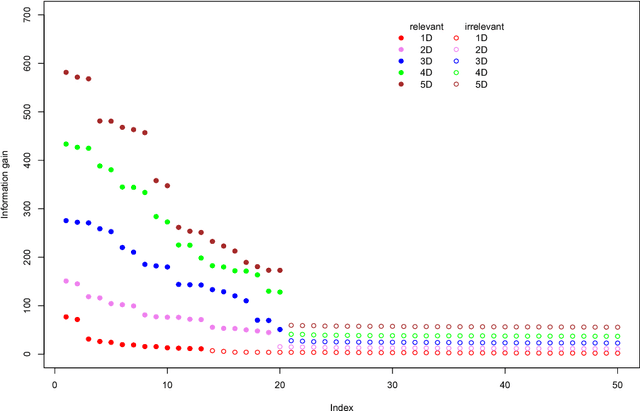

Identification of informative variables in an information system is often performed using simple one-dimensional filtering procedures that discard information about interactions between variables. Such approach may result in removing some relevant variables from consideration. Here we present an R package MDFS (MultiDimensional Feature Selection) that performs identification of informative variables taking into account synergistic interactions between multiple descriptors and the decision variable. MDFS is an implementation of an algorithm based on information theory. Computational kernel of the package is implemented in C++. A high-performance version implemented in CUDA C is also available. The applications of MDFS are demonstrated using the well-known Madelon dataset that has synergistic variables by design. The dataset comes from the UCI Machine Learning Repository. It is shown that multidimensional analysis is more sensitive than one-dimensional tests and returns more reliable rankings of importance.