 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrap Bias Corrected Cross Validation applied to Super Learning
Mar 18, 2020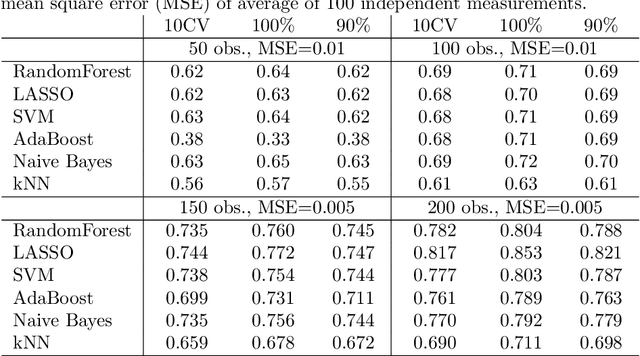

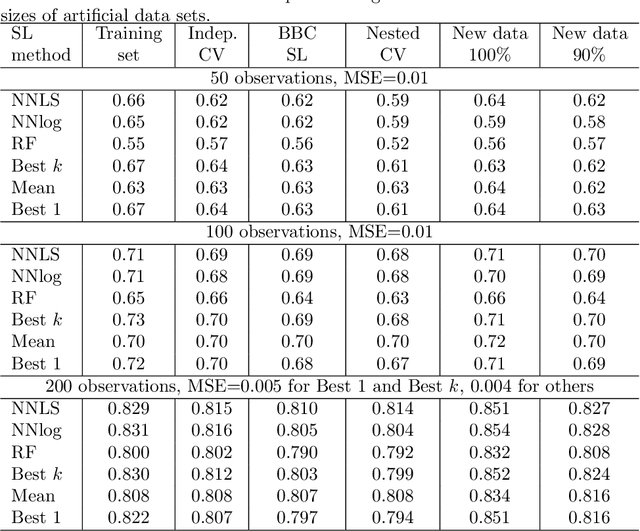

Super learner algorithm can be applied to combine results of multiple base learners to improve quality of predictions. The default method for verification of super learner results is by nested cross validation. It has been proposed by Tsamardinos et al., that nested cross validation can be replaced by resampling for tuning hyper-parameters of the learning algorithms. We apply this idea to verification of super learner and compare with other verification methods, including nested cross validation. Tests were performed on artificial data sets of diverse size and on seven real, biomedical data sets. The resampling method, called Bootstrap Bias Correction, proved to be a reasonably precise and very cost-efficient alternative for nested cross validation.
MDFS - MultiDimensional Feature Selection
Oct 31, 2018

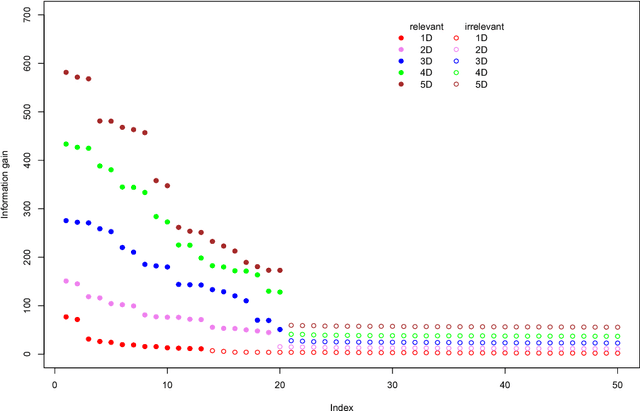

Identification of informative variables in an information system is often performed using simple one-dimensional filtering procedures that discard information about interactions between variables. Such approach may result in removing some relevant variables from consideration. Here we present an R package MDFS (MultiDimensional Feature Selection) that performs identification of informative variables taking into account synergistic interactions between multiple descriptors and the decision variable. MDFS is an implementation of an algorithm based on information theory. Computational kernel of the package is implemented in C++. A high-performance version implemented in CUDA C is also available. The applications of MDFS are demonstrated using the well-known Madelon dataset that has synergistic variables by design. The dataset comes from the UCI Machine Learning Repository. It is shown that multidimensional analysis is more sensitive than one-dimensional tests and returns more reliable rankings of importance.
All-relevant feature selection using multidimensional filters with exhaustive search
May 16, 2017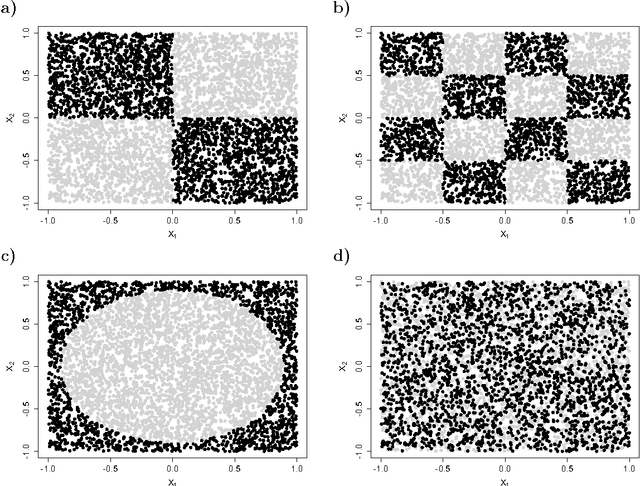
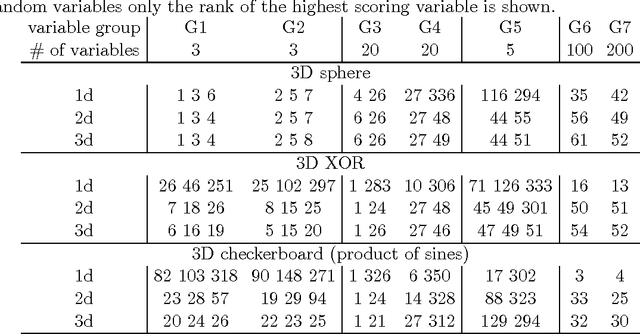


This paper describes a method for identification of the informative variables in the information system with discrete decision variables. It is targeted specifically towards discovery of the variables that are non-informative when considered alone, but are informative when the synergistic interactions between multiple variables are considered. To this end, the mutual entropy of all possible k-tuples of variables with decision variable is computed. Then, for each variable the maximal information gain due to interactions with other variables is obtained. For non-informative variables this quantity conforms to the well known statistical distributions. This allows for discerning truly informative variables from non-informative ones. For demonstration of the approach, the method is applied to several synthetic datasets that involve complex multidimensional interactions between variables. It is capable of identifying most important informative variables, even in the case when the dimensionality of the analysis is smaller than the true dimensionality of the problem. What is more, the high sensitivity of the algorithm allows for detection of the influence of nuisance variables on the response variable.