 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-relevant feature selection using multidimensional filters with exhaustive search
Paper and Code
May 16, 2017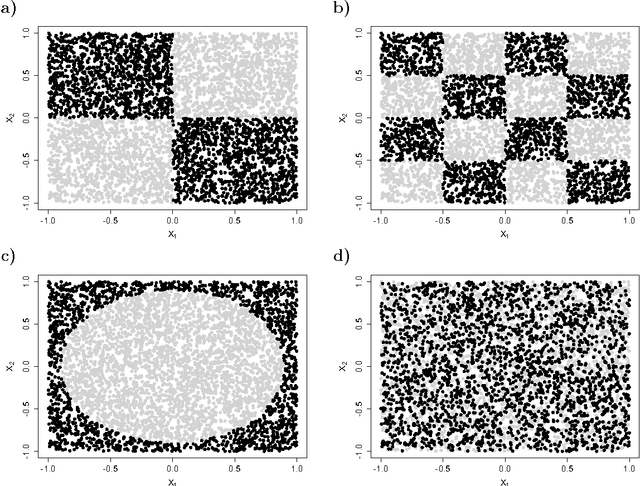
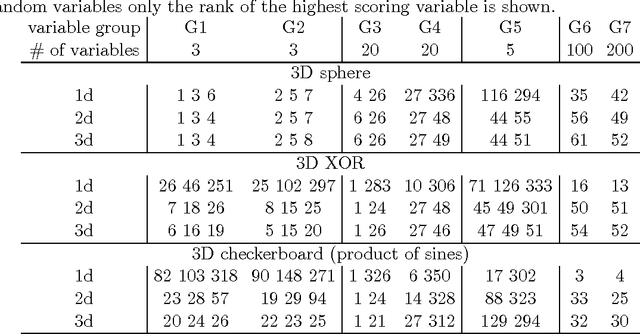


This paper describes a method for identification of the informative variables in the information system with discrete decision variables. It is targeted specifically towards discovery of the variables that are non-informative when considered alone, but are informative when the synergistic interactions between multiple variables are considered. To this end, the mutual entropy of all possible k-tuples of variables with decision variable is computed. Then, for each variable the maximal information gain due to interactions with other variables is obtained. For non-informative variables this quantity conforms to the well known statistical distributions. This allows for discerning truly informative variables from non-informative ones. For demonstration of the approach, the method is applied to several synthetic datasets that involve complex multidimensional interactions between variables. It is capable of identifying most important informative variables, even in the case when the dimensionality of the analysis is smaller than the true dimensionality of the problem. What is more, the high sensitivity of the algorithm allows for detection of the influence of nuisance variables on the response variable.